|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Appunti delle lezioni, cheat sheet
Informatica e tecnologie dell'informazione. Cheat sheet: in breve, il più importante
Elenco / Appunti delle lezioni, cheat sheet Sommario
1. Informatica. Informazione Rappresentazione ed elaborazione/informazione. Sistemi numerici L'informatica è impegnata in una rappresentazione formalizzata degli oggetti e delle strutture delle loro relazioni in vari campi della scienza, della tecnologia e della produzione. Vari strumenti formali vengono utilizzati per modellare oggetti e fenomeni, come formule logiche, strutture dati, linguaggi di programmazione, ecc. In informatica, un concetto fondamentale come l'informazione ha diversi significati: 1) presentazione formale di forme informative esterne; 2) significato astratto dell'informazione, suo contenuto interno, semantica; 3) relazione dell'informazione con il mondo reale. Ma, di regola, l'informazione è intesa come il suo significato astratto: la semantica. Se vogliamo scambiare informazioni, abbiamo bisogno di punti di vista coerenti in modo che la correttezza dell'interpretazione non venga violata. Per fare ciò, l'interpretazione della rappresentazione delle informazioni viene identificata con alcune strutture matematiche. In questo caso, l'elaborazione delle informazioni può essere eseguita con metodi matematici rigorosi. Una delle descrizioni matematiche dell'informazione è la sua rappresentazione come funzione y = f(x,t) dov'è il momento, x è un punto in un campo in cui viene misurato il valore di y. A seconda dei parametri di funzione x e t, le informazioni possono essere classificate. Se i parametri sono grandezze scalari che assumono una serie continua di valori, l'informazione così ottenuta viene chiamata continua (o analogica). Se ai parametri viene assegnato un determinato passaggio di modifica, le informazioni vengono chiamate discrete. Le informazioni discrete sono considerate universali. L'informazione discreta è solitamente identificata con l'informazione digitale, che è un caso speciale di informazione simbolica di rappresentazione alfabetica. Un alfabeto è un insieme finito di simboli di qualsiasi natura. Molto spesso in informatica si verifica una situazione in cui i caratteri di un alfabeto devono essere rappresentati dai caratteri di un altro, cioè per effettuare un'operazione di codifica. Come ha dimostrato la pratica, l'alfabeto più semplice che consente di codificare altri alfabeti è binario, composto da due caratteri, che di solito sono indicati con 0 e 1. Usando n caratteri dell'alfabeto binario, puoi codificare 2n caratteri, e questo è sufficiente per codificare qualsiasi alfabeto. Il valore che può essere rappresentato da un simbolo dell'alfabeto binario è chiamato unità minima di informazione o bit. Sequenza di 8 bit - byte. Un alfabeto contenente 256 diverse sequenze a 8 bit è chiamato alfabeto di byte. Un sistema numerico è un insieme di regole per la denominazione e la scrittura di numeri. Esistono sistemi numerici posizionali e non posizionali. Il sistema numerico è chiamato posizionale se il valore della cifra del numero dipende dalla posizione della cifra nel numero. In caso contrario, è chiamato non posizionale. Il valore di un numero è determinato dalla posizione di queste cifre nel numero. 2. Rappresentazione di numeri in un computer. Concetto formalizzato di algoritmo I processori a 32 bit possono funzionare con un massimo di 232-1 RAM e gli indirizzi possono essere scritti nell'intervallo 00000000 - FFFFFFFF. Tuttavia, in modalità reale, il processore funziona con memoria fino a 220-1 e gli indirizzi rientrano nell'intervallo 00000 - FFFFF. I byte di memoria possono essere combinati in campi di lunghezza sia fissa che variabile. Una parola è un campo di lunghezza fissa composto da 2 byte, una doppia parola è un campo di 4 byte. Gli indirizzi di campo possono essere pari o dispari, con gli indirizzi pari che eseguono operazioni più velocemente. I numeri a virgola fissa sono rappresentati nei computer come numeri binari interi e la loro dimensione può essere 1, 2 o 4 byte. I numeri binari interi sono rappresentati in complemento a due. Il codice del complemento di un numero positivo è uguale al numero stesso e il codice del complemento di un numero negativo può essere ottenuto usando la seguente formula: x = 10n - \x\, dove n è la profondità in bit del numero. Nel sistema dei numeri binari, un codice aggiuntivo si ottiene invertendo i bit, ovvero sostituendo le unità con zeri e viceversa, e aggiungendo uno al bit meno significativo. Il numero di bit della mantissa determina la precisione della rappresentazione dei numeri, il numero di bit dell'ordine macchina determina l'intervallo di rappresentazione dei numeri in virgola mobile. Concetto formalizzato di algoritmo Un algoritmo può esistere solo se, allo stesso tempo, esiste un oggetto matematico. Il concetto formalizzato di algoritmo è connesso con il concetto di funzioni ricorsive, normali algoritmi di Markov, macchine di Turing. In matematica, una funzione è chiamata a valore singolo se, per qualsiasi insieme di argomenti, esiste una legge in base alla quale viene determinato un valore univoco della funzione. Un algoritmo può agire come tale; in questo caso la funzione si dice calcolabile. Le funzioni ricorsive sono una sottoclasse di funzioni calcolabili e gli algoritmi che definiscono il calcolo sono chiamati algoritmi di funzione ricorsiva complementare. In primo luogo, vengono fissate le funzioni ricorsive di base, per le quali l'algoritmo di accompagnamento è banale, non ambiguo; quindi vengono introdotte tre regole: operatori di sostituzione, ricorsione e minimizzazione, con l'aiuto dei quali si ottengono funzioni ricorsive più complesse sulla base di funzioni di base. Le funzioni di base e gli algoritmi di accompagnamento possono essere: 1) una funzione di n variabili indipendenti, identicamente uguale a zero. Quindi, se il segno della funzione è φn, allora indipendentemente dal numero di argomenti, il valore della funzione dovrebbe essere posto uguale a zero; 2) una funzione identica di n variabili indipendenti della forma Ψ ni. Quindi, se il segno della funzione è Ψ ni, allora il valore della funzione dovrebbe essere preso come valore dell'i-esimo argomento, contando da sinistra a destra; 3) Funzione λ di un argomento indipendente. Quindi, se il segno della funzione è λ, allora il valore della funzione dovrebbe essere preso come il valore che segue il valore dell'argomento. 3. Introduzione al linguaggio Pascal I simboli di base della lingua - lettere, numeri e caratteri speciali - costituiscono il suo alfabeto. Il linguaggio Pascal include il seguente insieme di simboli di base: 1) 26 lettere minuscole latine e 26 lettere maiuscole latine: 2) _ (sottolineatura); 3) 10 cifre: 0 1 2 3 4 5 6 7 8 9; 4) segni di operazioni: + - O / = <> < > <= >= := @; 5) delimitatori:., ( ) [ ] (..) { } (* *).. : ; 6) identificatori: ^ # $; 7) parole di servizio (riservate): ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNZIONE, GOTO, IF, IMPLEMENTATION, IN, INDEX, HERITED, INLINE, INTERFACE, INTERRUPT, LABEL, LIBRERY, MOD, NAME, NIL, NEAR, NOT, OBJECT, OF, OR, PACKED, PRIVATE, PROCEDURE, PROGRAMMA, PUBBLICO, REGISTRAZIONE, RIPETIZIONE, RESIDENTE, IMPOSTAZIONE, SHL, SHR, STRING, THEN, TO, TYPE, UNIT, UNTIL, USI, VAR, VIRTUALE, WHILE, CON, XOR. Oltre a quelli elencati, l'insieme dei caratteri di base comprende uno spazio. C'è una regola in Pascal: il tipo è esplicitamente specificato nella dichiarazione di una variabile o di una funzione che ne precede l'uso. Il concetto di tipo Pascal ha le seguenti proprietà principali: 1) qualsiasi tipo di dato definisce un insieme di valori a cui appartiene una costante, che può assumere una variabile o un'espressione, oppure può produrre un'operazione o una funzione; 2) il tipo di valore dato da una costante, variabile o espressione può essere determinato dalla loro forma o descrizione; 3) ogni operazione o funzione richiede argomenti di tipo fisso e produce un risultato di tipo fisso. Esistono tipi di dati scalari e strutturati in Pascal. I tipi scalari includono tipi standard e tipi definiti dall'utente. I tipi standard includono i tipi intero, reale, carattere, booleano e indirizzo. I tipi interi definiscono costanti, variabili e funzioni i cui valori sono realizzati dall'insieme di numeri interi consentiti in un determinato computer. Pascal ha la seguente precedenza di operatore:
1) calcoli tra parentesi; 2) calcolo dei valori delle funzioni; 3) operazioni unarie; 4) operazioni */div mod e; 5) operazioni + - o xor; 6) operazioni di relazione = <> < > <= >=. 4. Procedure e funzioni standard Funzioni aritmetiche 1. Funzione Abs(X); restituisce il valore assoluto del parametro. 2. Funzione ArcTan(X: Esteso): Esteso; restituisce l'arcotangente dell'argomento. 3. Funzione Exp(X: Reale): Reale; restituisce l'esponente. 4.Frac(X: Reale): Reale; restituisce la parte frazionaria dell'argomento. 5. Funzione Int(X: Reale): Reale; restituisce la parte intera dell'argomento. 6. Funzione Ln(X: Reale): Reale; restituisce il logaritmo naturale (Ln e = 1) di un'espressione di tipo reale x. 7. Funzione Pi: Estesa; restituisce il valore Pi, che è definito come 3.1415926535. 8.Funzione Sin(X: Esteso): Esteso; restituisce il seno dell'argomento. 9. Funzione Sqr(X: Esteso): Esteso; restituisce il quadrato dell'argomento. 10.Funzione Sqrt(X: Esteso): Esteso; restituisce la radice quadrata dell'argomento. Procedure e funzioni di conversione del valore 1. Procedura Str(X [: Larghezza [: Decimali]]; var S); converte il numero X in una rappresentazione di stringa. 2. Funzione Chr(X: Byte): Char; restituisce il carattere con numero di indice x nella tabella ASCII. 3.Funzione alta (X); restituisce il valore più grande nell'intervallo del parametro. 4.FunzioneBasso(X); restituisce il valore più piccolo nell'intervallo del parametro. 5.Funzione Ord(X): LongInt; restituisce il valore ordinale di un'espressione di tipo enumerato. 6. Funzione Round(X: Esteso): LongInt; arrotonda un valore reale a un numero intero. 7. Funzione Trunc(X: Esteso): LongInt; tronca un valore di tipo reale a un numero intero. 8. Procedura Val(S; var V; var Codice: Intero); converte un numero da un valore stringa S in una rappresentazione numerica V. Procedure e funzioni del valore ordinale 1. Procedura Dec(var X [; N: LongInt]); sottrae uno o N dalla variabile X. 2. Procedure Inc(var X [; N: LongInt]); aggiunge uno o N alla variabile X. 3. Funzione Odd(X: LongInt): Boolean; restituisce True se X è un numero dispari, False in caso contrario. 4.FunzionePred(X); restituisce il valore precedente del parametro. 5 Funzione Succ(X); restituisce il valore del parametro successivo. 5. Operatori linguistici Pascal Operatore condizionale Il formato di una dichiarazione condizionale completa è definito come segue: Se B allora S1 altrimenti S2 dove B è una condizione di ramificazione (decisionale), un'espressione logica o una relazione; S1, S2 - un'istruzione eseguibile, semplice o composta. Quando si esegue un'istruzione condizionale, prima viene valutata l'espressione B, quindi viene analizzato il suo risultato: se B è vero, viene eseguita l'istruzione S1 - il ramo di allora e l'istruzione S2 viene saltata; se B è falso, l'istruzione S2 - viene eseguito il ramo else e l'istruzione S1 viene saltata. Seleziona istruzione La struttura dell'operatore è la seguente: caso S di c1: istruzione1; c2: istruzione2; ... cn: istruzioneN; altra istruzione fine; dove S è un'espressione di tipo ordinale il cui valore viene calcolato; c1, c2,..., on - costanti di tipo ordinale con cui vengono confrontate le espressioni S; istruzionel,..., istruzioneN - operatori di cui viene eseguito quello la cui costante corrisponde al valore dell'espressione S; istruzione - un operatore che viene eseguito se il valore dell'espressione S non corrisponde a nessuna delle costanti c1, o2, on. Istruzione di ciclo con parametro Quando l'istruzione for inizia l'esecuzione, i valori di inizio e fine vengono determinati una volta e questi valori vengono mantenuti durante l'esecuzione dell'istruzione for. L'istruzione contenuta nel corpo dell'istruzione for viene eseguita una volta per ogni valore nell'intervallo tra i valori di inizio e di fine. Il contatore di loop viene sempre inizializzato su un valore iniziale. Istruzione di ciclo con precondizione Mentre B fa S; dove B è una condizione logica, la cui verità è verificata (è una condizione per terminare il ciclo)$; S - corpo del ciclo - una dichiarazione. L'espressione che controlla la ripetizione di un'istruzione deve essere di tipo Boolean. Viene valutato prima dell'esecuzione dell'istruzione interna. L'istruzione interna viene rieseguita finché l'espressione restituisce Trie. Se l'espressione restituisce False dall'inizio, l'istruzione contenuta nell'istruzione del ciclo di precondizione non viene eseguita. Istruzione di ciclo con postcondizione ripetere S fino a B; dove B è una condizione logica, la cui verità è verificata (è una condizione per terminare il ciclo); S - una o più istruzioni del corpo del ciclo. Il risultato dell'espressione deve essere di tipo booleano. Le istruzioni racchiuse tra le parole chiave repeat e until vengono eseguite in sequenza finché il risultato dell'espressione non restituisce True. La sequenza di istruzioni verrà eseguita almeno una volta, poiché l'espressione viene valutata dopo ogni esecuzione della sequenza di istruzioni. 6. Il concetto di algoritmo ausiliario L'algoritmo di risoluzione dei problemi è progettato scomponendo l'intero problema in sottoattività separate. In genere, le attività secondarie vengono implementate come subroutine. Una subroutine è un algoritmo ausiliario che viene utilizzato ripetutamente nell'algoritmo principale con valori diversi di alcune quantità in ingresso, chiamate parametri. Una subroutine nei linguaggi di programmazione è una sequenza di istruzioni che sono definite e scritte in un solo punto del programma, ma possono essere richiamate per l'esecuzione da uno o più punti del programma. Ogni subroutine è identificata da un nome univoco. Ci sono due tipi di subroutine in Pascal, procedure e funzioni. Una procedura e una funzione sono una sequenza denominata di dichiarazioni e istruzioni. Quando si utilizzano procedure o funzioni, il programma deve contenere il testo della procedura o funzione e una chiamata alla procedura o funzione. I parametri specificati nella descrizione sono detti formali, quelli specificati nella chiamata al sottoprogramma sono detti effettivi. Tutti i parametri formali possono essere suddivisi nelle seguenti categorie: 1) parametri-variabili; 2) parametri costanti; 3) valori-parametro; 4) parametri di procedura e parametri di funzione, ovvero parametri di tipo procedurale; 5) parametri variabili non tipizzati. I testi delle procedure e delle funzioni sono inseriti nelle descrizioni delle procedure e delle funzioni. Passare nomi di procedure e funzioni come parametri In molti problemi, specialmente in matematica computazionale, è necessario passare come parametri i nomi di procedure e funzioni. Per fare ciò, TURBO PASCAL ha introdotto un nuovo tipo di dati - procedurali o funzionali, a seconda di quanto descritto. (I tipi procedurali e di funzione sono descritti nella sezione relativa alla dichiarazione del tipo.) Una funzione e un tipo procedurale sono definiti come l'intestazione di una procedura e una funzione con un elenco di parametri formali ma senza nome. È possibile definire una funzione o un tipo procedurale senza parametri, ad esempio: Digitare Proc = procedura; Dopo aver dichiarato un tipo procedurale o funzionale, può essere utilizzato per descrivere parametri formali: i nomi di procedure e funzioni. Inoltre, è necessario scrivere quelle procedure o funzioni reali i cui nomi verranno passati come parametri effettivi. 