|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Appunti delle lezioni, cheat sheet
Banca dati. Appunti delle lezioni: in breve, il più importante
Elenco / Appunti delle lezioni, cheat sheet Sommario
Lezione n. 1. Introduzione 1. Sistemi di gestione delle banche dati Sistemi di gestione di database (DBMS) sono prodotti software specializzati che consentono: 1) archiviare permanentemente quantità arbitrariamente grandi (ma non infinite) di dati; 2) estrarre e modificare in un modo o nell'altro tali dati memorizzati, mediante le cosiddette query; 3) creare nuovi database, ovvero descrivere le strutture logiche dei dati e impostarne la struttura, ovvero fornire un'interfaccia di programmazione; 4) accedere ai dati memorizzati da più utenti contemporaneamente (ossia fornire l'accesso al meccanismo di gestione delle transazioni). Di conseguenza, la banca dati sono dataset sotto il controllo dei sistemi di gestione. Ora i sistemi di gestione dei database sono i prodotti software più complessi sul mercato e ne costituiscono la base. In futuro, si prevede di condurre sviluppi su una combinazione di sistemi di gestione di database convenzionali con programmazione orientata agli oggetti (OOP) e tecnologie Internet. Inizialmente, i DBMS erano basati su gerarchico и modelli di dati di rete, cioè consentito di lavorare solo con strutture ad albero e grafo. Nel processo di sviluppo nel 1970, c'erano sistemi di gestione di database proposti da Codd (Codd), basati su modello di dati relazionali. 2. Banche dati relazionali Il termine "relazionale" deriva dalla parola inglese "relation" - "relationship". In senso matematico più generale (come ricorderete dal classico corso di algebra degli insiemi) отношение - è un set R = {(x1,..., Xn) | X1 ∈A1,...,Xn ∈ An}, dove un1,..., UNn sono gli insiemi che formano il prodotto cartesiano. In questo modo, rapporto R è un sottoinsieme del prodotto cartesiano degli insiemi: A1 x...xAn : R ⊆ A 1 x...xAn. Ad esempio, considera le relazioni binarie dell'ordine rigoroso "maggiore di" e "minore di" sull'insieme di coppie ordinate di numeri A 1 = LA2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x LA2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 x LA2. Queste relazioni possono essere presentate sotto forma di tabelle. Rapporto "maggiore di">:
Rapporto "inferiore a" R<:
Pertanto, vediamo che nei database relazionali un'ampia varietà di dati è organizzata sotto forma di relazioni e può essere presentata sotto forma di tabelle. Si noti che queste due relazioni R> e R< non sono equivalenti tra loro, in altre parole le tabelle corrispondenti a queste relazioni non sono uguali tra loro. Pertanto, le forme di rappresentazione dei dati nei database relazionali possono essere diverse. Come si manifesta nel nostro caso questa possibilità di diversa rappresentazione? Relazioni R> e R< - questi sono insiemi e un insieme è una struttura non ordinata, il che significa che nelle tabelle corrispondenti a queste relazioni le righe possono essere scambiate. Ma allo stesso tempo, gli elementi di questi insiemi sono insiemi ordinati, nel nostro caso - coppie ordinate di numeri 3, 4, 5, il che significa che le colonne non possono essere scambiate. Pertanto, abbiamo dimostrato che la rappresentazione di una relazione (in senso matematico) come una tabella con un ordine arbitrario di righe e un numero fisso di colonne è una forma accettabile e corretta di rappresentazione delle relazioni. Ma se consideriamo le relazioni R> e R< dal punto di vista delle informazioni in essi contenute, è evidente che sono equivalenti. Pertanto, nei database relazionali, il concetto di "relazione" ha un significato leggermente diverso rispetto a una relazione in matematica generale. Vale a dire, non è correlato all'ordinamento per colonne in una forma tabellare di presentazione. Vengono invece introdotti i cosiddetti schemi di relazione "riga - intestazione di colonna", ovvero ad ogni colonna viene assegnata un'intestazione, dopo la quale possono essere scambiati liberamente. Ecco come apparirà la nostra relazione R> e R< in un database relazionale. Una stretta relazione di ordine (invece della relazione R>):