7. Procedure e funzioni in Pascal Procedure in Pascal La descrizione della procedura è composta da un'intestazione e un blocco, che, fatta eccezione per la sezione di connessione del modulo, non differiscono dal blocco di programma. L'intestazione è costituita dalla parola chiave Procedure, dal nome della procedura e da un elenco opzionale di parametri formali tra parentesi: Procedura <nome> [(<elenco dei parametri formali>)]; Per ogni parametro formale è necessario definirne il tipo. I gruppi di parametri in una descrizione di procedura sono separati da punto e virgola. La struttura della procedura è quasi completamente simile al programma. Tuttavia, non esiste una sezione di connessione del modulo nel blocco della procedura. Il blocco si compone di due parti: descrittiva ed esecutiva. La parte descrittiva contiene una descrizione degli elementi della procedura. E nella parte esecutiva sono indicate le azioni con gli elementi di programma a disposizione della procedura (ad esempio variabili globali e costanti), che consentono di ottenere il risultato richiesto. La sezione delle istruzioni di una procedura differisce dalla sezione delle istruzioni di un programma solo per il fatto che la parola chiave End che termina la sezione è seguita da un punto e virgola anziché da un punto. Un'istruzione di chiamata di procedura viene utilizzata per chiamare una procedura. Consiste nel nome della procedura e in un elenco di argomenti racchiusi tra parentesi. Le istruzioni da eseguire quando viene eseguita la procedura sono contenute nella parte relativa alle istruzioni del modulo della procedura. A volte si desidera che una procedura si chiami. Questo modo di chiamare è chiamato ricorsione. La ricorsione è utile nei casi in cui l'attività principale può essere suddivisa in sottoattività, ognuna delle quali è implementata secondo un algoritmo che coincide con quello principale. Funzioni in Pascal Una dichiarazione di funzione definisce la parte del programma in cui il valore viene calcolato e restituito. Una descrizione di funzione è composta da un'intestazione e un blocco. L'intestazione contiene la parola chiave Function, il nome della funzione, un elenco facoltativo di parametri formali racchiusi tra parentesi e il tipo restituito della funzione. La forma generale dell'intestazione della funzione è la seguente: Funzione <nome> [(<elenco dei parametri formali>)]: <tipo di restituzione>; Nell'implementazione Borland di Turbo Pascal 7.0, il valore di ritorno di una funzione non può essere di tipo composito. E il linguaggio Object Pascal utilizzato negli ambienti di sviluppo integrato Borland Delphi consente qualsiasi tipo di risultato di ritorno, ad eccezione del tipo di file. Un blocco funzione è un blocco locale, simile nella struttura a un blocco procedura. Il corpo di una funzione deve contenere almeno un'istruzione di assegnazione, sul lato sinistro della quale c'è il nome della funzione. È lei che determina il valore restituito dalla funzione. Se sono presenti diverse istruzioni di questo tipo, il risultato della funzione sarà il valore dell'ultima istruzione di assegnazione eseguita. La funzione viene attivata quando la funzione viene chiamata. Quando viene chiamata una funzione, vengono specificati l'identificatore della funzione e tutti i parametri necessari per valutare la funzione. Una chiamata di funzione può essere inclusa nelle espressioni come operando. Quando l'espressione viene valutata, la funzione viene eseguita e il valore dell'operando diventa il valore restituito dalla funzione. La parte operatore del blocco funzione specifica le istruzioni che devono essere eseguite quando la funzione viene attivata. Un modulo deve contenere almeno un'istruzione di assegnazione che assegna un valore a un identificatore di funzione. Il risultato della funzione è l'ultimo valore assegnato. Se non esiste una tale istruzione di assegnazione, o se non è stata eseguita, il valore di ritorno della funzione non è definito. Se viene utilizzato un identificatore di funzione quando si chiama una funzione all'interno di un modulo, una funzione, la funzione viene eseguita in modo ricorsivo. 8. Descrizioni in avanti e collegamento di subroutine. Direttiva Un programma può contenere più subroutine, cioè la struttura del programma può essere complicata. Tuttavia, queste subroutine possono trovarsi allo stesso livello di annidamento, quindi deve venire prima la dichiarazione di subroutine e quindi la chiamata ad essa, a meno che non venga utilizzata una speciale dichiarazione di inoltro. Una dichiarazione di procedura che contiene una direttiva forward invece di un blocco di istruzioni è chiamata dichiarazione forward. Da qualche parte dopo questa dichiarazione, una procedura deve essere definita da una dichiarazione di definizione. Una dichiarazione di definizione è quella che utilizza lo stesso identificatore di procedura ma omette l'elenco dei parametri formali e include un blocco di istruzioni. La dichiarazione anticipata e la dichiarazione di definizione devono comparire nella stessa parte della procedura e nelle dichiarazioni di funzione. Tra di loro possono essere dichiarate altre procedure e funzioni che possono fare riferimento alla procedura di dichiarazione anticipata. Pertanto, è possibile la ricorsione reciproca. La forward description e la definizione di definizione sono la descrizione completa della procedura. La procedura si considera descritta utilizzando una descrizione anticipata. Se il programma contiene molte subroutine, il programma cesserà di essere visivo, sarà difficile navigare al suo interno. Per evitare ciò, alcune routine vengono memorizzate come file sorgente su disco e, se necessario, vengono collegate al programma principale in fase di compilazione tramite una direttiva di compilazione. Una direttiva è un commento speciale che può essere inserito ovunque in un programma, dove può trovarsi un commento normale. Si differenziano però per il fatto che la direttiva ha una notazione speciale: subito dopo la parentesi chiusa, senza spazio, viene scritto il segno $, e poi, sempre senza spazio, viene indicata la direttiva. Esempio: 1) {$E+} - emula il coprocessore matematico; 2) {$F+} - forma il tipo lontano di procedure e funzioni di chiamata; 3) {$N+} - usa il coprocessore matematico; 4) {$R+} - controlla se gli intervalli sono fuori limite. Alcune opzioni di compilazione possono contenere un parametro, ad esempio: {$I file name}: include il file denominato nel testo del programma compilato 9. Parametri del sottoprogramma La descrizione di una procedura o funzione specifica un elenco di parametri formali. Ciascun parametro dichiarato in un elenco di parametri formale è locale alla procedura o funzione descritta e può essere referenziato dal suo identificatore nel modulo associato a quella procedura o funzione. Esistono tre tipi di parametri: valore, variabile e variabile non tipizzata. Sono caratterizzati come segue: 1. Un gruppo di parametri senza una parola chiave precedente è un elenco di parametri di valore. 2. Un gruppo di parametri preceduto dalla parola chiave const e seguito da un tipo è un elenco di parametri costanti. 3. Un gruppo di parametri preceduto dalla parola chiave var e seguito da un tipo è un elenco di parametri variabili. Parametri di valore Un parametro di valore formale viene trattato come una variabile locale alla procedura o funzione, tranne per il fatto che ottiene il suo valore iniziale dal parametro effettivo corrispondente quando viene richiamata la procedura o la funzione. Le modifiche che subisce un parametro di valore formale non influiscono sul valore del parametro effettivo. Il valore del parametro del valore effettivo corrispondente deve essere un'espressione e il suo valore non deve essere un tipo di file o un tipo di struttura contenente un tipo di file. Il parametro effettivo deve essere di un tipo di assegnazione compatibile con il tipo del parametro di valore formale. Se il parametro è di tipo stringa, il parametro formale avrà un attributo size di 255. Parametri costanti Nel corpo di una subroutine, il valore di un parametro costante non può essere modificato. Le costanti-parametro possono essere utilizzate per organizzare quei parametri le cui modifiche nella subroutine sono indesiderabili e dovrebbero essere vietate. Parametri variabili Un parametro variabile viene utilizzato quando un valore deve essere passato da un sottoprogramma a un blocco richiamante. In questo caso, quando viene chiamata la subroutine, il parametro formale viene sostituito dall'argomento variabile e qualsiasi modifica al parametro formale si riflette nell'argomento. Variabili procedurali Dopo aver definito un tipo procedurale, diventa possibile descrivere variabili di questo tipo. Tali variabili sono dette variabili procedurali. Come una variabile intera a cui può essere assegnato un valore di tipo intero, a una variabile procedurale può essere assegnato un valore di tipo procedurale. Il valore potrebbe, ovviamente, essere un'altra variabile di procedura, ma potrebbe anche essere una procedura o un identificatore di funzione. In questo contesto, la dichiarazione di una procedura o funzione può essere vista come una descrizione di un tipo speciale di costante il cui valore è la procedura o la funzione. Come per qualsiasi altra assegnazione, i valori della variabile sul lato sinistro e sul lato destro devono essere compatibili con l'assegnazione. I tipi procedurali, per essere compatibili con l'assegnazione, devono avere lo stesso numero di parametri e i parametri nelle posizioni corrispondenti devono essere dello stesso tipo. I nomi dei parametri in una dichiarazione di tipo procedurale non hanno effetto. Inoltre, per garantire la compatibilità dell'assegnazione, una procedura o una funzione, se deve essere assegnata a una variabile di procedura, non deve essere standard o nidificata. 10. Tipi di parametri di subroutine Parametri di valore Un parametro di valore formale viene trattato come una variabile locale; ottiene il suo valore iniziale dal parametro effettivo corrispondente quando viene richiamata la procedura o la funzione. Le modifiche che subisce un parametro di valore formale non influiscono sul valore del parametro effettivo. Il valore effettivo corrispondente del parametro value deve essere un'espressione e il suo valore non deve essere di tipo file. Parametri costanti I parametri costanti formali ottengono il loro valore quando viene richiamata una procedura o una funzione. Non sono consentite assegnazioni a un parametro costante formale. Un parametro costante formale non può essere passato come parametro effettivo a un'altra procedura o funzione. Parametri variabili Un parametro variabile viene utilizzato quando un valore deve essere passato da una procedura o funzione al programma chiamante. Quando attivata, la variabile parametro formale viene sostituita dalla variabile effettiva, le modifiche alla variabile parametro formale vengono riflesse nel parametro effettivo. Parametri non tipizzati Quando il parametro formale è un parametro variabile non tipizzato, il parametro effettivo corrispondente può essere un riferimento variabile o costante. Un parametro non tipizzato dichiarato con la parola chiave var può essere modificato, mentre un parametro non tipizzato dichiarato con la parola chiave const è di sola lettura. Variabili procedurali Dopo aver definito un tipo procedurale, diventa possibile descrivere variabili di questo tipo. Tali variabili sono dette variabili procedurali. A una variabile procedurale può essere assegnato un valore di tipo procedurale. La procedura o funzione di assegnazione deve essere: 1) non standard; 2) non annidato; 3) non una procedura di tipo inline; 4) non dalla procedura di interruzione. Parametri di tipo procedurale Poiché i tipi procedurali possono essere utilizzati in qualsiasi contesto, è possibile descrivere procedure o funzioni che prendono procedure e funzioni come parametri. I parametri di tipo procedurale sono particolarmente utili quando è necessario eseguire azioni comuni su più procedure o funzioni. Se una procedura o una funzione deve essere passata come parametro, deve seguire le stesse regole di compatibilità dei tipi dell'assegnazione. Cioè, tali procedure o funzioni devono essere compilate con la direttiva far, non possono essere funzioni integrate, non possono essere nidificate e non possono essere descritte con gli attributi inline o interrupt. 11. Tipo di stringa in Pascal. Procedure e funzioni per variabili di tipo stringa Una sequenza di caratteri di una certa lunghezza è chiamata stringa. Le variabili di tipo stringa vengono definite specificando il nome della variabile, la stringa di parole riservate e, facoltativamente, ma non necessariamente, specificando la dimensione massima, ovvero la lunghezza della stringa, tra parentesi quadre. Se non si imposta la dimensione massima della stringa, per impostazione predefinita sarà 255, ovvero la stringa sarà composta da 255 caratteri. Ogni elemento di una stringa può essere indicato dal suo numero. Tuttavia, le stringhe sono input e output nel loro insieme, non elemento per elemento, come nel caso degli array. Il numero di caratteri immessi non deve superare quello specificato nella dimensione massima della stringa, quindi se si verifica un tale eccesso, i caratteri "extra" verranno ignorati. Procedure e funzioni per variabili di tipo stringa 1. Funzione Copia (S: Stringa; Indice, Conteggio: Intero): Stringa; Restituisce una sottostringa di una stringa. S è un'espressione di tipo String. Indice e Conteggio sono espressioni di tipo intero. La funzione restituisce una stringa contenente i caratteri di conteggio che iniziano dalla posizione dell'indice. Se Index è maggiore della lunghezza di S, la funzione restituisce una stringa vuota. 2. Procedura Delete(var S: String; Index, Count: Integer); Rimuove una sottostringa di caratteri di lunghezza Count dalla stringa S, a partire dalla posizione Index. S è una variabile di tipo String. Indice e Conteggio sono espressioni di tipo intero. Se l'indice è maggiore della lunghezza di S, nessun carattere viene rimosso. 3. Procedura Insert(Source: String; var S: String; Index: Integer); Concatena una sottostringa in una stringa, a partire da una posizione specificata. Source è un'espressione di tipo String. S è una variabile di tipo String di qualsiasi lunghezza. Index è un'espressione di tipo intero. Insert inserisce Source in S, partendo dalla posizione S. 4. Lunghezza della funzione (S: stringa): intero; Restituisce il numero di caratteri effettivamente utilizzato nella stringa S. Si noti che quando si utilizzano stringhe con terminazione null, il numero di caratteri non è necessariamente uguale al numero di byte. 5. Funzione Pos(Substr: String; S: String): Intero; Cerca una sottostringa in una stringa. Pos cerca Substr all'interno di S e restituisce un valore intero che è l'indice del primo carattere di Substr all'interno di S. Se Substr non viene trovato, Pos restituisce zero. 12. Registrazioni Un record è una raccolta di un numero limitato di componenti logicamente correlati appartenenti a tipi diversi. I componenti di un record sono chiamati campi, ognuno dei quali è identificato da un nome. Un campo record contiene il nome del campo, seguito da due punti per indicare il tipo di campo. I campi dei record possono essere di qualsiasi tipo consentito in Pascal, ad eccezione del tipo di file. La descrizione di un record in lingua Pascal viene eseguita utilizzando la parola di servizio RECORD, seguita dalla descrizione dei componenti del record. La descrizione della voce termina con la parola di servizio END. Ad esempio, un taccuino contiene cognomi, iniziali e numeri di telefono, quindi è conveniente rappresentare una riga separata in un taccuino come voce seguente: digita Riga = Registra FIO: stringa[20]; TEL: stringa[7]; fine; var str: riga; Le descrizioni dei record sono possibili anche senza utilizzare il nome del tipo, ad esempio: var str: Registra FIO: stringa[20]; TEL: stringa[7]; fine; Il riferimento a un record nel suo insieme è consentito solo nelle istruzioni di assegnazione in cui i nomi di record dello stesso tipo sono utilizzati a sinistra ea destra del segno di assegnazione. In tutti gli altri casi, vengono gestiti campi separati di record. Per fare riferimento a un singolo componente record, è necessario specificare il nome del record e, separato da un punto, specificare il nome del campo desiderato. Tale nome è chiamato nome composto. Un componente record può anche essere un record, nel qual caso il nome distinto conterrà non due, ma più nomi. Il riferimento ai componenti del record può essere semplificato utilizzando l'operatore with append. Consente di sostituire i nomi composti che caratterizzano ogni campo con solo nomi di campo e di definire il nome del record nell'istruzione join. A volte il contenuto di un singolo record dipende dal valore di uno dei suoi campi. Nella lingua Pascal è consentita una descrizione del record, composta da parti comuni e varianti. La parte variante viene specificata utilizzando il caso P di costrutto, dove P è il nome del campo dalla parte comune del record. I possibili valori accettati da questo campo sono elencati allo stesso modo dell'istruzione variante. Tuttavia, invece di specificare l'azione da eseguire, come avviene in un'istruzione variant, i campi delle varianti vengono specificati tra parentesi. La descrizione della parte variante termina con la parola di servizio end. Il tipo di campo P può essere specificato nell'intestazione della parte variante. I record vengono inizializzati utilizzando costanti tipizzate. 