Una stretta relazione di ordine (invece della relazione R<):
Entrambe le relazioni-tabelle ne ottengono una nuova (in questo caso, la stessa, poiché introducendo intestazioni aggiuntive abbiamo cancellato le differenze tra le relazioni R> e R<) titolo. Quindi, vediamo che con l'aiuto di un trucco così semplice come aggiungere le intestazioni necessarie alle tabelle, arriviamo alla conclusione che le relazioni R> e R< diventano equivalenti tra loro. Pertanto, concludiamo che il concetto di "relazione" in senso matematico generale e relazionale non coincide completamente, non sono identici. Attualmente, i sistemi di gestione di database relazionali costituiscono la base del mercato delle tecnologie dell'informazione. Ulteriori ricerche sono in corso nella direzione di combinare vari gradi del modello relazionale. Lezione 2. Dati mancanti Nei sistemi di gestione del database per il rilevamento dei dati mancanti sono descritti due tipi di valori: vuoto (o valori-vuoto) e non definito (o valori-nulli). In alcune pubblicazioni (per lo più commerciali), i valori Null sono talvolta indicati come valori vuoti o nulli, ma questo non è corretto. Il significato dei significati vuoto e indefinito è fondamentalmente diverso, quindi è necessario monitorare attentamente il contesto dell'uso di un particolare termine. 1. Valori vuoti (valori vuoti) valore vuoto è solo uno dei tanti valori possibili per alcuni tipi di dati ben definiti. Elenchiamo le più "naturali", immediate valori vuoti (ovvero valori vuoti che potremmo allocare da soli senza avere alcuna informazione aggiuntiva): 1) 0 (zero) - il valore null è vuoto per i tipi di dati numerici; 2) false (sbagliato) - è un valore vuoto per un tipo di dati booleano; 3) B'' - stringa di bit vuota per stringhe di lunghezza variabile; 4) "" - stringa vuota per stringhe di caratteri di lunghezza variabile. Nei casi precedenti, è possibile determinare se un valore è nullo o meno confrontando il valore esistente con la costante nulla definita per ogni tipo di dati. Ma i sistemi di gestione dei database, a causa degli schemi in essi implementati per l'archiviazione dei dati a lungo termine, possono funzionare solo con stringhe di lunghezza costante. Per questo motivo, una stringa vuota di bit può essere chiamata stringa di zeri binari. Oppure una stringa composta da spazi o qualsiasi altro carattere di controllo è una stringa vuota di caratteri. Ecco alcuni esempi di stringhe vuote di lunghezza costante: 1) B'0'; 2) B'000'; 3) ' '. Come puoi sapere se una stringa è vuota in questi casi? Nei sistemi di gestione di database, viene utilizzata una funzione logica per verificare la vacuità, ovvero il predicato IsEmpty(<espressione>), che letteralmente significa "mangiare vuoto". Questo predicato è in genere integrato nel sistema di gestione del database e può essere applicato a qualsiasi tipo di espressione. Se non esiste tale predicato nei sistemi di gestione del database, è possibile scrivere una funzione logica da soli e includerla nell'elenco di oggetti del database in fase di progettazione. Considera un altro esempio in cui non è così facile determinare se abbiamo un valore vuoto. Dati del tipo di data. Quale valore in questo tipo deve essere considerato un valore vuoto se la data può variare nell'intervallo da 01.01.0100. prima del 31.12.9999/XNUMX/XNUMX? Per fare ciò, nel DBMS viene introdotta una designazione speciale per costanti di data vuote {...}, se viene scritto il valore di questo tipo: {DD. MM. YY} o {YY. MM. DD}. Con questo valore, si verifica un confronto durante il controllo del valore di vuoto. È considerato un valore "completo" ben definito di un'espressione di questo tipo e il più piccolo possibile. Quando si lavora con i database, i valori null vengono spesso utilizzati come valori predefiniti o vengono utilizzati quando mancano i valori dell'espressione. 2. Valori indefiniti (Valori nulli) Parola Nullo usato per denotare valori indefiniti nelle banche dati. Per capire meglio quali valori si intendono indefiniti, si consideri una tabella che sia un frammento di un database:
Così, valore indefinito o Valore nullo - è: 1) valore sconosciuto, ma usuale, cioè applicabile. Ad esempio, il signor Khairetdinov, che è il numero uno nel nostro database, ha indubbiamente alcuni dati del passaporto (come una persona nata nel 1980 e un cittadino del paese), ma non sono noti, quindi non sono inclusi nel database . Pertanto, il valore Null verrà scritto nella colonna corrispondente della tabella; 2) valore non applicabile. Il signor Karamazov (n. 2 nel nostro database) semplicemente non può avere alcun dato sul passaporto, perché al momento della creazione di questo database o dell'inserimento dei dati in esso, era un bambino; 3) il valore di qualsiasi cella della tabella, se non possiamo dire se è applicabile o meno. Ad esempio, il signor Kovalenko, che occupa la terza posizione nel nostro database, non conosce l'anno di nascita, quindi non possiamo dire con certezza se ha o meno i dati del passaporto. E di conseguenza, i valori di due celle nella riga dedicata al Sig. Kovalenko saranno Null-value (la prima - in quanto sconosciuta in genere, la seconda - come valore la cui natura è sconosciuta). Come qualsiasi altro tipo di dati, anche i valori Null hanno determinati proprietà. Ne elenchiamo i più significativi: 1) nel tempo, la comprensione del valore Null può cambiare. Ad esempio, per il signor Karamazov (n. 2 nel nostro database) nel 2014, ovvero, al raggiungimento della maggiore età, il valore Null cambierà in un valore specifico e ben definito; 2) Il valore Null può essere assegnato a una variabile oa una costante di qualsiasi tipo (numerica, stringa, booleana, data, ora, ecc.); 3) il risultato di qualsiasi operazione su espressioni con valori Null come operandi è un valore Null; 4) Fanno eccezione alla regola precedente le operazioni di congiunzione e disgiunzione nelle condizioni delle leggi di assorbimento (per maggiori dettagli sulle leggi di assorbimento si veda il paragrafo 4 della lezione n. 2). 3. Valori nulli e regola generale per la valutazione delle espressioni Parliamo di più delle azioni su espressioni contenenti valori Null. La regola generale per la gestione dei valori Null (che il risultato delle operazioni sui valori Null è un valore Null) si applica alle seguenti operazioni: 1) all'aritmetica; 2) alle operazioni di negazione, congiunzione e disgiunzione bit per bit (salvo leggi di assorbimento); 3) alle operazioni con stringhe (ad esempio concatenazione - concatenazione di stringhe); 4) alle operazioni di confronto (<, ≤, ≠, ≥, >). Diamo esempi. Come risultato dell'applicazione delle seguenti operazioni, si otterranno valori Null: 3 + Null, 1/ Null, (Ivanov' + '' + Null) ≔ Null Qui, invece della solita uguaglianza, usiamo operazione di sostituzione "≔" a causa della natura speciale dell'utilizzo dei valori Null. Di seguito, questo carattere verrà utilizzato anche in situazioni simili, il che significa che l'espressione a destra del carattere jolly può sostituire qualsiasi espressione dall'elenco a sinistra del carattere jolly. La natura dei valori Null spesso fa sì che alcune espressioni producano un valore Null invece del null previsto, ad esempio: (x - x), y * (x - x), x * 0 ≔ Null quando x = Null. Il fatto è che sostituendo, ad esempio, il valore x = Null nell'espressione (x - x), otteniamo l'espressione (Null - Null) e la regola generale per calcolare il valore dell'espressione contenente valori Null entra in vigore e le