13. Insiemi Il concetto di insieme nel linguaggio Pascal si basa sul concetto matematico di insiemi: è un insieme limitato di elementi diversi. Un tipo di dati enumerato o intervallo viene utilizzato per costruire un tipo di set concreto. Il tipo di elementi che compongono un insieme è chiamato tipo base. Un tipo multiplo viene descritto utilizzando il Set di parole funzione, ad esempio: tipo M = Insieme di B; dove M è il tipo plurale, B è il tipo base. L'appartenenza di variabili a un tipo plurale può essere determinata direttamente nella sezione relativa alla dichiarazione delle variabili. Le costanti di tipo set vengono scritte come una sequenza tra parentesi di elementi o intervalli di tipo base, separati da virgole. Le operazioni di assegnazione (:=), unione (+), intersezione (*) e sottrazione (-) sono applicabili a variabili e costanti di un tipo impostato. Il risultato di queste operazioni è un valore di tipo plurale: 1) ['A','B'] + ['A','D'] darà ['A','B','D']; 2) ['A'] * ['A','B','C'] darà ['A']; 3) ['A','B','C'] - ['A','B'] darà ['C'] Le operazioni sono applicabili a più valori: identità (=), non identità (<>), contenuto in (<=), contiene (>=). Il risultato di queste operazioni ha un tipo booleano: 1) ['A','B'] = ['A','C'] darà FALSO; 2) ['A','B'] <> ['A','C'] darà VERO; 3) ['B'] <= ['B','C'] darà VERO; 4) ['C','D'] >= ['A'] darà FALSE. Oltre a queste operazioni, per lavorare con valori di tipo set, viene utilizzato l'in operation, che controlla se l'elemento del tipo base a sinistra del segno di operazione appartiene all'insieme a destra del segno di operazione . Il risultato di questa operazione è un booleano. I valori di tipo multiplo non possono essere elementi di un elenco di I/O. In ogni concreta implementazione del compilatore dal linguaggio Pascal, il numero di elementi del tipo base su cui è costruito il set è limitato. 14. File. Operazioni sui file Il tipo di dati file definisce una raccolta ordinata di componenti dello stesso tipo. Quando si lavora con i file, vengono eseguite operazioni di I/O. Un'operazione di input è un trasferimento di dati da un dispositivo esterno alla memoria, un'operazione di output è un trasferimento di dati dalla memoria a un dispositivo esterno. File di testo Per descrivere tali file, esiste un tipo di testo: var TF1, TF2: testo; File componenti Un componente o un file tipizzato è un file con il tipo dichiarato dei suoi componenti. digitare M = File Di T; dove M è il nome del tipo di file; T - tipo di componente. Le operazioni vengono eseguite utilizzando procedure. Scrivi(f, X1,X2,...XK) File non digitati I file non tipizzati consentono di scrivere su disco sezioni arbitrarie della memoria del computer e di leggerle. var f: file; 1. Procedura Assegna(var F; NomeFile: Stringa); Mappa un nome file su una variabile. 2. Procedura Chiudi(varF); Interrompe il collegamento tra la variabile file e il file del disco esterno e chiude il file. 3.Funzione Eof(var F): Booleano; {File digitati o non tipizzati} Funzione Eof[(var F: Text)]: Booleano; {file di testo} Verifica la fine di un file. 4. Cancellazione procedura(varF); Elimina il file esterno associato a F. 5. Funzione FileSize(var F): Intero; Restituisce la dimensione in byte del file F. 6.Funzione FilePos(varF): LongInt; Restituisce la posizione corrente all'interno di un file. 7. Ripristino procedura(var F [: File; RecSize: Word]); Apre un file esistente. 8. Riscrivi procedura(var F: File [; Ridimensiona: Word]); Crea e apre un nuovo file. 9. Procedura Seek(var F; N: LongInt); Sposta la posizione del file corrente sul componente specificato. 10. Procedura Append(var F: Text); Aggiunta. 11.Function Eoln[(var F: Text)]: Boolean; Verifica la fine di una stringa. 12. Procedura Lettura(F, V1 [, V2..., Vn]); {File digitati e non tipizzati} Procedura Leggi([var F: Testo;] V1 [, V2..., Vn]); {file di testo} Legge un componente di file in una variabile. 13. Procedura Readln([var F: Testo;] V1 [, V2..., Vn]); Legge una riga di caratteri nel file, incluso l'indicatore di fine riga, e si sposta all'inizio di quella successiva. 14. Funzione SeekEof[(var F: Text)]: Boolean; Restituisce il segno di fine file. Utilizzato solo per file di testo aperti. 15. Procedura Writeln([var F: Testo;] [P1, P2..., Pn]); {file di testo} Esegue un'operazione di scrittura, quindi inserisce un indicatore di fine riga nel file. 15. Moduli. Tipi di moduli Un'unità (UNIT) in Pascal è una libreria di subroutine appositamente progettata. Un modulo, a differenza di un programma, non può essere avviato per l'esecuzione da solo, può solo partecipare alla creazione di programmi e altri moduli. Un modulo in Pascal è un'unità di programma memorizzata separatamente e compilata in modo indipendente. Tutti gli elementi del programma del modulo possono essere divisi in due parti: 1) elementi di programma destinati ad essere utilizzati da altri programmi o moduli, tali elementi sono detti visibili all'esterno del modulo; 2) elementi software che sono necessari solo al funzionamento del modulo stesso, sono detti invisibili (o nascosti). unità <nome modulo>; {titolo del modulo} interfaccia {descrizione degli elementi di programma visibili del modulo} implementazione {descrizione degli elementi di programmazione nascosti del modulo} iniziare {dichiarazioni di inizializzazione dell'elemento del modulo} fine. Per fare riferimento a una variabile dichiarata in un modulo, è necessario utilizzare un nome composto composto dal nome del modulo e dal nome della variabile, separati da un punto. È vietato l'uso ricorsivo dei moduli. Elenchiamo i tipi di moduli. 1. Modulo SISTEMA. Il modulo SYSTEM implementa routine di supporto di livello inferiore per tutte le funzionalità integrate come I/O, manipolazione di stringhe, operazioni in virgola mobile e allocazione dinamica della memoria. 2. Modulo DOS. Il modulo Dos implementa numerose routine e funzioni Pascal equivalenti alle chiamate DOS più comunemente utilizzate, come GetTime, SetTime, DiskSize e così via. 3. Modulo CRT. Il modulo CRT implementa una serie di potenti programmi che forniscono il controllo completo sulle funzionalità del PC, come il controllo della modalità schermo, codici tastiera estesi, colori, finestre e suoni. 4. Modulo GRAFICO. Utilizzando le procedure e le funzioni incluse in questo modulo, è possibile creare vari grafici sullo schermo. 5. Modulo SOVRAPPOSIZIONE. Il modulo OVERLAY consente di ridurre i requisiti di memoria di un programma DOS in modalità reale. 16. Tipo di dati di riferimento. memoria dinamica. variabili dinamiche. Lavorare con la memoria dinamica Una variabile statica (allocata staticamente) è una variabile dichiarata esplicitamente nel programma, a cui si fa riferimento per nome. La posizione in memoria per posizionare le variabili statiche viene determinata al momento della compilazione del programma. A differenza di tali variabili statiche, i programmi Pascal possono creare variabili dinamiche. La proprietà principale delle variabili dinamiche è che vengono create e per esse viene allocata memoria durante l'esecuzione del programma. Le variabili dinamiche sono collocate in un'area di memoria dinamica (heap-area). Una variabile dinamica non è specificata in modo esplicito nelle dichiarazioni di variabile e non può essere definita per nome. È possibile accedere a tali variabili utilizzando puntatori e riferimenti. Un tipo di riferimento (puntatore) definisce un insieme di valori che puntano a variabili dinamiche di un certo tipo, chiamate tipo base. Una variabile di tipo riferimento contiene l'indirizzo di una variabile dinamica in memoria. Se il tipo di base è un identificatore non dichiarato, deve essere dichiarato nella stessa parte della dichiarazione del tipo del tipo di puntatore. La parola riservata nil denota una costante con un valore di puntatore che non punta a nulla. Facciamo un esempio della descrizione di variabili dinamiche. var p1, p2: ^reale; p3, p4: ^intero; ... Procedure e funzioni di memoria dinamica 1. Procedura Nuovo{var p: Puntatore). Alloca spazio nell'area di memoria dinamica per ospitare la variabile dinamica p" e assegna il suo indirizzo al puntatore p. 2. Procedura Dispose(var p: Pointer). Libera la memoria allocata per l'allocazione dinamica delle variabili dalla procedura New e il valore del puntatore p diventa indefinito. 3. Procedura GetMem(var p: Pointer; size: Word). Alloca una sezione di memoria nell'area heap, assegna l'indirizzo del suo inizio al puntatore p, la dimensione della sezione in byte è specificata dal parametro size. 4. Procedura FreeMem(varp: Pointer; size: Word). Rilascia l'area di memoria, il cui indirizzo iniziale è specificato dal puntatore p e la dimensione è specificata dal parametro size. Il valore del puntatore p diventa indefinito. 5. La procedura Mark{var p: Pointer) scrive nel puntatore p l'indirizzo di inizio della sezione di memoria dinamica libera al momento della sua chiamata. 6. La procedura Release(var p: Pointer) libera una sezione di memoria dinamica, a partire dall'indirizzo scritto sul puntatore p dalla procedura Mark, ovvero cancella la memoria dinamica che era occupata dopo la chiamata alla procedura Mark. 7. Funzione MaxAvail: Longint restituisce la lunghezza in byte della sezione libera più lunga della memoria dinamica. 8. Funzione MemAvail: Longint restituisce la quantità totale di memoria dinamica libera in byte. 9. La funzione di supporto SizeOf(X):Word restituisce la dimensione in byte occupata da X, dove X può essere un nome di variabile di qualsiasi tipo o un nome di tipo. 17. Strutture dati astratte I tipi di dati strutturati, come matrici, set e record, sono strutture statiche perché le loro dimensioni non cambiano durante l'intera esecuzione del programma. Spesso è necessario che le strutture dati cambino le loro dimensioni nel corso della risoluzione di un problema. Tali strutture dati sono dette dinamiche. Questi includono pile, code, elenchi, alberi, ecc. La descrizione di strutture dinamiche con l'aiuto di array, record e file porta a un uso dispendioso della memoria del computer e aumenta il tempo per la risoluzione dei problemi. Ogni componente di qualsiasi struttura dinamica è un record contenente almeno due campi: un campo di tipo "puntatore" e il secondo - per il posizionamento dei dati. In generale, un record può contenere non uno, ma più puntatori e più campi di dati. Un campo dati può essere una variabile, un array, un set o un record. Se la parte di puntamento contiene l'indirizzo di un elemento dell'elenco, l'elenco viene chiamato unidirezionale (o collegato singolarmente). Se contiene due componenti, è doppiamente connesso. È possibile eseguire varie operazioni sugli elenchi, ad esempio: 1) aggiunta di un elemento alla lista; 2) rimuovere un elemento dalla lista con una determinata chiave; 3) cercare un elemento con un dato valore del campo chiave; 4) ordinare gli elementi della lista; 5) suddivisione della lista in due o più liste; 6) combinare due o più liste in una sola; 7) altre operazioni. Tuttavia, di norma, non si pone la necessità di tutte le operazioni per risolvere vari problemi. Pertanto, a seconda delle operazioni di base che devono essere applicate, esistono diversi tipi di elenchi. I più popolari di questi sono stack e queue. 18. Pile Uno stack è una struttura di dati dinamica, l'aggiunta di un componente a cui e la rimozione di un componente da cui sono costituiti da un'estremità, chiamata la parte superiore dello stack. Lo stack funziona secondo il principio LIFO (Last-In, First-Out) - "Last in, first out". Di solito vengono eseguite tre operazioni sugli stack: 1) formazione iniziale della catasta (record del primo componente); 2) aggiunta di un componente allo stack; 3) selezione del componente (cancellazione). Per formare uno stack e lavorare con esso, è necessario disporre di due variabili del tipo "pointer", la prima delle quali determina la parte superiore dello stack e la seconda è ausiliaria. Esempio. Scrivete un programma che formi uno stack, vi aggiunga un numero arbitrario di componenti e poi legga tutti i componenti. Programma STACK; utilizza Crt; Digitare Alfa = Stringa[10]; PComp = ^Comp; Comp = record SD: Alfa; pSuccessivo: PComp fine; var pIn alto:PComp; sc: Alfa; Crea ProcedureStack(var pTop: PComp; var sC: Alfa); iniziare Nuovo(pIn alto); pInizio^.pAvanti:= NIL; pTop^.sD:= sC; fine; Aggiungi ProcedureComp(var pTop: PComp; var sC: Alfa); var pAux: PComp; iniziare NUOVO(pAux); pAux^.pAvanti:= pTop; pTop:=pAux; pTop^.sD:= sC; fine; Procedura DelComp(var pTop: PComp; var sC: ALFA); iniziare sC:= pTop^.sD; pTop:= pTop^.pSuccessivo; fine; iniziare clrscr; writeln(INVIO STRINGA); readln(sc); CreateStack(pTop, sc); ripetere writeln(INVIO STRINGA); readln(sc); AddComp(pTop, sc); fino a sC = 'FINE'; 19. Code Una coda è una struttura dati dinamica in cui un componente viene aggiunto a un'estremità e recuperato all'altra estremità. La coda funziona secondo il principio FIFO (First-In, First-Out) - "First in, first serve". Esempio. Scrivete un programma che formi una coda, vi aggiunga un numero arbitrario di componenti e poi legga tutti i componenti. CODA di programma; utilizza Crt; Digitare Alfa = Stringa[10]; PComp = ^Comp; Comp = registrazione SD: Alfa; pAvanti: PComp; fine; var pInizio, pEnd: PComp; sc: Alfa; Crea ProcedureQueue(var pBegin,pEnd: PComp; var sc: Alfa); iniziare Nuovo(pInizio); pInizio^.pSuccessivo:= NIL; pInizio^.sD:= sC; pEnd:=pInizio; fine; Procedura AddQueue(var pEnd: PComp; var sC: alfa); var pAux: PComp; iniziare Nuovo(pAux); pAux^.pNext:= NIL; pFine^.pAvanti:= pAux; pFine:= pAux; pFine^.sD:= sC; fine; Procedura DelQueue(var pBegin: PComp; var sC: alfa); iniziare sC:=pInizio^.sD; pInizio:= pInizio^.pAvanti; fine; iniziare clrscr; writeln(INVIO STRINGA); readln(sc); CreateQueue(pBegin, pEnd, sc); ripetere writeln(INVIO STRINGA); readln(sc); AggiungiCoda(pEnd, sc); fino a sC = 'FINE'; 20. Strutture dati ad albero Una struttura dati ad albero è un insieme finito di elementi-nodi tra i quali esistono relazioni: la connessione tra la sorgente e il generato. Se utilizziamo la definizione ricorsiva proposta da N. Wirth, allora una struttura dati ad albero con tipo base t è una struttura vuota o un nodo di tipo t, con cui un insieme finito di strutture ad albero con tipo base t, detti sottoalberi, è associato. Successivamente, diamo le definizioni utilizzate quando si opera con le strutture ad albero. Se il nodo y si trova direttamente sotto il nodo x, allora il nodo y è chiamato discendente immediato del nodo x, e x è l'antenato immediato del nodo y, cioè, se il nodo x è al livello i-esimo, allora il nodo y è di conseguenza situato al (i + 1 ) -esimo livello. Il livello massimo di un nodo dell'albero è chiamato altezza o profondità dell'albero. Un antenato non ha solo un nodo dell'albero: la sua radice. I nodi dell'albero che non hanno figli sono chiamati nodi foglia (o foglie dell'albero). Tutti gli altri nodi sono chiamati nodi interni. Il numero di figli immediati di un nodo determina il grado di quel nodo e il grado massimo possibile di un nodo in un dato albero determina il grado dell'albero. Antenati e discendenti non possono essere scambiati, cioè la connessione tra l'originale e il generato agisce solo in una direzione. Se si passa dalla radice dell'albero a un nodo particolare, il numero di rami dell'albero che verranno attraversati in questo caso è chiamato lunghezza del percorso per questo nodo. Se tutti i rami (nodi) di un albero sono ordinati, si dice che l'albero è ordinato. Gli alberi binari sono un caso speciale di strutture ad albero. Questi sono alberi in cui ogni bambino ha al massimo due figli, chiamati sottoalberi sinistro e destro. Pertanto, un albero binario è una struttura ad albero il cui grado è due. L'ordinamento di un albero binario è determinato dalla seguente regola: ogni nodo ha il proprio campo chiave, e per ogni nodo il valore della chiave è maggiore di tutte le chiavi nel suo sottoalbero di sinistra e minore di tutte le chiavi nel suo sottoalbero di destra. Un albero il cui grado è maggiore di due è chiamato fortemente ramificato. 21. Operazioni sugli alberi Inoltre, considereremo tutte le operazioni in relazione agli alberi binari. I. Costruire un albero. Presentiamo un algoritmo per costruire un albero ordinato. 1. Se l'albero è vuoto, i dati vengono trasferiti alla radice dell'albero. Se l'albero non è vuoto, uno dei suoi rami scende in modo tale che l'ordine dell'albero non venga violato. Di conseguenza, il nuovo nodo diventa la foglia successiva dell'albero. 2. Per aggiungere un nodo a un albero già esistente, puoi utilizzare l'algoritmo sopra. 3. Quando si elimina un nodo dall'albero, prestare attenzione. Se il nodo da rimuovere è una foglia, o ha un solo figlio, l'operazione è semplice. Se il nodo da eliminare ha due discendenti, allora sarà necessario trovare un nodo tra i suoi discendenti che possa essere messo al suo posto. Ciò è necessario a causa del requisito che l'albero sia ordinato. Puoi farlo: scambiare il nodo da rimuovere con il nodo con il valore di chiave più grande nel sottoalbero di sinistra, o con il nodo con il valore di chiave più piccolo nel sottoalbero di destra, quindi eliminare il nodo desiderato come foglia. II. Cerca un nodo con un dato valore del campo chiave. Quando si esegue questa operazione, è necessario attraversare l'albero. È necessario tenere conto delle diverse forme di scrittura di un albero: prefisso, infisso e suffisso. Sorge la domanda: come rappresentare i nodi dell'albero in modo che sia più conveniente lavorare con loro? È possibile rappresentare un albero utilizzando un array, in cui ogni nodo è descritto da un valore di tipo combinato, che ha un campo informazioni di tipo carattere e due campi di tipo riferimento. Ma questo non è molto conveniente, poiché gli alberi hanno un gran numero di nodi che non sono predeterminati. Pertanto, è meglio utilizzare variabili dinamiche quando si descrive un albero. Quindi ogni nodo è rappresentato da un valore dello stesso tipo, che contiene la descrizione di un determinato numero di campi di informazioni, e il numero di campi corrispondenti deve essere uguale al grado dell'albero. È logico definire l'assenza di discendenti con il riferimento zero. Quindi, in Pascal, la descrizione di un albero binario potrebbe assomigliare a questa: TIPO TreeLink = ^Albero; albero = record; Inf: <tipo di dati>; Sinistra, Destra: TreeLink; Fine. 22. Esempi di attuazione delle operazioni 1. Costruisci un albero di XNUMX nodi di altezza minima o un albero perfettamente bilanciato (il numero di nodi dei sottoalberi sinistro e destro di un tale albero non dovrebbe differire di più di uno). Algoritmo di costruzione ricorsivo: 1) il primo nodo viene preso come radice dell'albero; 2) il sottoalbero sinistro di nl nodi è costruito allo stesso modo; 3) il sottoalbero di destra di nr nodi è costruito allo stesso modo; nr = n - nl - 1 Come campo informativo, prenderemo i numeri di nodo inseriti dalla tastiera. La funzione ricorsiva che implementa questa costruzione sarà simile a questa: Albero delle funzioni(n: Byte): TreeLink; Versione: TreeLink; nl,nr,x: byte; Iniziare Se n = 0 allora Tree:= nil Altro Iniziare nl:= n div 2; nr = n - nl - 1; writeln('Inserisci numero vertice ); leggiln(x); tritone); t^.inf:= x; t^.sinistra:= Albero(nl); t^.destra:= Albero(nr); Albero:=t; End; {Albero} Fine. 2. Nell'albero ordinato binario, trova il nodo con il valore dato del campo chiave. Se non c'è un tale elemento nell'albero, aggiungilo all'albero. Procedura di ricerca(x: Byte; var t: TreeLink); Iniziare Se t = zero allora Iniziare Tritone); t^inf:= x; t^.sinistra:= zero; t^.destra:= zero; Fine Altrimenti se x < t^.inf allora Cerca(x, t^.sinistra) Altrimenti se x > t^.inf allora Cerca(x, t^.destra) Altro Iniziare {processo trovato elemento} ... End; Fine. 23. Il concetto di grafico. Modi per rappresentare un grafico Un grafo è una coppia G = (V,E), dove V è un insieme di oggetti di natura arbitraria, detti vertici, ed E è una famiglia di coppie ei = (vil, vi2), vijOV, detti archi. Nel caso generale, l'insieme V e (o) la famiglia E possono contenere un numero infinito di elementi, ma considereremo solo grafi finiti, cioè grafi per i quali sia V che E sono finiti. Se l'ordine degli elementi inclusi in ei conta, il grafo è chiamato diretto, abbreviato - digraph, altrimenti - non orientato. I bordi di un digrafo sono chiamati archi. Se e = , allora i vertici v e u sono chiamati le estremità del bordo. In questo caso, il bordo e si dice adiacente (incidente) a ciascuno dei vertici v e u. I vertici ve e sono anche chiamati adiacenti (incidente). Nel caso generale, spigoli della forma e = ; tali bordi sono chiamati loop. Il grado di un vertice del grafico è il numero di archi incidenti al vertice dato, con i cicli contati due volte. Il peso di un nodo è un numero (reale, intero o razionale) assegnato a un dato nodo (interpretato come costo, velocità effettiva, ecc.). Un percorso in un grafo (o un percorso in un digrafo) è una sequenza alternata di vertici e archi (o archi in un digrafo) della forma v0, (v0,v1), v1,..., (vn -1, vn), vn. Il numero n è chiamato lunghezza del percorso. Un percorso senza bordi ripetuti è chiamato catena; un percorso senza vertici ripetuti è chiamato catena semplice. Un percorso chiuso senza bordi ripetuti è chiamato ciclo (o contorno in un digrafo); senza ripetere i vertici (tranne il primo e l'ultimo) - un ciclo semplice. Un grafo si dice connesso se c'è un percorso tra due dei suoi vertici e disconnesso in caso contrario. Esistono vari modi per rappresentare i grafici. 1. Matrice di incidenza. Questa è una matrice rettangolare n x m, dove n è il numero di vertici e m è il numero di archi. 2. Matrice di adiacenza. Questa è una matrice quadrata di dimensioni n × n, dove n è il numero di vertici. 3. Elenco delle adiacenze (incidenti). Rappresenta una struttura dati che per ogni vertice del grafico viene memorizzato un elenco di vertici adiacenti ad esso. L'elenco è un array di puntatori, il cui i-esimo elemento contiene un puntatore all'elenco di vertici adiacenti all'i-esimo vertice. 4. Elenco delle liste. È una struttura dati ad albero in cui un ramo contiene elenchi di vertici adiacenti a ciascuno. 24. Varie rappresentazioni di grafici Per implementare un grafico come elenco di incidenza, è possibile utilizzare il tipo seguente: Elenco tipi = ^S; S=record; inf: byte; successivo: Elenco; fine; Quindi il grafico è definito come segue: Vargr: array[1..n] di List; Passiamo ora alla procedura di attraversamento del grafico. Questo è un algoritmo ausiliario che permette di visualizzare tutti i vertici del grafico, analizzare tutti i campi di informazioni. Se consideriamo in profondità l'attraversamento del grafo, allora ci sono due tipi di algoritmi: ricorsivi e non ricorsivi. In Pascal, la procedura di attraversamento in profondità sarebbe simile a questa: Procedura Obhod(gr: Grafico; k: Byte); Varg: grafico; l:Elenco; Iniziare nov[k]:= falso; g:=gr; Mentre g^.inf <> k lo fa g:= g^.successivo; l:= g^.smeg; Mentre l <> zero inizia Se nov[l^.inf] allora Obhod(gr, l^.inf); l:= l^.successivo; End; End; Rappresentazione di un grafico come un elenco di elenchi Un grafico può essere definito utilizzando un elenco di elenchi come segue: TypeList = ^Tlist; tlista=record inf: byte; successivo: Elenco; fine; Grafico = ^TGPaph; TPaph = record inf: byte; smeg: elenco; successivo: grafico; fine; Quando si attraversa il grafico in ampiezza, selezioniamo un vertice arbitrario e osserviamo tutti i vertici adiacenti ad esso contemporaneamente. Ecco una procedura per attraversare un grafico in larghezza in pseudocodice: Procedura Obhod2(v); Iniziare coda = O; coda <= v; nov[v] = Falso; Mentre la coda <> O fallo Iniziare p <= coda; Per te in spisok(p) fai Se nuovo[u] allora Iniziare nov[u]:= Falso; coda <= te; End; End; End; 25. Tipo di oggetto in Pascal. Il concetto di un oggetto, la sua descrizione e utilizzo Un linguaggio di programmazione orientato agli oggetti è caratterizzato da tre proprietà principali: 1) incapsulamento. La combinazione di record con procedure e funzioni che manipolano i campi di questi record forma un nuovo tipo di dati: un oggetto; 2) eredità. Definizione di un oggetto e suo ulteriore utilizzo per costruire una gerarchia di oggetti figlio con la possibilità per ogni oggetto figlio correlato alla gerarchia di accedere al codice e ai dati di tutti gli oggetti padre; 3) polimorfismo. Assegnare a un'azione un unico nome, che viene quindi condiviso su e giù nella gerarchia degli oggetti, con ogni oggetto nella gerarchia che esegue quell'azione in un modo che gli si addice. Parlando dell'oggetto, introduciamo un nuovo tipo di dati: l'oggetto. Un tipo di oggetto è una struttura costituita da un numero fisso di componenti. Ciascun componente è un campo contenente dati di un tipo rigorosamente definito o un metodo che esegue operazioni su un oggetto. Un tipo di oggetto può ereditare componenti di un altro tipo di oggetto. Se il tipo T2 eredita dal tipo T1, il tipo T2 è un figlio di tipo G e il tipo G stesso è un genitore di tipo G2. Il codice sorgente seguente fornisce un esempio di una dichiarazione del tipo di oggetto. Digitare punto = oggetto X, Y: intero; fine; Rett = oggetto A, B: Punto T; procedura Init(XA, YA, XB, YB: Intero); procedura Copia(var R: TRectangle); procedura Sposta(DX, DY: Intero); procedura Cresci(DX, DY: Intero); procedura Interseca(var R: TRectangle); procedura Unione(var R: TRectangle); funzione Contiene (P: Punto): Booleano; fine; A differenza di altri tipi, i tipi di oggetto possono essere dichiarati solo nella sezione della dichiarazione del tipo al livello più esterno dell'ambito di un programma o modulo. Pertanto, i tipi di oggetto non possono essere dichiarati in una sezione di dichiarazione di variabile o all'interno di una procedura, una funzione o un blocco di metodi. Un tipo di componente di tipo file non può avere un tipo di oggetto o qualsiasi tipo di struttura contenente componenti di tipo di oggetto. 26. Eredità L'ereditarietà è il processo di generazione di nuovi tipi figlio dai tipi padre esistenti, mentre il figlio riceve (eredita) dal genitore tutti i suoi campi e metodi. Il tipo discendente, in questo caso, è chiamato tipo erede o figlio. E il tipo da cui eredita il tipo figlio è chiamato tipo padre. I campi ei metodi ereditati possono essere utilizzati invariati o ridefiniti (modificati). N. Wirth nel suo linguaggio Pascal ha cercato la massima semplicità, quindi non l'ha complicata introducendo la relazione di eredità. Pertanto, i tipi in Pascal non possono ereditare. Tuttavia, Turbo Pascal 7.0 estende questo linguaggio per supportare l'ereditarietà. Una di queste estensioni è una nuova categoria di struttura dati relativa ai record, ma molto più potente. I tipi di dati in questa nuova categoria vengono definiti utilizzando la nuova parola riservata Object. La sintassi è molto simile alla sintassi per la definizione dei record: Tipologia <nome tipo> = Oggetto [(<nome tipo padre>)] ([<ambito>] <descrizione dei campi e dei metodi>)+ fine; Il segno "+" dopo un costrutto di sintassi tra parentesi significa che questo costrutto deve verificarsi una o più volte in questa descrizione. L'ambito è una delle seguenti parole chiave: ▪ Privati; ▪ Protetto; ▪ Pubblico. Lo scopo caratterizza a quali parti del programma saranno disponibili i componenti le cui descrizioni seguono la parola chiave che denomina questo ambito. Per ulteriori informazioni sugli ambiti dei componenti, vedere la domanda n. 28. L'ereditarietà è un potente strumento utilizzato nello sviluppo del programma. Consente di mettere in pratica una scomposizione orientata agli oggetti di un problema, di esprimere relazioni tra oggetti di tipi che formano una gerarchia attraverso il linguaggio, e promuove anche il riutilizzo del codice di programma. 27. Istanziare oggetti Un'istanza di un oggetto viene creata dichiarando una variabile o una costante di un tipo di oggetto, oppure applicando la procedura standard New a una variabile di tipo "puntatore al tipo di oggetto". L'oggetto risultante è chiamato istanza del tipo di oggetto. Se un tipo di oggetto contiene metodi virtuali, le istanze di quel tipo di oggetto devono essere inizializzate chiamando un costruttore prima di chiamare qualsiasi metodo virtuale. L'assegnazione di un'istanza di un tipo di oggetto non implica l'inizializzazione dell'istanza. Un oggetto viene inizializzato dal codice generato dal compilatore che viene eseguito tra la chiamata del costruttore e il punto in cui l'esecuzione raggiunge effettivamente la prima istruzione nel blocco di codice del costruttore. Se l'istanza dell'oggetto non è inizializzata e il controllo dell'intervallo è abilitato (dalla direttiva {$R+}), la prima chiamata al metodo virtuale dell'istanza dell'oggetto genera un errore di runtime. Se il controllo dell'intervallo è disattivato dalla direttiva {$R-}), la prima chiamata a un metodo virtuale di un oggetto non inizializzato può portare a un comportamento imprevedibile. La regola di inizializzazione obbligatoria si applica anche alle istanze che sono componenti di tipi struct. Per esempio: var Commento: array [1..5] di TStrField; io: intero iniziare per I:= da 1 a 5 fare Commento [I].Init (1, I + 10, 40, 'first_name'); . . . per I:= da 1 a 5 commenta [I].Fatto; fine; Per le istanze dinamiche, l'inizializzazione riguarda in genere il posizionamento e la pulizia riguarda l'eliminazione, che si ottiene attraverso la sintassi estesa delle procedure standard New e Dispose. Per esempio: var SP: StrFieldPtr; iniziare New(SP, Init(1, 1, 25, 'first_name'); SP^.Put('Vladimir'); SP^.Visualizza; . . . Smaltire (SP, Fatto); fine. Un puntatore a un tipo di oggetto è un'assegnazione compatibile con un puntatore a qualsiasi tipo di oggetto padre, quindi in fase di esecuzione un puntatore a un tipo di oggetto può puntare a un'istanza di quel tipo oa un'istanza di qualsiasi tipo figlio. 28. Componenti e ambito L'ambito di un identificatore di bean si estende oltre il tipo di oggetto. Inoltre, l'ambito di un identificatore di bean si estende attraverso i blocchi di procedure, funzioni, costruttori e distruttori che implementano i metodi del tipo di oggetto e dei suoi discendenti. Sulla base di queste considerazioni, l'identificatore del componente deve essere univoco all'interno del tipo di oggetto e in tutti i suoi discendenti, nonché in tutti i suoi metodi. In una dichiarazione del tipo di oggetto, un'intestazione di metodo può specificare i parametri del tipo di oggetto descritto, anche se la dichiarazione non è ancora completa. Considera lo schema seguente per una dichiarazione di tipo che contiene componenti di tutti gli ambiti validi: Tipologia <nome tipo> = Oggetto [(<nome tipo padre>)] Privata <descrizioni private di campi e metodi> Protetta <descrizioni di metodi e campi protetti> Pubblico <descrizioni pubbliche di campi e metodi> fine; I campi ei metodi descritti nella sezione Privati possono essere utilizzati solo all'interno del modulo contenente le relative dichiarazioni e in nessun altro luogo. I campi ei metodi protetti, ovvero quelli descritti nella sezione Protetto, sono visibili nel modulo in cui è definito il tipo e nei discendenti del tipo. I campi ei metodi della sezione Public non hanno restrizioni sul loro utilizzo e possono essere utilizzati ovunque nel programma che abbia accesso a un oggetto di questo tipo. L'ambito dell'identificatore del componente descritto nella parte privata della dichiarazione del tipo è limitato al modulo (programma) che contiene la dichiarazione del tipo di oggetto. In altre parole, i bean di identificatore privato agiscono come normali identificatori pubblici all'interno del modulo che contiene la dichiarazione del tipo di oggetto e all'esterno del modulo tutti i bean privati e gli identificatori sono sconosciuti e inaccessibili. Inserendo tipi correlati di oggetti nello stesso modulo, puoi assicurarti che questi oggetti possano accedere ai rispettivi componenti privati e che questi componenti privati saranno sconosciuti agli altri moduli. 29. Metodi Una dichiarazione di metodo all'interno di un tipo di oggetto corrisponde a una dichiarazione di metodo forward (forward). Pertanto, da qualche parte dopo una dichiarazione del tipo di oggetto, ma all'interno dello stesso ambito della dichiarazione del tipo di oggetto, è necessario implementare un metodo definendone la dichiarazione. Per i metodi procedurali e funzionali, la dichiarazione di definizione assume la forma di una normale procedura o dichiarazione di funzione, con l'eccezione che in questo caso l'identificatore di procedura o funzione è trattato come identificatore di metodo. La descrizione di definizione di un metodo contiene sempre un parametro implicito con l'identificatore Self, corrispondente a un parametro variabile formale che ha un tipo di oggetto. All'interno di un blocco di metodo, Self rappresenta l'istanza il cui componente del metodo è stato specificato per richiamare il metodo. Pertanto, qualsiasi modifica ai valori dei campi Self si riflette nell'istanza. Metodi virtuali I metodi sono statici per impostazione predefinita, ma ad eccezione dei costruttori, possono essere virtuali (includendo la direttiva virtual nella dichiarazione del metodo). Il compilatore risolve i riferimenti alle chiamate di metodi statici durante il processo di compilazione, mentre le chiamate di metodi virtuali vengono risolte in fase di esecuzione. Questo è talvolta chiamato rilegatura tardiva. L'override di un metodo statico è indipendente dalla modifica dell'intestazione del metodo. Al contrario, l'override di un metodo virtuale deve preservare l'ordine, i tipi e i nomi dei parametri e i tipi di risultati delle funzioni, se presenti. Inoltre, la ridefinizione deve includere nuovamente la direttiva virtuale. Metodi dinamici Borland Pascal supporta ulteriori metodi di associazione tardiva chiamati metodi dinamici. I metodi dinamici differiscono dai metodi virtuali solo per il modo in cui vengono inviati in fase di esecuzione. Sotto tutti gli altri aspetti, i metodi dinamici sono considerati equivalenti a quelli virtuali. Una dichiarazione di metodo dinamico equivale a una dichiarazione di metodo virtuale, ma la dichiarazione di metodo dinamico deve includere l'indice del metodo dinamico, che viene specificato immediatamente dopo la parola chiave virtual. L'indice di un metodo dinamico deve essere una costante intera compresa tra 1 e 656535 e deve essere univoco tra gli indici di altri metodi dinamici contenuti nel tipo di oggetto o nei suoi predecessori. Per esempio: procedura FileOpen(var Msg: TMessage); virtuale 100; Una sostituzione di un metodo dinamico deve corrispondere all'ordine, ai tipi e ai nomi dei parametri e corrispondere esattamente al tipo di risultato della funzione del metodo padre. L'override deve includere anche una direttiva virtuale seguita dallo stesso indice del metodo dinamico specificato nel tipo di oggetto predecessore. 