informazioni sul fatto che qui il valore Null corrisponde alla stessa variabile vengono perse. Possiamo concludere che quando si calcolano operazioni diverse da quelle logiche, i valori Null vengono interpretati come inapplicabile, e quindi anche il risultato è un valore Null. L'uso dei valori Null nelle operazioni di confronto porta a risultati non meno inaspettati. Ad esempio, le seguenti espressioni producono anche valori Null invece dei valori booleani previsti True o False: (Null < Null); (Nullo ≤ nullo); (Null = Null); (Null ≠ Null); (Null > Null); (Null ≥ Null) ≔ Null; Pertanto, concludiamo che è impossibile dire che un valore Null sia uguale o non uguale a se stesso. Ogni nuova occorrenza di un valore Null viene trattata come indipendente e ogni volta i valori Null vengono trattati come diversi valori sconosciuti. In questo, i valori Null sono fondamentalmente diversi da tutti gli altri tipi di dati, perché sappiamo che era sicuro dire di tutti i valori passati in precedenza e dei loro tipi che sono uguali o non uguali tra loro. Quindi vediamo che i valori Null non sono i valori delle variabili nel solito senso della parola. Pertanto, diventa impossibile confrontare i valori di variabili o espressioni contenenti valori Null, poiché di conseguenza non riceveremo i valori booleani True o False, ma valori Null, come nei seguenti esempi: (x < Null); (X ≤ nullo); (x=Nulla); (x ≠ Nullo); (x > nullo); (x ≥ Nullo) ≔ Nullo; Pertanto, per analogia con valori vuoti, per controllare un'espressione per valori Null, è necessario utilizzare un predicato speciale: IsNull(<espressione>), che letteralmente significa "è Nullo". La funzione booleana restituisce True se l'espressione contiene Null o è Null e False in caso contrario, ma non restituisce mai Null. Il predicato IsNull può essere applicato a variabili ed espressioni di qualsiasi tipo. Quando applicato a espressioni di tipo vuoto, il predicato restituirà sempre False. Per esempio:
Quindi, in effetti, vediamo che nel primo caso, quando il predicato IsNull è stato preso da zero, l'output è risultato essere False. In tutti i casi, compreso il secondo e il terzo, quando gli argomenti della funzione logica risultavano uguali al valore Null, e nel quarto caso, quando l'argomento stesso era inizialmente uguale al valore Null, il predicato restituiva True. 4. Valori nulli e operazioni logiche Tipicamente, solo tre operazioni logiche sono supportate direttamente nei sistemi di gestione del database: negazione ¬, congiunzione & e disgiunzione ∨. Le operazioni di successione ⇒ e di equivalenza ⇔ sono espresse in termini di esse mediante sostituzioni: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Si noti che queste sostituzioni vengono completamente conservate quando si utilizzano valori Null. È interessante notare che, utilizzando l'operatore di negazione "¬" qualsiasi operazione congiunzione e o disgiunzione ∨ può essere espressa l'una attraverso l'altra come segue: (x e y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); Queste sostituzioni, così come le precedenti, non sono influenzate dai valori Null. E ora daremo le tavole di verità delle operazioni logiche di negazione, congiunzione e disgiunzione, ma oltre ai soliti valori Vero e Falso, utilizziamo anche il valore Nullo come operandi. Per comodità, introduciamo la seguente notazione: invece di True, scriveremo t, invece di False - f, e invece di Null - n. 1. negazione xx.
Vale la pena notare i seguenti punti interessanti relativi all'operazione di negazione utilizzando valori Null: 1) ¬¬x ≔ x - la legge della doppia negazione; 2) ¬Null ≔ Null - Il valore Null è un punto fisso. 2. Congiunzione x & y.
Anche questa operazione ha le sue proprietà: 1) x & y ≔ y & x - commutatività; 2) x & x ≔ x - idempotenza; 3) False & y ≔ False, qui False è un elemento assorbente; 4) Vero & y ≔ y, qui Vero è l'elemento neutro. 3. Disgiunzione x ∨ y.