30. Costruttori e distruttori Costruttori e distruttori sono forme specializzate di metodi. Utilizzati in connessione con la sintassi estesa delle procedure standard New e Dispose, i costruttori e i distruttori hanno la capacità di posizionare e rimuovere oggetti dinamici. Inoltre, i costruttori hanno la capacità di eseguire l'inizializzazione richiesta di oggetti contenenti metodi virtuali. Come tutti i metodi, costruttori e distruttori possono essere ereditati e gli oggetti possono contenere un numero qualsiasi di costruttori e distruttori. I costruttori vengono utilizzati per inizializzare gli oggetti appena creati. In genere, l'inizializzazione si basa sui valori passati al costruttore come parametri. Un costruttore non può essere virtuale perché il meccanismo di invio di un metodo virtuale dipende dal costruttore che ha inizializzato per primo l'oggetto. Ecco alcuni esempi di costruttori: costruttore Field.Copy(var F: Field); iniziare Sé:=F; fine; L'azione principale di un costruttore di tipo derivato (figlio) consiste quasi sempre nel chiamare il costruttore appropriato del suo genitore immediato per inizializzare i campi ereditati dell'oggetto. Dopo aver eseguito questa procedura, il costruttore inizializza i campi dell'oggetto che appartengono solo al tipo derivato. I distruttori sono l'opposto dei costruttori e vengono utilizzati per ripulire gli oggetti dopo che sono stati utilizzati. Normalmente, la pulizia consiste nella rimozione di tutti i campi del puntatore nell'oggetto. Nota Un distruttore può essere virtuale, e spesso lo è. Un distruttore ha raramente parametri. Ecco alcuni esempi di distruttori: distruttore Campo Fatto; iniziare FreeMem(Nome, Lunghezza(Nome^) + 1); fine; distruttore StrField.Done; iniziare FreeMem(Valore, Len); campo fatto; fine; Il distruttore di un tipo figlio, ad esempio TStrField sopra. Fatto, in genere rimuove prima i campi del puntatore introdotti nel tipo derivato e quindi, come ultimo passaggio, chiama il distruttore di raccolta appropriato del genitore immediato per rimuovere i campi del puntatore ereditati dell'oggetto. 31. Distruttori Borland Pascal fornisce un tipo speciale di metodo chiamato Garbage Collector (o distruttore) per ripulire ed eliminare un oggetto allocato dinamicamente. Il distruttore combina la fase di eliminazione di un oggetto con qualsiasi altra azione o attività richiesta per quel tipo di oggetto. È possibile definire più distruttori per un singolo tipo di oggetto. I distruttori possono essere ereditati e possono essere statici o virtuali. Poiché finalizzatori diversi tendono a richiedere tipi diversi di oggetti, è generalmente consigliabile che i distruttori siano sempre virtuali in modo che venga eseguito il distruttore corretto per ogni tipo di oggetto. Non è necessario specificare il distruttore di parole riservate per ogni metodo di pulizia, anche se la definizione del tipo dell'oggetto contiene metodi virtuali. I distruttori funzionano davvero solo su oggetti allocati dinamicamente. Quando un oggetto allocato dinamicamente viene ripulito, il distruttore svolge una funzione speciale: assicura che il numero corretto di byte venga sempre liberato nell'area di memoria allocata dinamicamente. Non ci può essere alcuna preoccupazione sull'utilizzo di un distruttore con oggetti allocati staticamente; infatti, non passando il tipo dell'oggetto al distruttore, il programmatore priva un oggetto di quel tipo dei pieni benefici della gestione dinamica della memoria in Borland Pascal. I distruttori diventano effettivamente se stessi quando gli oggetti polimorfici devono essere cancellati e quando la memoria che occupano deve essere deallocata. Gli oggetti polimorfici sono quegli oggetti che sono stati assegnati a un tipo padre a causa delle regole di compatibilità dei tipi estesi di Borland Pascal. Il termine "polimorfico" è appropriato perché il codice che elabora un oggetto "non sa" esattamente in fase di compilazione quale tipo di oggetto dovrà eventualmente elaborare. L'unica cosa che sa è che questo oggetto appartiene a una gerarchia di oggetti che sono discendenti del tipo di oggetto specificato. Il metodo distruttore stesso può essere vuoto ed eseguire solo questa funzione: distruttoreAnObject.Done; iniziare fine; Ciò che è utile in questo distruttore non è la proprietà del suo corpo, tuttavia, il compilatore genera il codice dell'epilogo in risposta alla parola riservata del distruttore. È come un modulo che non esporta nulla, ma fa del lavoro invisibile eseguendo la sua sezione di inizializzazione prima di avviare il programma. Tutta l'azione si svolge dietro le quinte. 32. Metodi virtuali Un metodo diventa virtuale se la sua dichiarazione del tipo di oggetto è seguita dalla nuova parola riservata virtual. Se un metodo in un tipo padre viene dichiarato virtuale, anche tutti i metodi con lo stesso nome nei tipi figlio devono essere dichiarati virtuali per evitare un errore del compilatore. Di seguito sono riportati gli oggetti del libro paga di esempio, opportunamente virtualizzati: genere PEdipendente = ^TEmployee; Temployee = oggetto Nome, Titolo: stringa[25]; Tariffa: Reale; costruttore Init(AName, ATitle: String; ARate: Real); funzione GetPayAmount: reale; virtuale; funzione Ottieni Nome: Stringa; funzione OttieniTitolo: Stringa; funzione GetRate: Reale; procedura Mostra; virtuale; fine; POraria = ^TOraria; TOraria = oggetto(Timpiegato); Tempo: intero; costruttore Init(AName, ATitle: String; ARate: Real; Tempo: intero); funzione GetPayAmount: reale; virtuale; funzione GetTime: Intero; fine; PSlaried = ^TSlaried; TSalaried = oggetto(TEmployee); funzione GetPayAmount: reale; virtuale; fine; PCommissionato = ^TCommissioned; TCommissioned = oggetto(stipendiato); Commissione: Reale; Importo delle vendite: reale; costruttore Init(AName, ATitle: String; ARate, ACommissione, AImporto di vendita: Reale); funzione GetPayAmount: reale; virtuale; fine; Un costruttore è un tipo speciale di procedura che esegue alcune operazioni di configurazione per il meccanismo del metodo virtuale. Inoltre, il costruttore deve essere chiamato prima di chiamare qualsiasi metodo virtuale. Chiamare un metodo virtuale senza prima chiamare il costruttore può bloccare il sistema e non c'è modo per il compilatore di controllare l'ordine in cui vengono chiamati i metodi. Ogni tipo di oggetto che ha metodi virtuali deve avere un costruttore. Il costruttore deve essere chiamato prima che venga chiamato qualsiasi altro metodo virtuale. La chiamata di un metodo virtuale senza una precedente chiamata al costruttore può causare un blocco del sistema e il compilatore non può controllare l'ordine in cui vengono chiamati i metodi. 33. Campi dati oggetto e parametri del metodo formale L'implicazione del fatto che i metodi ei loro oggetti condividono un ambito comune è che i parametri formali di un metodo non possono essere identici a nessuno dei campi dati dell'oggetto. Questa non è una nuova limitazione imposta dalla programmazione orientata agli oggetti, ma piuttosto le stesse vecchie regole di ambito che Pascal ha sempre avuto. Questo equivale a vietare che i parametri formali di una procedura siano identici alle variabili locali della procedura. Considera un esempio che illustra questo errore per una procedura: procedura CrunchIt(Crunchee: MyDataRec, Crunchby, Codice di errore: intero); var A, B: carattere; Codice di errore: intero; iniziare . . . fine; Si verifica un errore sulla riga contenente la dichiarazione della variabile locale ErrorCode. Questo perché gli identificatori del parametro formale e della variabile locale sono gli stessi. Le variabili locali di una procedura ei suoi parametri formali condividono un ambito comune e pertanto non possono essere identici. Riceverai un messaggio "Errore 4: identificatore duplicato" se provi a compilare qualcosa del genere. Lo stesso errore si verifica quando si tenta di assegnare un parametro di metodo formale al nome del campo dell'oggetto a cui appartiene questo metodo. Le circostanze sono alquanto diverse, poiché inserire un'intestazione di subroutine all'interno di una struttura dati è un cenno a un'innovazione in Turbo Pascal, ma i principi di base dell'ambito Pascal non sono cambiati. È comunque necessario rispettare una cultura particolare quando si scelgono gli identificatori di variabili e parametri. Alcuni stili di programmazione offrono modi per denominare i campi del tipo per ridurre il rischio di identificatori duplicati. Ad esempio, la notazione ungherese suggerisce che i nomi dei campi inizino con un prefisso "m". 34. Incapsulamento La combinazione di codice e dati in un oggetto è chiamata incapsulamento. In linea di principio, è possibile fornire metodi sufficienti in modo che l'utente di un oggetto non possa mai accedere direttamente ai campi dell'oggetto. Alcuni altri linguaggi orientati agli oggetti, come Smalltalk, richiedono l'incapsulamento obbligatorio, ma Borland Pascal ha una scelta. Ad esempio, gli oggetti TEmployee e THourly sono scritti in modo tale che non sia assolutamente necessario accedere direttamente ai loro campi dati interni: Digitare Temployee = oggetto Nome, Titolo: stringa[25]; Tariffa: Reale; procedura Init(ANome, ATitolo: stringa; Arate: Reale); funzione Ottieni Nome: Stringa; funzione OttieniTitolo: Stringa; funzione GetRate: Reale; funzione GetPayAmount: reale; fine; TOraria = oggetto(Timpiegato) Tempo: intero; procedura Init(ANome, ATitolo: stringa; Arate: Reale, Tempo: Intero); funzione GetPayAmount: reale; fine; Ci sono solo quattro campi di dati qui: nome, titolo, tariffa e ora. I metodi GetName e GetTitle mostrano rispettivamente il cognome e la posizione del lavoratore. Il metodo GetPayAmount utilizza Rate, e nel caso di THourly e Time di lavoro per calcolare l'importo dei pagamenti al lavoro. Non è più necessario fare riferimento direttamente a questi campi di dati. Supponendo l'esistenza di un'istanza AnHourly di tipo THourly, potremmo utilizzare un insieme di metodi per manipolare i campi di dati di AnHourly, in questo modo: con un'ora iniziare Init (Aleksandr Petrov, Operatore di carrelli elevatori' 12.95, 62); {Visualizza il cognome, la posizione e l'importo pagamenti} Mostrare; fine; Va notato che l'accesso ai campi di un oggetto viene effettuato solo con l'aiuto dei metodi di questo oggetto. 35. Oggetti in espansione Se viene definito un tipo derivato, i metodi del tipo padre vengono ereditati, ma possono essere sostituiti se lo si desidera. Per sovrascrivere un metodo ereditato, è sufficiente dichiarare un nuovo metodo con lo stesso nome del metodo ereditato, ma con un corpo diverso e (se necessario) un diverso insieme di parametri. Definiamo un tipo figlio di TEmployee che rappresenta un dipendente a cui viene pagata una tariffa oraria nell'esempio seguente: const PayPeriods = 26; {periodi di pagamento} Soglia straordinari = 80; {per il periodo di pagamento} Fattore straordinari = 1.5; { tariffa oraria } Digitare TOraria = oggetto(Timpiegato) Tempo: intero; procedura Init(ANome, ATitolo: stringa; Arate: Reale, Tempo: Intero); funzione GetPayAmount: reale; fine; procedura THourly.Init(ANome, ATitolo: stringa; Arate: Reale, Tempo: Intero); iniziare TEmployee.Init(ANome, ATitolo, Arate); Ora:= ATime; fine; funzione THourly.GetPayAmount: Real; var Straordinario: Intero; iniziare Straordinario:= Tempo - Soglia Straordinario; se Straordinario > 0 allora GetPayAmount:= RoundPay(Soglia di straordinario * Tariffa + Tasso di lavoro straordinario * Fattore di lavoro straordinario *Valutare) altro GetPayAmount:= RoundPay (tempo * tariffa) fine; Quando si chiama un metodo sottoposto a override, è necessario assicurarsi che il tipo di oggetto derivato includa la funzionalità del genitore. Inoltre, qualsiasi modifica al metodo padre influisce automaticamente su tutti i discendenti. Nota importante: sebbene i metodi possano essere sovrascritti, i campi dati non possono essere sovrascritti. Una volta che un campo dati è stato definito in una gerarchia di oggetti, nessun tipo figlio può definire un campo dati con esattamente lo stesso nome. 36. Compatibilità dei tipi di oggetti L'ereditarietà modifica in una certa misura le regole di compatibilità dei tipi di Borland Pascal. Un discendente eredita la compatibilità di tipo di tutti i suoi antenati. Questa compatibilità di tipo esteso assume tre forme: 1) tra implementazioni di oggetti; 2) tra puntatori a implementazioni di oggetti; 3) tra parametri formali ed effettivi. La compatibilità dei tipi si estende solo dal figlio al genitore. Ad esempio, TSalaried è figlio di TEmployee e TCommissioned è figlio di TSalaried. Considera le seguenti descrizioni: var Un dipendente: TE dipendente; Asalato: Tsalato; PCommissionato: TCommissionato; TEDiployeePtr: ^TEmployee; TSsalariedPtr: ^TSalried; TCommissionedPtr: ^TCommissioned; In queste descrizioni sono validi i seguenti operatori di assegnazione: Un dipendente:=ASalariato; Asalato:= Acommissionato; TCommissionedPtr:= ACommissioned; In generale, la regola di compatibilità dei tipi è formulata come segue: la sorgente deve essere in grado di riempire completamente il ricevitore. I tipi derivati contengono tutto ciò che i loro tipi padre contengono a causa della proprietà dell'ereditarietà. Pertanto, il tipo derivato ha una dimensione non inferiore alla dimensione del genitore. L'assegnazione di un oggetto padre a un oggetto figlio potrebbe lasciare indefiniti alcuni campi dell'oggetto padre, il che è pericoloso e quindi illegale. Nelle istruzioni di assegnazione, solo i campi comuni a entrambi i tipi verranno copiati dall'origine alla destinazione. Nell'operatore di assegnazione: Un dipendente:= Un incaricato; Solo i campi Nome, Titolo e Tasso di ACommissioned verranno copiati in AnEmployee, poiché questi sono gli unici campi condivisi tra TCommissioned e TEmployee. La compatibilità dei tipi funziona anche tra i puntatori ai tipi di oggetti e segue le stesse regole generali delle implementazioni di oggetti. Un puntatore a un figlio può essere assegnato a un puntatore al genitore. Date le definizioni precedenti, sono valide le seguenti assegnazioni di puntatori: TsalariedPtr:= TCommissionedPtr; TEmployeePtr:= TsalariedPtr; TEmployeePtr:= PCommissionedPtr; Un parametro formale (un valore o un parametro variabile) di un determinato tipo di oggetto può assumere come parametro effettivo un oggetto del proprio tipo o oggetti di tutti i tipi figlio. Se definisci un'intestazione di procedura come questa: procedura CalcFedTax(Vittima: Tstipendiato); quindi i tipi di parametro effettivi possono essere Tsalaried o TCommissioned, ma non TEmployee. La vittima può anche essere un parametro variabile. In questo caso si seguono le stesse regole di compatibilità. Il parametro valore è un puntatore all'oggetto effettivo inviato come parametro e il parametro variabile è una copia del parametro effettivo. Questa copia include solo quei campi che fanno parte del tipo del parametro del valore formale. Ciò significa che il parametro effettivo viene convertito nel tipo del parametro formale. 37. Informazioni sull'assemblatore Un tempo l'assembler era un linguaggio senza sapere quale fosse impossibile far fare a un computer qualcosa di utile. A poco a poco la situazione è cambiata. Apparvero mezzi di comunicazione più convenienti con un computer. Ma a differenza di altri linguaggi, l'assembler non è morto; inoltre, non poteva farlo in linea di principio. Come mai? Alla ricerca di una risposta, cercheremo di capire cosa sia il linguaggio assembly in generale. In breve, il linguaggio assembly è una rappresentazione simbolica del linguaggio macchina. Tutti i processi nella macchina al livello hardware più basso sono guidati solo da comandi (istruzioni) del linguaggio macchina. Da ciò risulta chiaro che, nonostante il nome comune, il linguaggio assembly per ogni tipo di computer è diverso. Questo vale anche per l'aspetto dei programmi scritti in assembler e per le idee di cui questo linguaggio riflette. Risolvere davvero problemi relativi all'hardware (o, ancora di più, problemi relativi all'hardware, come accelerare un programma, ad esempio) è impossibile senza la conoscenza dell'assembler. Un programmatore o qualsiasi altro utente può utilizzare qualsiasi strumento di alto livello fino a programmi per la costruzione di mondi virtuali e, forse, nemmeno sospettare che il computer stia effettivamente eseguendo non i comandi del linguaggio in cui è scritto il suo programma, ma la loro rappresentazione trasformata sotto forma di una sequenza noiosa e noiosa di comandi di un linguaggio completamente diverso: il linguaggio macchina. Ora immagina che un tale utente abbia un problema non standard. Ad esempio, il suo programma deve funzionare con un dispositivo insolito o eseguire altre azioni che richiedono la conoscenza dei principi dell'hardware del computer. Non importa quanto sia buono il linguaggio in cui il programmatore ha scritto il suo programma, non può fare a meno di conoscere l'assemblatore. E non è un caso che quasi tutti i compilatori di linguaggi di alto livello contengano mezzi per connettere i propri moduli con moduli in assembler o supportino l'accesso al livello di programmazione assembler. Un computer è composto da diversi dispositivi fisici, ciascuno collegato a una singola unità chiamata unità di sistema. 38. Modello software del microprocessore Nel mercato dei computer di oggi, esiste un'ampia varietà di diversi tipi di computer. Pertanto, è possibile presumere che il consumatore avrà una domanda: come valutare le capacità di un particolare tipo (o modello) di computer e le sue caratteristiche distintive rispetto a computer di altri tipi (modelli). Considerare solo lo schema a blocchi di un computer non è sufficiente per questo, poiché fondamentalmente differisce poco nelle diverse macchine: tutti i computer hanno RAM, un processore e dispositivi esterni. Diversi sono i modi, i mezzi e le risorse utilizzate con cui il computer funziona come un unico meccanismo. Per riunire tutti i concetti che caratterizzano un computer in termini di proprietà funzionali controllate dal programma, esiste un termine speciale: architettura del computer. Per la prima volta, con l'avvento delle macchine di terza generazione, si cominciò a menzionare il concetto di architettura del computer per la loro valutazione comparativa. Ha senso iniziare ad imparare il linguaggio assembly di qualsiasi computer solo dopo aver scoperto quale parte del computer è rimasta visibile e disponibile per la programmazione in questo linguaggio. Questo è il cosiddetto modello di programma per computer, parte del quale è il modello di programma a microprocessore, che contiene 32 registri più o meno disponibili per l'uso da parte del programmatore. Questi registri possono essere divisi in due grandi gruppi: 1) 16 registri utenti; 2) 16 registri di sistema. I programmi in linguaggio assembly utilizzano molto i registri. La maggior parte dei registri ha uno scopo funzionale specifico. Oltre ai registri sopra elencati, gli sviluppatori di processori introducono registri aggiuntivi nel modello software progettato per ottimizzare determinate classi di calcoli. Quindi, nella famiglia di processori Pentium Pro (MMX) di Intel Corporation, è stata introdotta l'estensione MMX di Intel. Include 8 (MM0-MM7) registri a 64 bit e consente di eseguire operazioni su interi su coppie di diversi nuovi tipi di dati: 1) otto byte compressi; 2) quattro parole impacchettate; 3) due parole doppie; 4) parola quadrupla; In altre parole, con un'istruzione di estensione MMX, il programmatore può, ad esempio, aggiungere due parole doppie insieme. Fisicamente non sono stati aggiunti nuovi registri. MM0-MM7 sono le mantisse (64 bit inferiori) di uno stack di registri FPU (unità a virgola mobile - coprocessore) a 80 bit. Inoltre, al momento ci sono le seguenti estensioni del modello di programmazione - 3DNOW! da AMD; SSE, SSE2, SSE3, SSE4. Le ultime 4 estensioni sono supportate da entrambi i processori AMD e Intel. 39. Registri utenti Come suggerisce il nome, i registri utente vengono chiamati perché il programmatore può utilizzarli durante la scrittura dei suoi programmi. Questi registri includono: 1) otto registri a 32 bit che possono essere utilizzati dai programmatori per memorizzare dati e indirizzi (chiamati anche registri di uso generale (RON)): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ pb/pb; ▪ esi/si; ▪ edi/di; ▪ spec. 2) registri a sei segmenti: ▪ cs; ▪ ds; ▪ ss; ▪ es; ▪fs; ▪gs; 3) registri di stato e di controllo: ▪ flag registrano eflags/flags; ▪ registro puntatore comando eip/ip. La figura seguente mostra i registri principali del microprocessore: Registri di uso generale
40. Registri generali Tutti i registri di questo gruppo consentono di accedere alle loro parti "inferiori". Solo le parti inferiori a 16 e 8 bit di questi registri possono essere utilizzate per l'indirizzamento automatico. I 16 bit superiori di questi registri non sono disponibili come oggetti indipendenti. Elenchiamo i registri appartenenti al gruppo dei registri di uso generale. Poiché questi registri si trovano fisicamente nel microprocessore all'interno dell'unità logica aritmetica (ALU), sono anche chiamati registri ALU: 1) eax/ax/ah/al (registro accumulatore) - batteria. Utilizzato per memorizzare dati intermedi. In alcuni comandi è richiesto l'uso di questo registro; 2) ebx/bx/bh/bl (registro di base) - registro di base. Utilizzato per memorizzare l'indirizzo di base di un oggetto in memoria; 3) ecx/cx/ch/cl (Registro di conteggio) - registro di conteggio. Viene utilizzato nei comandi che eseguono alcune azioni ripetitive. Il suo utilizzo è spesso implicito e nascosto nell'algoritmo del comando corrispondente. Ad esempio, il comando di organizzazione del ciclo, oltre a trasferire il controllo a un comando situato a un determinato indirizzo, analizza e decrementa di uno il valore del registro ecx/cx; 4) edx/dx/dh/dl (Registro dati) - registro dati. Proprio come il registro eax/ax/ah/al, memorizza i dati intermedi. Alcuni comandi ne richiedono l'uso; per alcuni comandi questo accade implicitamente. A supporto delle cosiddette operazioni a catena, ovvero operazioni che elaborano sequenzialmente catene di elementi, ciascuna delle quali può avere una lunghezza di 32, 16 o 8 bit, vengono utilizzati i due seguenti registri: 1) esi/si (Source Index register) - indice sorgente. Questo registro nelle operazioni a catena contiene l'indirizzo corrente dell'elemento nella catena di origine; 2) edi/di (Destination Index register) - indice del destinatario (destinatario). Questo registro nelle operazioni a catena contiene l'indirizzo corrente nella catena di destinazione. Nell'architettura del microprocessore a livello hardware e software, è supportata una struttura di dati come uno stack. Per lavorare con lo stack nel sistema di istruzioni del microprocessore ci sono comandi speciali e nel modello software del microprocessore ci sono registri speciali per questo: 1) esp/sp (registro del puntatore dello stack) - registro del puntatore dello stack. Contiene un puntatore all'inizio dello stack nel segmento dello stack corrente. 2) ebp/bp (registro del puntatore di base) - registro del puntatore di base dello stack frame. Progettato per organizzare l'accesso casuale ai dati all'interno dello stack. L'uso dell'hard pinning dei registri per alcune istruzioni consente di codificare la loro rappresentazione della macchina in modo più compatto. Conoscere queste caratteristiche consentirà, se necessario, di risparmiare almeno alcuni byte di memoria occupata dal codice del programma. 41. Registri di settore Ci sono sei registri di segmento nel modello software del microprocessore: cs, ss, ds, es, gs, fs. La loro esistenza è dovuta alle specificità dell'organizzazione e dell'uso della RAM da parte dei microprocessori Intel. Sta nel fatto che l'hardware del microprocessore supporta l'organizzazione strutturale del programma sotto forma di tre parti, chiamate segmenti. Di conseguenza, una tale organizzazione della memoria è chiamata segmentata. Per indicare i segmenti a cui il programma ha accesso in un determinato momento, si intendono i registri di segmento. Infatti (con una leggera correzione) questi registri contengono gli indirizzi di memoria da cui iniziano i segmenti corrispondenti. La logica dell'elaborazione di un'istruzione macchina è costruita in modo tale che quando si preleva un'istruzione, si accede ai dati del programma o si accede allo stack, vengano utilizzati implicitamente indirizzi in registri di segmento ben definiti. Il microprocessore supporta i seguenti tipi di segmenti. 1. Segmento di codice. Contiene i comandi del programma. Per accedere a questo segmento, viene utilizzato il registro cs (registro del segmento di codice), il registro del codice del segmento. Contiene l'indirizzo del segmento di istruzione della macchina a cui ha accesso il microprocessore (ovvero, queste istruzioni vengono caricate nella pipeline del microprocessore). 2. Segmento di dati. Contiene i dati elaborati dal programma. Per accedere a questo segmento, viene utilizzato il registro ds (data segment register), un registro di dati di segmento che memorizza l'indirizzo del segmento di dati del programma corrente. 3. Segmento di impilamento. Questo segmento è una regione di memoria chiamata stack. Il microprocessore organizza il lavoro con lo stack secondo il seguente principio: viene selezionato per primo l'ultimo elemento scritto in quest'area. Per accedere a questo segmento viene utilizzato il registro ss (stack segment register), lo stack segment register contenente l'indirizzo del segmento stack. 4. Segmento dati aggiuntivo. Implicitamente, gli algoritmi per l'esecuzione della maggior parte delle istruzioni macchina presuppongono che i dati che elaborano si trovino nel segmento di dati, il cui indirizzo è nel registro del segmento ds. Se un segmento di dati non è sufficiente per il programma, ha l'opportunità di utilizzare altri tre segmenti di dati aggiuntivi. Ma a differenza del segmento di dati principale, il cui indirizzo è contenuto nel registro del segmento ds, quando si utilizzano segmenti di dati aggiuntivi, i loro indirizzi devono essere specificati in modo esplicito utilizzando speciali prefissi di ridefinizione del segmento nel comando. Gli indirizzi di segmenti di dati aggiuntivi devono essere contenuti nei registri es, gs, fs (extension data segment registers). 42. Registri di stato e di controllo Il microprocessore include diversi registri che contengono costantemente informazioni sullo stato sia del microprocessore stesso che del programma le cui istruzioni sono attualmente caricate nella pipeline. Questi registri includono: 1) flag eflags/flags del registro; 2) registro puntatore comando eip/ip. Utilizzando questi registri è possibile ottenere informazioni sui risultati dell'esecuzione del comando e influenzare lo stato del microprocessore stesso. Consideriamo più in dettaglio lo scopo e il contenuto di questi registri. 1. eflags/flags (flag register) - flag register. La profondità di bit di eflags/flags è 32/16 bit. I singoli bit di questo registro hanno uno scopo funzionale specifico e sono chiamati flag. La parte inferiore di questo registro è completamente analoga al registro dei flag per i8086. A seconda di come vengono utilizzati, i flag del registro eflags/flags possono essere suddivisi in tre gruppi: 1) otto flag di stato. Questi flag possono cambiare dopo che le istruzioni della macchina sono state eseguite. I flag di stato del registro eflags riflettono le specifiche del risultato dell'esecuzione di operazioni aritmetiche o logiche. Ciò rende possibile analizzare lo stato del processo computazionale e rispondere ad esso utilizzando comandi di salto condizionale e chiamate di subroutine. 2) un flag di controllo. Denotato df (flag della directory). Si trova nel bit 10 del registro eflags ed è usato da comandi concatenati. Il valore del flag df determina la direzione dell'elaborazione elemento per elemento in queste operazioni: dall'inizio della stringa alla fine (df = 0) o viceversa, dalla fine della stringa al suo inizio (df = 1). Esistono comandi speciali per lavorare con il flag df: cld (rimuove il flag df) e std (imposta il flag df). L'uso di questi comandi consente di regolare il flag df in base all'algoritmo e garantire che i contatori vengano automaticamente incrementati o decrementati durante l'esecuzione di operazioni sulle stringhe. 3) cinque flag di sistema. Controlla l'I/O, gli interrupt mascherabili, il debug, il cambio di attività e la modalità virtuale 8086. Non è consigliabile che i programmi applicativi modifichino questi flag inutilmente, poiché ciò causerebbe l'arresto del programma nella maggior parte dei casi. 2. eip/ip (Instraction Pointer register) - registro del puntatore dell'istruzione. Il registro eip/ip è largo 32/16 bit e contiene l'offset dell'istruzione successiva da eseguire rispetto al contenuto del registro del segmento cs nel segmento dell'istruzione corrente. Questo registro non è direttamente accessibile al programmatore, ma il suo valore viene caricato e modificato da vari comandi di controllo, che includono comandi per salti condizionali e incondizionati, chiamate di procedure e ritorno dalle procedure. Il verificarsi di interrupt modifica anche il registro eip/ip. 43. Registri di sistema a microprocessore Il nome stesso di questi registri suggerisce che svolgono funzioni specifiche nel sistema. L'uso dei registri di sistema è rigorosamente regolamentato. Sono loro che forniscono la modalità protetta. Possono anche essere considerati come parte dell'architettura del microprocessore, che viene lasciata deliberatamente visibile in modo che un programmatore di sistema qualificato possa eseguire le operazioni di livello più basso. I registri di sistema possono essere suddivisi in tre gruppi: 1) quattro registri di controllo; Il gruppo dei registri di controllo comprende 4 registri: ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) quattro registri di indirizzi di sistema (detti anche registri di gestione della memoria); I registri degli indirizzi di sistema includono i seguenti registri: ▪ registro della tabella descrittore globale gdtr; ▪ registro delle tabelle descrittori locali Idtr; ▪ registro della tabella descrittore degli interrupt idtr; ▪ Registro attività a 16 bit tr; 3) otto registri di debug. Questi includono: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dott7. La conoscenza dei registri di sistema non è necessaria per scrivere programmi in Assembler, in quanto vengono utilizzati principalmente per le operazioni di livello più basso. Tuttavia, le tendenze attuali nello sviluppo del software (soprattutto alla luce delle capacità di ottimizzazione significativamente aumentate dei moderni compilatori di linguaggi di alto livello, che spesso generano codice con un'efficienza superiore al codice umano) stanno restringendo l'ambito di Assembler alla risoluzione dei problemi più bassi problemi di livello, dove la conoscenza dei suddetti registri può rivelarsi molto utile. 