caratteristiche: 1) x ∨ y ≔ y ∨ x - commutatività; 2) x ∨ x ≔ x - idempotenza; 3) False ∨ y ≔ y, qui False è l'elemento neutro; 4) Vero ∨ y ≔ Vero, qui Vero è un elemento assorbente. Un'eccezione alla regola generale sono le regole per il calcolo delle operazioni logiche congiunzione & e disgiunzione ∨ nelle condizioni di azione leggi di assorbimento: (Falso & y) ≔ (x & Falso) ≔ Falso; (Vero ∨ y) ≔ (x ∨ Vero) ≔ Vero; Queste regole aggiuntive sono formulate in modo che quando si sostituisce un valore Null con False o True, il risultato non dipenda comunque da questo valore. Come mostrato in precedenza per altri tipi di operazioni, l'utilizzo di valori Null nelle operazioni booleane può anche comportare valori imprevisti. Ad esempio, la logica a prima vista è violata la legge dell'esclusione dei terzi (x ∨ ¬x) e la legge della riflessività (x = x), poiché per x ≔ Null si ha: (x ∨ ¬x), (x = x) ≔ Nullo. Le leggi non vengono applicate! Questo è spiegato nello stesso modo di prima: quando un valore Null viene sostituito in un'espressione, l'informazione che questo valore è riportato dalla stessa variabile viene persa e la regola generale per lavorare con i valori Null entra in vigore. Pertanto, concludiamo: quando si eseguono operazioni logiche con valori Null come operando, questi valori sono determinati dai sistemi di gestione del database come applicabile ma sconosciuto. 5. Valori nulli e controllo delle condizioni Quindi, da quanto precede, possiamo concludere che nella logica dei sistemi di gestione dei database non ci sono due valori logici (Vero e Falso), ma tre, perché il valore Null è anche considerato come uno dei possibili valori logici. Questo è il motivo per cui viene spesso indicato come il valore sconosciuto, il valore sconosciuto. Tuttavia, nonostante ciò, nei sistemi di gestione dei database viene implementata solo la logica a due valori. Pertanto, una condizione con un valore Null (una condizione non definita) deve essere interpretata dalla macchina come True o False. Per impostazione predefinita, il linguaggio DBMS riconosce una condizione con un valore Null come False. Lo illustriamo con i seguenti esempi di implementazione delle istruzioni condizionali If e While nei sistemi di gestione dei database: Se P allora A, altrimenti B; Questa voce significa: se P restituisce True, viene eseguita l'azione A e se P restituisce False o Null, viene eseguita l'azione B. Ora applichiamo l'operazione di negazione a questo operatore, otteniamo: Se ¬P allora B altrimenti A; A sua volta, questo operatore significa quanto segue: se ¬P restituisce True, viene eseguita l'azione B e se ¬P restituisce False o Null, verrà eseguita l'azione A. E ancora, come possiamo vedere, quando appare un valore Null, incontriamo risultati inaspettati. Il punto è che le due istruzioni If in questo esempio non sono equivalenti! Sebbene uno di essi sia ottenuto dall'altro negando la condizione e riordinando i rami, cioè con l'operazione standard. Tali operatori sono generalmente equivalenti! Ma nel nostro esempio, vediamo che il valore Null della condizione P nel primo caso corrisponde al comando B, e nel secondo - A. Consideriamo ora l'azione dell'istruzione condizionale while: Mentre P fa A; B; Come funziona questo operatore? Finché P è Vero, l'azione A verrà eseguita e non appena P è Falso o Null, verrà eseguita l'azione B. Ma i valori Nulli non sono sempre interpretati come Falsi. Ad esempio, nei vincoli di integrità, le condizioni non definite vengono riconosciute come True (i vincoli di integrità sono condizioni che vengono imposte ai dati di input e ne garantiscono la correttezza). Questo perché in tali vincoli dovrebbero essere rifiutati solo dati deliberatamente falsi. E ancora, nei sistemi di gestione dei database, c'è uno speciale funzione di sostituzione IfNull(vincoli di integrità, True), con cui è possibile rappresentare in modo esplicito valori Null e condizioni non definite. Riscriviamo le istruzioni condizionali If e While usando questa funzione: 1) Se IfNull ( P, False) allora A altrimenti B; 2) Mentre IfNull(P, False) fa A; B; Quindi, la funzione di sostituzione IfNull(espressione 1, espressione 2) restituisce il valore della prima espressione se non