44. Registri di controllo Il gruppo di registri di controllo comprende quattro registri: cr0, cr1, cr2, cr3. Questi registri servono per il controllo generale del sistema. I registri di controllo sono disponibili solo per i programmi con livello di privilegio 0. Sebbene il microprocessore abbia quattro registri di controllo, ne sono disponibili solo tre - è escluso cr1, le cui funzioni non sono ancora definite (è riservato per usi futuri). Il registro cr0 contiene flag di sistema che controllano le modalità di funzionamento del microprocessore e ne riflettono lo stato a livello globale, indipendentemente dai compiti specifici eseguiti. Scopo dei flag di sistema: 1) pe (Abilitazione protezione), bit 0 - abilita la modalità protetta. Lo stato di questo flag indica in quale delle due modalità - reale (pe = 0) o protetta (pe = 1) - il microprocessore sta funzionando in un dato momento; 2) mp (Math Present), bit 1 - la presenza di un coprocessore. Sempre 1; 3) ts (Task Switched), bit 3 - cambio attività. Il processore imposta automaticamente questo bit quando passa a un'altra attività; 4) am (Maschera di allineamento), bit 18 - maschera di allineamento. Questo bit abilita (am = 1) o disabilita (am = 0) il controllo dell'allineamento; 5) cd (Cache Disable), bit 30 - disabilita la memoria cache. Utilizzando questo bit è possibile disabilitare (cd = 1) o abilitare (cd = 0) l'utilizzo della cache interna (la cache di primo livello); 6) pg (PaGing), bit 31 - abilita (pg = 1) o disabilita (pg = 0) il paging. Il flag viene utilizzato nel modello di paging dell'organizzazione della memoria. Il registro cr2 viene utilizzato nella paginazione RAM per registrare la situazione in cui l'istruzione corrente ha avuto accesso all'indirizzo contenuto in una pagina di memoria che attualmente non è in memoria. In una tale situazione, nel microprocessore si verifica un numero di eccezione 14 e l'indirizzo lineare a 32 bit dell'istruzione che ha causato questa eccezione viene scritto nel registro cr2. Con queste informazioni, il gestore di eccezioni 14 determina la pagina desiderata, la scambia in memoria e riprende il normale funzionamento del programma; Il registro cr3 viene utilizzato anche per la memoria di paging. Questo è il cosiddetto registro delle directory delle pagine di primo livello. Contiene l'indirizzo di base fisico a 20 bit della directory della pagina dell'attività corrente. Questa directory contiene 1024 descrittori a 32 bit, ognuno dei quali contiene l'indirizzo della tabella delle pagine di secondo livello. A sua volta, ciascuna delle tabelle di pagina di secondo livello contiene 1024 descrittori a 32 bit che indirizzano i frame di pagina in memoria. La dimensione del frame della pagina è di 4 KB. 45. Registri degli indirizzi di sistema Questi registri sono anche chiamati registri di gestione della memoria. Sono progettati per proteggere programmi e dati nella modalità multitasking del microprocessore. Quando si opera in modalità protetta da microprocessore, lo spazio degli indirizzi è suddiviso in: 1) globale - comune a tutti i compiti; 2) locale: separato per ogni attività. Questa divisione spiega la presenza dei seguenti registri di sistema nell'architettura del microprocessore: 1) il registro della tabella dei descrittori globali gdtr (Global Descriptor Table Register), avente una dimensione di 48 bit e contenente un indirizzo di base a 32 bit (bit 16-47) della tabella dei descrittori globali GDT e uno a 16 bit (bit 0-15) valore limite, che è la dimensione in byte della tabella GDT; 2) il registro della tabella dei descrittori locali ldtr (Local Descriptor Table Register), avente una dimensione di 16 bit e contenente il cosiddetto selettore dei descrittori della tabella dei descrittori locali LDT. Questo selettore è un puntatore al GDT che descrive il segmento contenente la tabella dei descrittori locali LDT; 3) il registro della tabella dei descrittori di interrupt idtr (Interrupt Descriptor Table Register), avente una dimensione di 48 bit e contenente un indirizzo di base a 32 bit (bit 16-47) della tabella dei descrittori di interrupt IDT e uno a 16 bit (bit 0-15) valore limite, che è la dimensione in byte della tabella IDT; 4) Registro attività a 16 bit tr (Registro attività), che, come il registro ldtr, contiene un selettore, ovvero un puntatore a un descrittore nella tabella GDT. Questo descrittore descrive l'attuale stato del segmento di attività (TSS). Questo segmento viene creato per ogni attività nel sistema, ha una struttura rigorosamente regolamentata e contiene il contesto (stato corrente) dell'attività. Lo scopo principale dei segmenti TSS è salvare lo stato corrente di un'attività al momento del passaggio a un'altra attività. 46. Registro di debug Questo è un gruppo molto interessante di registri destinati al debug hardware. Gli strumenti di debug hardware sono apparsi per la prima volta nel microprocessore i486. Nell'hardware, il microprocessore contiene otto registri di debug, ma solo sei di essi vengono effettivamente utilizzati. I registri dr0, dr1, dr2, dr3 hanno una larghezza di 32 bit e sono progettati per impostare gli indirizzi lineari di quattro breakpoint. Il meccanismo utilizzato in questo caso è il seguente: qualsiasi indirizzo generato dal programma corrente viene confrontato con gli indirizzi nei registri dr0... dr3 e, se c'è corrispondenza, viene generata un'eccezione di debug con il numero 1. Il registro dr6 è chiamato registro dello stato di debug. I bit in questo registro vengono impostati in base ai motivi che hanno causato il verificarsi dell'ultima eccezione numero 1. Elenchiamo questi bit e il loro scopo: 1) b0 - se questo bit è impostato a 1, si è verificata l'ultima eccezione (interruzione) a seguito del raggiungimento del checkpoint definito nel registro dr0; 2) b1 - simile a b0, ma per un checkpoint nel registro dr1; 3) b2 - simile a b0, ma per un checkpoint nel registro dr2; 4) b3 - simile a b0, ma per un checkpoint nel registro dr3; 5) bd (bit 13) - serve a proteggere i registri di debug; 6) bs (bit 14) - impostato a 1 se l'eccezione 1 è stata causata dallo stato del flag tf = 1 nel registro eflags; 7) bt (bit 15) è impostato su 1 se l'eccezione 1 è stata causata da un passaggio a un task con il bit trap impostato in TSS t = 1. Tutti gli altri bit in questo registro sono riempiti con zeri. Il gestore delle eccezioni 1, in base al contenuto di dr6, deve determinare il motivo per cui si è verificata l'eccezione e intraprendere le azioni necessarie. Il registro dr7 è chiamato registro di controllo di debug. Contiene campi per ciascuno dei quattro registri del punto di interruzione di debug che consentono di specificare le seguenti condizioni in base alle quali deve essere generato un interrupt: 1) posizione di registrazione del checkpoint - solo nell'attività corrente o in qualsiasi attività. Questi bit occupano gli 8 bit inferiori del registro dr7 (2 bit per ogni punto di interruzione (in realtà un punto di interruzione) impostato dai registri dr0, drl, dr2, dr3, rispettivamente). Il primo bit di ogni coppia è la cosiddetta risoluzione locale; l'impostazione indica che il punto di interruzione ha effetto se si trova all'interno dello spazio degli indirizzi dell'attività corrente. Il secondo bit in ogni coppia specifica l'autorizzazione globale, che indica che il punto di interruzione specificato è valido all'interno degli spazi degli indirizzi di tutte le attività nel sistema; 2) il tipo di accesso con cui viene avviato l'interrupt: solo durante il recupero di un comando, durante la scrittura o durante la scrittura/lettura di dati. I bit che determinano questa natura del verificarsi di un interrupt si trovano nella parte superiore di questo registro. La maggior parte dei registri di sistema sono accessibili a livello di codice. 47. La struttura del programma in assembler Un programma in linguaggio assembly è una raccolta di blocchi di memoria chiamati segmenti di memoria. Un programma può essere costituito da uno o più di questi segmenti di blocco. Ogni segmento contiene una raccolta di frasi linguistiche, ognuna delle quali occupa una riga separata di codice del programma. Le istruzioni di assemblaggio sono di quattro tipi. Comandi o istruzioni che sono controparti simboliche di istruzioni macchina. Durante il processo di traduzione, le istruzioni di assemblaggio vengono convertite nei comandi corrispondenti del set di istruzioni del microprocessore. Un'istruzione Assembler, di regola, corrisponde a un'istruzione del microprocessore, che, in generale, è tipica dei linguaggi di basso livello. Ecco un esempio di un'istruzione che incrementa di uno il numero binario memorizzato nel registro eax: inc ▪ macrocomandi - frasi di testo del programma formattate in un certo modo, sostituite durante la trasmissione da altre frasi. Un esempio di macro è la seguente macro di fine programma: macro di uscita movax,4c00h Int 21h endm ▪ direttive, che sono istruzioni al traduttore assemblatore per eseguire determinate azioni. Le direttive non hanno controparti nella rappresentazione della macchina; Ad esempio, ecco la direttiva TITLE che imposta il titolo del file di elenco: %TITLE "Listing 1" ▪ righe di commento contenenti qualsiasi carattere, comprese le lettere dell'alfabeto russo. I commenti vengono ignorati dal traduttore. Esempio: ; questa riga è un commento 48. Sintassi dell'Assemblea Le frasi che compongono un programma possono essere un costrutto sintattico corrispondente a un comando, una macro, una direttiva o un commento. Affinché il traduttore assembler possa riconoscerli, devono essere formati secondo determinate regole sintattiche. Per fare ciò, è meglio utilizzare una descrizione formale della sintassi della lingua, come le regole della grammatica. I modi più comuni per descrivere un linguaggio di programmazione in questo modo sono i diagrammi di sintassi e le forme estese di Backus-Naur. Quando si lavora con i diagrammi di sintassi, prestare attenzione alla direzione di attraversamento, indicata dalle frecce. I diagrammi di sintassi riflettono la logica del traduttore durante l'analisi delle frasi di input del programma. Caratteri validi: 1) tutte le lettere latine: A - Z, a - z; 2) numeri da 0 a 9; 3) segni? @, $, &; 4) separatori. I token sono i seguenti. 1. Identificatori: sequenze di caratteri validi utilizzati per designare codici operazione, nomi di variabili e nomi di etichette. Un identificatore non può iniziare con un numero. 2. Catene di caratteri - sequenze di caratteri racchiuse tra virgolette singole o doppie. 3. Numeri interi. Possibili tipi di istruzioni assembler. 1. Operatori aritmetici. Questi includono: 1) "+" e "-" unari; 2) binari "+" e "-"; 3) moltiplicazione "*"; 4) divisione intera "/"; 5) ottenere il resto della divisione “mod”. 2. Gli operatori Shift spostano l'espressione del numero di bit specificato. 3. Gli operatori di confronto (restituiscono "true" o "false") sono progettati per formare espressioni logiche. 4. Gli operatori logici eseguono operazioni bit per bit sulle espressioni. 5. Operatore indice []. 6. L'operatore di ridefinizione del tipo ptr viene utilizzato per ridefinire o qualificare il tipo di etichetta o variabile definita da un'espressione. 7. L'operatore di ridefinizione del segmento ":" (due punti) determina il calcolo dell'indirizzo fisico relativo al componente del segmento specificato. 8. Operatore di denominazione del tipo di struttura "." (punto) fa anche in modo che il compilatore esegua determinati calcoli se si verificano in un'espressione. 9. L'operatore per ottenere il componente del segmento dell'indirizzo dell'espressione seg restituisce l'indirizzo fisico del segmento per l'espressione, che può essere un'etichetta, una variabile, un nome di segmento, un nome di gruppo o un nome simbolico. 10. L'operatore per ottenere l'offset dell'espressione offset consente di ottenere il valore dell'offset dell'espressione in byte relativo all'inizio del segmento in cui è definita l'espressione. 49. Direttive di segmentazione La segmentazione fa parte di un meccanismo più generale legato al concetto di programmazione modulare. Implica l'unificazione della progettazione dei moduli oggetto creati dal compilatore, compresi quelli provenienti da diversi linguaggi di programmazione. Ciò consente di combinare programmi scritti in diverse lingue. È per l'implementazione di varie opzioni per tale unione che sono destinati gli operandi nella direttiva SEGMENT. Consideriamoli in modo più dettagliato. 1. L'attributo di allineamento del segmento (tipo di allineamento) indica al linker di assicurarsi che l'inizio del segmento sia posizionato sul limite specificato: 1) BYTE - l'allineamento non viene eseguito; 2) WORD - il segmento parte da un indirizzo multiplo di due, ovvero l'ultimo bit (meno significativo) dell'indirizzo fisico è 0 (allineato al limite della parola); 3) DWORD - il segmento inizia con un indirizzo multiplo di quattro; 4) PARA - il segmento parte da un indirizzo multiplo di 16; 5) PAGINA - il segmento parte da un indirizzo multiplo di 256; 6) MAMPAGE - il segmento parte da un indirizzo multiplo di 4 KB. 2. L'attributo combina segmento (tipo combinatorio) indica al linker come combinare segmenti di moduli diversi che hanno lo stesso nome: 1) PRIVATO - il segmento non sarà unito ad altri segmenti con lo stesso nome al di fuori di questo modulo; 2) PUBLIC - forza il linker a collegare tutti i segmenti con lo stesso nome; 3) COMUNE - ha tutti i segmenti con lo stesso nome allo stesso indirizzo; 4) AT xxxx - individua il segmento all'indirizzo assoluto del paragrafo; 5) STACK - definizione di un segmento di stack. 3. Un attributo di classe di segmento (tipo di classe) è una stringa tra virgolette che aiuta il linker a determinare l'ordine di segmento appropriato quando si assembla un programma da più segmenti di modulo. 4. Attributo della dimensione del segmento: 1) USE16 - significa che il segmento consente l'indirizzamento a 16 bit; 2) USE32 - il segmento sarà a 32 bit. Ci deve essere un modo per compensare l'impossibilità. controllare direttamente il posizionamento e la combinazione dei segmenti. Per fare ciò, hanno iniziato a utilizzare la direttiva per specificare il modello di memoria MODEL. Questa direttiva associa i segmenti, che nel caso di utilizzo di direttive di segmentazione semplificate, hanno nomi predefiniti, con registri di segmento (sebbene sia comunque necessario inizializzare ds in modo esplicito). Il parametro obbligatorio della direttiva MODEL è il modello di memoria. Questo parametro definisce il modello di segmentazione della memoria per la POU. Si presume che un modulo di programma possa avere solo determinati tipi di segmenti, che sono definiti dalle direttive di descrizione del segmento semplificata che abbiamo menzionato in precedenza. 50. Struttura delle istruzioni della macchina Un comando macchina è un'indicazione al microprocessore, codificato secondo determinate regole, di eseguire qualche operazione o azione. Ogni comando contiene elementi che definiscono: 1) cosa fare? 2) oggetti su cui è necessario fare qualcosa (questi elementi sono chiamati operandi); 3) come fare? La lunghezza massima di un'istruzione macchina è 15 byte. 1. Prefissi. Elementi opzionali dell'istruzione macchina, ciascuno dei quali è di 1 byte o può essere omesso. In memoria, i prefissi precedono il comando. Lo scopo dei prefissi è modificare l'operazione eseguita dal comando. Un'applicazione può utilizzare i seguenti tipi di prefissi: 1) prefisso di sostituzione del segmento; 2) il prefisso della lunghezza in bit dell'indirizzo specifica la lunghezza in bit dell'indirizzo (32 bit o 16 bit); 3) il prefisso della lunghezza del bit dell'operando è simile al prefisso della lunghezza del bit dell'indirizzo, ma indica la lunghezza del bit dell'operando (32 bit o 16 bit) con cui funziona il comando; 4) Il prefisso di ripetizione viene utilizzato con i comandi concatenati. 2. Codice operazione. Elemento obbligatorio che descrive l'operazione eseguita dal comando. 3. Modalità di indirizzamento byte modr/m. Il valore di questo byte determina il modulo di indirizzo dell'operando utilizzato. Gli operandi possono essere in memoria in uno o due registri. Se l'operando è in memoria, il byte modr/m specifica i componenti (registri offset, base e indice) utilizzato per calcolare il suo indirizzo effettivo. Il byte modr/m è composto da tre campi: 1) il campo mod determina il numero di byte occupati nell'istruzione dall'indirizzo dell'operando; 2) il campo reg/cop determina o il registro che si trova nel comando al posto del primo operando, oppure un'eventuale estensione dell'opcode; 3) il campo r/m viene utilizzato insieme al campo mod e determina o il registro che si trova nel comando al posto del primo operando (se mod = 11), oppure i registri di base e indice utilizzati per calcolare l'indirizzo effettivo ( insieme al campo offset nel comando). 4. Scala byte - indice - base (byte sib). Utilizzato per espandere le possibilità di indirizzare gli operandi. Il byte sib è composto da tre campi: 1) scala campi ss. Questo campo contiene il fattore di scala per l'indice del componente dell'indice, che occupa i successivi 3 bit del byte sib; 2) campi indice. Utilizzato per memorizzare il numero di registro dell'indice utilizzato per calcolare l'indirizzo effettivo dell'operando; 3) campi base. Utilizzato per memorizzare il numero di registro di base, utilizzato anche per calcolare l'indirizzo effettivo dell'operando. 5. Campo di offset al comando. Un intero con segno a 8, 16 o 32 bit che rappresenta, in tutto o in parte (fatte salve le considerazioni precedenti), il valore dell'indirizzo effettivo dell'operando. 6. Il campo dell'operando immediato. Un campo opzionale che rappresenta 8-, Operando immediato a 16 o 32 bit. La presenza di questo campo si riflette, ovviamente, nel valore del byte modr/m. 51. Metodi per specificare gli operandi di istruzione L'operando è impostato implicitamente a livello di firmware In questo caso, l'istruzione non contiene esplicitamente operandi. L'algoritmo di esecuzione dei comandi utilizza alcuni oggetti predefiniti (registri, flag in eflags, ecc.). L'operando è specificato nell'istruzione stessa (operando immediato) L'operando è nel codice dell'istruzione, cioè ne fa parte. Per memorizzare un tale operando, nell'istruzione viene allocato un campo lungo fino a 32 bit. L'operando immediato può essere solo il secondo operando (sorgente). L'operando di destinazione può essere in memoria o in un registro. L'operando si trova in uno dei registri Gli operandi dei registri sono specificati dai nomi dei registri. I registri possono essere utilizzati: 1) Registri a 32 bit EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP; 2) registri a 16 bit AX, BX, CX, DX, SI, DI, SP, BP; 3) Registri a 8 bit AH, AL, BH, BL, CH, CL, DH, DL; 4) registri di segmento CS, DS, SS, ES, FS, GS. Ad esempio, il comando add ax,bx aggiunge il contenuto dei registri ax e bx e scrive il risultato in bx. Il comando dec si decrementa il contenuto di si di 1. L'operando è in memoria Questo è il modo più complesso e allo stesso tempo più flessibile per specificare gli operandi. Consente di implementare i seguenti due principali tipi di indirizzamento: diretto e indiretto. A sua volta, l'indirizzamento indiretto ha le seguenti varietà: 1) indirizzamento di base indiretto; l'altro nome è l'indirizzo indiretto del registro; 2) indirizzamento di base indiretto con offset; 3) indirizzamento indiretto di indice con offset; 4) indirizzamento indiretto dell'indice di base; 5) indirizzamento indiretto dell'indice di base con offset. L'operando è una porta I/O Oltre allo spazio degli indirizzi della RAM, il microprocessore mantiene uno spazio degli indirizzi I/O, che viene utilizzato per accedere ai dispositivi I/O. Lo spazio degli indirizzi di I/O è 64 KB. Gli indirizzi vengono allocati per qualsiasi dispositivo del computer in questo spazio. Un particolare valore di indirizzo all'interno di questo spazio è chiamato porta I/O. Fisicamente, la porta I/O corrisponde ad un registro hardware (da non confondere con un registro a microprocessore), al quale si accede tramite apposite istruzioni assembler in entrata e in uscita. L'operando è nello stack Le istruzioni possono non avere alcun operandi, possono avere uno o due operandi. La maggior parte delle istruzioni richiede due operandi, uno dei quali è l'operando di origine e l'altro è l'operando di destinazione. È importante che un operando possa trovarsi in un registro o in una memoria e il secondo operando deve trovarsi in un registro o direttamente nell'istruzione. Un operando immediato può essere solo un operando sorgente. In un'istruzione macchina a due operandi sono possibili le seguenti combinazioni di operandi: 1) registrarsi - registrarsi; 2) registro - memoria; 3) memoria - registro; 4) operando immediato - registro; 5) operando immediato - memoria. 52. Modalità di indirizzamento Indirizzamento diretto Questa è la forma più semplice per indirizzare un operando in memoria, poiché l'indirizzo effettivo è contenuto nell'istruzione stessa e non vengono utilizzate fonti o registri aggiuntivi per formarlo. L'indirizzo effettivo viene prelevato direttamente dal campo di offset dell'istruzione macchina, che può essere di 8, 16, 32 bit. Questo valore identifica in modo univoco il byte, la parola o la doppia parola che si trova nel segmento di dati. L'indirizzamento diretto può essere di due tipi. Indirizzamento diretto relativo Utilizzato per istruzioni di salto condizionato per indicare l'indirizzo di salto relativo. La relatività di tale transizione sta nel fatto che il campo di offset dell'istruzione macchina contiene un valore di 8, 16 o 32 bit, che, a seguito del funzionamento dell'istruzione, verrà aggiunto al contenuto di il registro del puntatore dell'istruzione ip/eip. Come risultato di questa aggiunta, si ottiene l'indirizzo, al quale viene effettuata la transizione. Indirizzamento diretto assoluto In questo caso, l'indirizzo effettivo fa parte dell'istruzione macchina, ma questo indirizzo è formato solo dal valore del campo offset nell'istruzione. Per formare l'indirizzo fisico dell'operando in memoria, il microprocessore aggiunge questo campo con il valore del registro di segmento spostato di 4 bit. Diverse forme di questo indirizzamento possono essere utilizzate in un'istruzione assembler. Indirizzamento di base indiretto (registro). Con questo indirizzamento, l'indirizzo effettivo dell'operando può trovarsi in uno qualsiasi dei registri di uso generale, ad eccezione di sp / esp e bp / ebp (questi sono registri specifici per lavorare con un segmento di stack). Sintatticamente in un comando, questa modalità di indirizzamento è espressa racchiudendo il nome del registro tra parentesi quadre []. Indirizzamento di base (registro) indiretto con offset Questo tipo di indirizzamento è un'aggiunta al precedente ed è progettato per accedere a dati con un offset noto rispetto a un indirizzo di base. Questo tipo di indirizzamento è conveniente da utilizzare per accedere agli elementi delle strutture dati, quando l'offset degli elementi è noto in anticipo, in fase di sviluppo del programma, e l'indirizzo di base (di partenza) della struttura deve essere calcolato dinamicamente, a la fase di esecuzione del programma. Indirizzamento indiretto con offset Questo tipo di indirizzamento è molto simile all'indirizzamento di base indiretto con un offset. Anche in questo caso, uno dei registri di uso generale viene utilizzato per formare l'indirizzo effettivo. Ma l'indirizzamento degli indici ha una caratteristica interessante che è molto comoda per lavorare con gli array. È connesso con la possibilità del cosiddetto ridimensionamento dei contenuti del registro indice. Indirizzamento indiretto dell'indice di base Con questo tipo di indirizzamento, l'indirizzo effettivo è formato dalla somma del contenuto di due registri generici: base e indice. Questi registri possono essere qualsiasi registro generico e viene spesso utilizzato il ridimensionamento del contenuto di un registro indice. Indirizzamento indiretto dell'indice di base con offset Questo tipo di indirizzamento è il complemento dell'indirizzamento indiretto. L'indirizzo effettivo è formato dalla somma di tre componenti: il contenuto del registro di base, il contenuto del registro di indice e il valore del campo offset nel comando. 53. Comandi di trasferimento dati Comandi generali di trasferimento dati Questo gruppo include i seguenti comandi: 1) mov è il principale comando di trasferimento dati; 2) xchg - utilizzato per il trasferimento dati bidirezionale. Comandi porta I/O Fondamentalmente, gestire i dispositivi direttamente tramite le porte è semplice: 1) nell'accumulatore, numero di porta - ingresso nell'accumulatore dalla porta con il numero di porta; 2) out port, accumulator - invia il contenuto dell'accumulatore alla porta con il numero di porta. Comandi di conversione dei dati Molte istruzioni del microprocessore possono essere attribuite a questo gruppo, ma la maggior parte di esse ha determinate caratteristiche che richiedono che siano attribuite ad altri gruppi funzionali. Comandi in pila Questo gruppo è un insieme di comandi specializzati incentrati sull'organizzazione di un lavoro flessibile ed efficiente con lo stack. Lo stack è un'area di memoria appositamente allocata per la memorizzazione temporanea dei dati del programma. Lo stack ha tre registri: 1) ss - registro del segmento dello stack; 2) sp/esp - registro del puntatore dello stack; 3) bp/ebp - registro del puntatore di base dello stack frame. Per organizzare il lavoro con lo stack, ci sono comandi speciali per la scrittura e la lettura. 1. push source: scrive il valore sorgente in cima allo stack. 2. assegnazione pop: scrive il valore dalla cima dello stack alla posizione specificata dall'operando di destinazione. Il valore viene quindi "rimosso" dalla cima dello stack. 3. pusha - un comando di scrittura di gruppo nello stack. 4. pushaw è quasi sinonimo del comando pusha. L'attributo bitness può essere use16 o use32. R 5. pushad - eseguito in modo simile al comando pusha, ma ci sono alcune particolarità. I tre comandi seguenti eseguono il contrario dei comandi precedenti: 1) papa; 2) popo; 3) schiocco. Il gruppo di istruzioni descritto di seguito consente di salvare il registro flag nello stack e di scrivere una parola o una doppia parola nello stack. 1. pushf - salva il registro dei flag nello stack. 2. pushfw: salva un registro di flag delle dimensioni di una parola sullo stack. Funziona sempre come pushf con l'attributo use16. 3. pushfd - salvataggio dei flag o dei flag eflags registrati sullo stack a seconda dell'attributo di larghezza di bit del segmento (cioè lo stesso di pushf). Allo stesso modo, i seguenti tre comandi eseguono il contrario delle operazioni discusse sopra: 1) popf; 2) pop; 3) popfd. 54. Istruzioni aritmetiche Tali comandi funzionano con due tipi: 1) numeri binari interi, cioè con numeri codificati nel sistema numerico binario. I numeri decimali sono un tipo speciale di rappresentazione di informazioni numeriche, che si basa sul principio di codificare ogni cifra decimale di un numero con un gruppo di quattro bit. Il microprocessore esegue l'addizione di operandi secondo le regole per l'addizione di numeri binari. Ci sono tre istruzioni di addizione binaria nel set di istruzioni del microprocessore: 1) operando inc - aumenta il valore dell'operando; 2) aggiungi operando1, operando2 - addizione; 3) adc operando1, operando2 - addizione, tenendo conto del carry flag cfr. Sottrazione di numeri binari senza segno Se il minuendo è maggiore del sottraendo, la differenza è positiva. Se il minuendo è minore del sottratto, c'è un problema: il risultato è minore di 0, e questo è già un numero con segno. Dopo aver sottratto i numeri senza segno, è necessario analizzare lo stato del flag CF. Se è impostato su 1, il bit più significativo è stato preso in prestito e il risultato è nel codice del complemento a due. Sottrazione di numeri binari con un segno Ma per la sottrazione mediante l'addizione di numeri con un segno in un codice aggiuntivo, è necessario rappresentare entrambi gli operandi, sia il minuendo che il sottraendo. Il risultato dovrebbe anche essere considerato come un valore di complemento a due. Ma qui sorgono le difficoltà. Innanzitutto, sono legati al fatto che il bit più significativo dell'operando è considerato un bit di segno. Secondo il contenuto della bandiera di overflow di. Impostandolo su 1 indica che il risultato è fuori dall'intervallo di numeri con segno (ovvero, il bit più significativo è cambiato) per un operando di queste dimensioni e il programmatore deve agire per correggere il risultato. Il principio della sottrazione di numeri con un intervallo di rappresentazione superiore alle griglie di bit degli operandi standard è lo stesso dell'addizione, ovvero viene utilizzato il flag di riporto cf. Devi solo immaginare il processo di sottrazione in una colonna e combinare correttamente le istruzioni del microprocessore con l'istruzione sbb. Il comando per moltiplicare i numeri senza segno è fattore multi_1 Il comando per moltiplicare i numeri con un segno è [imul operando_1, operando_2, operando_3] Il comando div divisore serve per dividere i numeri senza segno. Il comando idiv divisore serve per dividere i numeri con segno. 55. Comandi logici Secondo la teoria, le seguenti operazioni logiche possono essere eseguite su istruzioni (su bit). 1. Negazione (NOT logico) - un'operazione logica su un operando, il cui risultato è il reciproco del valore dell'operando originale. 2. Addizione logica (OR logico inclusivo): un'operazione logica su due operandi, il cui risultato è "vero" (1) se uno o entrambi gli operandi sono veri (1) e "falso" (0) se entrambi gli operandi sono falso (0). 3. Moltiplicazione logica (AND logico) - un'operazione logica su due operandi, il cui risultato è vero (1) solo se entrambi gli operandi sono veri (1). In tutti gli altri casi, il valore dell'operazione è "falso" (0). 4. Aggiunta logica esclusiva (OR logico esclusivo) - un'operazione logica su due operandi, il cui risultato è "vero" (1), se solo uno dei due operandi è vero (1) e falso (0), se entrambi gli operandi sono false (0) o true (1). 4. Aggiunta logica esclusiva (OR logico esclusivo) - un'operazione logica su due operandi, il cui risultato è "vero" (1), se solo uno dei due operandi è vero (1) e falso (0), se entrambi gli operandi sono false (0) o true (1). Il seguente insieme di comandi che supportano l'utilizzo di dati logici: 1) e operando_1, operando_2 - operazione di moltiplicazione logica; 2) o operando_1, operando_2 - operazione di addizione logica; 3) xor operando_1, operando_2 - operazione di addizione logica esclusiva; 4) test operando_1, operando_2 - operazione "test" (per moltiplicazione logica) 5) non operando - operazione di negazione logica. a) per impostare determinate cifre (bit) a 1, viene utilizzato il comando o operando_1, operando_2; b) per reimpostare determinate cifre (bit) a 0, viene utilizzato il comando e operando_1, operando_2; c) viene applicato il comando xor operando_1, operando_2: ▪ scoprire quali bit in operando_1 e operando_2 sono diversi; ▪ per invertire lo stato dei bit specificati in operando_1. Il comando test operand_1, operand_2 (check operand_1) viene utilizzato per verificare lo stato dei bit specificati. Il risultato del comando è impostare il valore del flag zero zf: 1) se zf = 0, allora come risultato della moltiplicazione logica si ottiene un risultato zero, ovvero un bit unitario della maschera, che non corrispondeva al corrispondente bit unitario dell'operando1; 2) se zf = 1, allora la moltiplicazione logica ha dato come risultato un risultato diverso da zero, cioè almeno un bit unitario della maschera coincideva con il corrispondente bit dell'operando1. Tutte le istruzioni di spostamento spostano i bit nel campo dell'operando a sinistra o a destra a seconda del codice operativo. Tutte le istruzioni di turno hanno la stessa struttura: operando cop, contatore di turno. 56. Comandi di trasferimento del controllo Quale istruzione di programma deve essere eseguita successivamente, il microprocessore apprende dal contenuto del cs: (e) coppia di registri ip: 1) cs - registro del segmento di codice, che contiene l'indirizzo fisico del segmento di codice corrente; 2) eip/ip - registro puntatore istruzione, contiene il valore di offset in memoria della successiva istruzione da eseguire. Salti incondizionati Ciò che deve essere modificato dipende da: 1) sul tipo di operando nell'istruzione di ramo incondizionato (vicino o lontano); 2) di specificare un modificatore prima dell'indirizzo di transizione; in questo caso l'indirizzo di salto stesso può essere sia direttamente nell'istruzione (salto diretto) che in un registro di memoria (salto indiretto). Valori del modificatore: 1) vicino a ptr - passaggio diretto all'etichetta; 2) far ptr - passaggio diretto a un'etichetta in un altro segmento di codice; 3) parola ptr - transizione indiretta all'etichetta; 4) dword ptr - transizione indiretta a un'etichetta in un altro segmento di codice. jmp istruzione di salto incondizionato jmp [modificatore] jump_address Una procedura o subroutine è l'unità funzionale di base della scomposizione di un compito. Una procedura è un gruppo di comandi. Salti condizionali Il microprocessore ha 18 istruzioni di salto condizionale. Questi comandi consentono di controllare: 1) la relazione tra operandi con segno (“more is less”); 2) relazione tra operandi senza segno ("più alto più basso"); 3) stati dei flag aritmetici ZF, SF, CF, OF, PF (ma non AF). Le istruzioni di salto condizionale hanno la stessa sintassi: jcc jump label Il comando cmp compare ha un modo interessante di lavorare. È esattamente lo stesso del comando di sottrazione: sub operando_1, operando_2. Il comando cmp, come il comando sub, sottrae gli operandi e imposta i flag. L'unica cosa che non fa è scrivere il risultato della sottrazione al posto del primo operando. La sintassi del comando cmp - cmp operand_1, operand_2 (confronta) - confronta due operandi e imposta i flag in base ai risultati del confronto. Organizzazione dei cicli È possibile organizzare l'esecuzione ciclica di una determinata sezione del programma, ad esempio, utilizzando il trasferimento condizionato dei comandi di controllo o il comando di salto incondizionato jmp: 1) etichetta di transizione del ciclo (Loop) - ripetere il ciclo. Il comando permette di organizzare loop simili ai loop for in linguaggi di alto livello con decremento automatico del contatore di loop; 2) etichetta di salto loope/loopz I comandi loope e loopz sono sinonimi assoluti; 3) etichetta di salto loopne/loopnz Anche i comandi loopne e loopnz sono sinonimi assoluti. I comandi loope/loopz e loopne/loopnz sono reciproci nel loro funzionamento. Autore: Tsvetkova A.V.
▪ Le principali date ed eventi della storia nazionale ed estera. Culla ▪ Diritto civile. Seconda parte. Culla
Pelle artificiale per l'emulazione del tocco
15.04.2024 Lettiera per gatti Petgugu Global
15.04.2024 L'attrattiva degli uomini premurosi
14.04.2024
▪ Nuovo motore economico Audi 2.0 TFSI ▪ Hai bisogno di dormire non troppo ▪ Scanner tascabile per risonanza nucleare ▪ Rivoluzione verde negli oceani: aumento del fitoplancton ▪ Il vento solare crea una carica elettrica su Phobos
▪ sezione del sito Strumenti e meccanismi per l'agricoltura. Selezione dell'articolo ▪ articolo C'era un gioco! Espressione popolare ▪ articolo Cos'è la muffa? Risposta dettagliata ▪ Articolo Cespuglio di tè. Leggende, coltivazione, metodi di applicazione
Homepage | Biblioteca | Articoli | Mappa del sito | Recensioni del sito
www.diagram.com.ua |


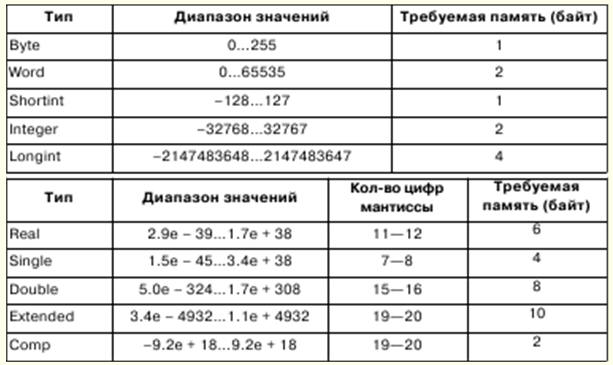

 Vedi altri articoli sezione
Vedi altri articoli sezione 