contiene un valore Null e il valore della seconda espressione in caso contrario. Va notato che non vengono imposte restrizioni al tipo di espressione restituita dalla funzione IfNull. Pertanto, utilizzando questa funzione, è possibile ignorare in modo esplicito qualsiasi regola per l'utilizzo dei valori Null. Lezione 3. Oggetti di dati relazionali 1. Requisiti per la forma tabellare di rappresentazione delle relazioni 1. Il primissimo requisito per la forma tabellare della rappresentazione delle relazioni è la finitezza. Lavorare con tabelle infinite, relazioni o qualsiasi altra rappresentazione e organizzazione dei dati è scomodo, lo sforzo impiegato è raramente giustificato e, inoltre, questa direzione ha poca applicazione pratica. Ma oltre a questo, abbastanza scontato, ci sono altri requisiti. 2. L'intestazione della tabella che rappresenta la relazione deve necessariamente consistere in una riga, l'intestazione delle colonne, e con nomi univoci. Non sono consentite intestazioni multilivello. Ad esempio, questi:
Tutte le intestazioni multilivello vengono sostituite da intestazioni a livello singolo selezionando le intestazioni appropriate. Nel nostro esempio, la tabella dopo le trasformazioni specificate sarà simile a questa:
Vediamo che il nome di ogni colonna è univoco, quindi possono essere scambiati a piacere, ovvero il loro ordine diventa irrilevante. E questo è molto importante perché è la terza proprietà. 3. L'ordine delle righe dovrebbe essere irrilevante. Tuttavia, anche questo requisito non è strettamente restrittivo, poiché qualsiasi tabella può essere facilmente ridotta alla forma richiesta. Ad esempio, puoi inserire una colonna aggiuntiva che determinerà l'ordine delle righe. In questo caso, nulla cambierà dalla permutazione delle linee. Ecco un esempio di tale tabella:
4. Non ci dovrebbero essere righe duplicate nella tabella che rappresentano la relazione. Se ci sono righe duplicate nella tabella, questo può essere facilmente risolto introducendo una colonna aggiuntiva responsabile del numero di duplicati di ciascuna riga, ad esempio:
Anche la seguente proprietà è abbastanza attesa, perché è alla base di tutti i principi di programmazione e progettazione di database relazionali. 5. I dati in tutte le colonne devono essere dello stesso tipo. E inoltre, devono essere di tipo semplice. Spieghiamo cosa sono i tipi di dati semplici e complessi. Un tipo di dati semplice è uno i cui valori di dati non sono compositi, ovvero non contengono parti costituenti. Pertanto, nelle colonne della tabella non devono essere presenti né elenchi, né array, né alberi, né oggetti compositi simili. Tali oggetti sono tipo di dati compositi - nei sistemi di gestione di database relazionali, essi stessi sono presentati sotto forma di tabelle-relazioni indipendenti. 2. Domini e attributi Domini e attributi sono concetti di base nella teoria della creazione e della gestione dei database. Spieghiamo di cosa si tratta. Formalmente, dominio di attributo (indicato Dom(a)), dove a è un attributo, è definito come l'insieme di valori validi dello stesso tipo dell'attributo corrispondente a. Questo tipo deve essere semplice, ovvero: dom(a) ⊆ {x | tipo(x) = tipo(a)}; Attributo (indicato con a) è a sua volta definito come una coppia ordinata composta dall'attributo name name(a) e dall'attributo domain dom(a), ovvero: a = (nome(a): dom(a)); Questa definizione usa ":" invece del solito "," (come nelle definizioni di coppia ordinate standard). Questo viene fatto per enfatizzare l'associazione del dominio dell'attributo e del tipo di dati dell'attributo. Ecco alcuni esempi di attributi diversi: а1 = (Corso: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | tipo(x) = reale, x 0}); а3 = (LunghezzaSm: {x | tipo(x) = reale, x 0}); Si noti che gli attributi a2 e a3 i domini corrispondono formalmente. Ma il significato semantico di questi attributi è diverso, perché confrontare i valori di massa e lunghezza non ha senso. Pertanto, un dominio di attributo è associato non solo al tipo di valori validi, ma anche a un significato semantico. Nella forma tabellare di una relazione, l'attributo viene visualizzato come intestazione di colonna nella tabella e il dominio dell'attributo non è specificato, ma è implicito. Si presenta così:
È facile vedere che qui ciascuno dei titoli a1, un2, un3 colonne di una tabella che rappresentano una relazione è un attributo separato. 3. Schemi di relazioni. Tuple con valore denominato Nella teoria e nella pratica del DBMS, i concetti di uno schema di relazione e di un valore denominato di una tupla su un attributo sono fondamentali. Portiamoli. Schema di relazione (indicato S) è definito come un insieme finito di attributi con nomi univoci, ovvero: S = {a | un ∈ S}; In ogni tabella che rappresenta una relazione, tutte le intestazioni di colonna (tutti gli attributi) vengono combinate nello schema della relazione. Determina il numero di attributi in uno schema di relazione grado di esso relazioni ed è indicato come cardinalità dell'insieme: |S|. Uno schema di relazioni può essere associato a un nome di schema di relazioni. In una forma tabellare di rappresentazione delle relazioni, come puoi facilmente vedere, lo schema delle relazioni non è altro che una riga di intestazioni di colonna.
S = {a1, un2, un3, un4} - schema di relazione di questa tabella. Il nome della relazione viene visualizzato come intestazione schematica della tabella. In formato testo, lo schema di relazione può essere rappresentato come un elenco denominato di nomi di attributi, ad esempio: Studenti (numero del libro di classe, cognome, nome, patronimico, data di nascita). Qui, come nella forma tabellare, i domini degli attributi non sono specificati ma impliciti. Dalla definizione consegue che lo schema di una relazione può anche essere vuoto (S = ∅). È vero, questo è possibile solo in teoria, poiché in pratica il sistema di gestione del database non consentirà mai la creazione di uno schema di relazioni vuoto. Valore tupla denominato sull'attributo (indicato t(a)) è definito per analogia con un attributo come una coppia ordinata costituita da un nome di attributo e da un valore di attributo, ovvero: t(a) = (nome(a) : x), x ∈ dom(a); Vediamo che il valore dell'attributo è preso dal dominio dell'attributo. Nella forma tabulare di una relazione, ogni valore denominato di una tupla su un attributo è una cella di tabella corrispondente:
Qui t(a1), t(a2), t(a3) - valori denominati della tupla t sugli attributi a1E2E3. Gli esempi più semplici di valori di tupla con nome sugli attributi: (Corso: 5), (Punteggio: 5); Qui Course e Score sono rispettivamente i nomi di due attributi e 5 è uno dei loro valori presi dai loro domini. Naturalmente, sebbene questi valori siano uguali in entrambi i casi, sono semanticamente diversi, poiché gli insiemi di questi valori in entrambi i casi differiscono l'uno dall'altro. 4. Tuple. Tipi di tupla Il concetto di tupla nei sistemi di gestione di database può essere intuitivamente trovato già dal punto precedente, quando abbiamo parlato del valore denominato di una tupla su vari attributi. Così, tupla (indicato t, dall'inglese. tupla - "tupla") con schema di relazione S è definito come l'insieme dei valori denominati di questa tupla su tutti gli attributi inclusi in questo schema di relazione S. In altre parole, gli attributi sono presi da ambito di una tupla, def(t), cioè.: t ≡ t(S) = {t(a) | a ∈ def(t) ⊆ S;. È importante che non più di un valore di attributo corrisponda a un nome di attributo. Nella forma tabellare della relazione, una tupla sarà una qualsiasi riga della tabella, ovvero:
qui t1(S) = {t(a1), t(a2), t(a3), t(a4)} e T2(S) = {t(a5), t(a6), t(a7), t(a8)} - tuple. Le tuple nel DBMS differiscono in tipi a seconda del suo dominio di definizione. Le tuple sono chiamate: 1) parziale, se il loro dominio di definizione è incluso o coincide con lo schema della relazione, ovvero def(t) ⊆ S. Questo è un caso comune nella pratica dei database; 2) completare, nel caso in cui il loro dominio di definizione coincida completamente, è uguale allo schema della relazione, ovvero def(t) = S; 3) incompleto, se il dominio di definizione è completamente compreso nello schema delle relazioni, ovvero def(t) ⊂ S; 4) da nessuna parte definito, se il loro dominio di definizione è uguale all'insieme vuoto, cioè def(t) = ∅. Spieghiamo con un esempio. Supponiamo di avere una relazione data dalla tabella seguente.
Lascia qui t1 = {10, 20, 30}, t2 = {10, 20, Nullo}, t3 = {Null, Null, Null}. Allora è facile vedere che la tupla t1 - completo, poiché il suo dominio di definizione è def(t1) = {a, b, c} = S. tupla t2 - incompleto, def(t2) = { a, b} ⊂ S. Infine, la tupla t3 - non definito da nessuna parte, poiché la sua def(t3) = ∅. Va notato che una tupla non definita da nessuna parte è un insieme vuoto, tuttavia associato a uno schema di relazione. A volte viene indicata una tupla non definita da nessuna parte: ∅(S). Come abbiamo già visto nell'esempio precedente, una tale tupla è una riga di tabella composta solo da valori Null. Curiosamente, la comparabile, cioè possibilmente uguali, sono solo tuple con lo stesso schema di relazioni. Pertanto, ad esempio, due tuple non definite da nessuna parte con schemi di relazione diversi non saranno uguali, come ci si potrebbe aspettare. Saranno diversi proprio come i loro modelli di relazione. 5. Relazioni. Tipi di relazione E infine, definiamo la relazione come una sorta di cima della piramide, costituita da tutti i concetti precedenti. Così, отношение (indicato r, dall'inglese. relazione) con schema di relazione S è definito come un insieme necessariamente finito di tuple aventi lo stesso schema di relazione S. Quindi: r ≡ r(S) = {t(S) | t∈r}; Per analogia con gli schemi di relazione, viene chiamato il numero di tuple in una relazione potere di relazione e indicato come cardinalità dell'insieme: |r|. Le relazioni, come le tuple, differiscono nei tipi. Quindi la relazione si chiama: 1) parziale, se è soddisfatta la seguente condizione per una qualsiasi tupla inclusa nella relazione: [def(t) ⊆ S]. Questo è (come con le tuple) il caso generale; 2) completare, nel caso se ∀t ∈ r(S) abbiamo [def(t) = S]; 3) incompleto, se ∃t ∈ r(S) def(t) ⊂ S; 4) da nessuna parte definito, se ∀t ∈ r(S) [def(t) = ∅]. Prestiamo particolare attenzione alle relazioni non definite da nessuna parte. A differenza delle tuple, lavorare con tali relazioni implica un po' di sottigliezza. Il punto è che le relazioni non definite da nessuna parte possono essere di due tipi: possono essere vuote o possono contenere una singola tupla non definita da nessuna parte (tali relazioni sono denotate da {∅(S)}). comparabile (per analogia con le tuple), cioè, possibilmente uguali, sono solo relazioni con lo stesso schema di relazioni. Pertanto, le relazioni con diversi schemi di relazione sono diverse. In forma tabellare, una relazione è il corpo della tabella, a cui corrisponde la riga - l'intestazione delle colonne, cioè letteralmente - l'intera tabella, insieme alla prima riga contenente le intestazioni. Lezione n. 4. Algebra relazionale. Operazioni unarie Algebra relazionale, come puoi immaginare, è un tipo speciale di algebra in cui tutte le operazioni vengono eseguite su modelli di dati relazionali, cioè sulle relazioni. In termini tabulari, una relazione include righe, colonne e una riga, l'intestazione delle colonne. Pertanto, le operazioni unarie naturali sono operazioni di selezione di determinate righe o colonne, nonché di modifica delle intestazioni di colonna e di ridenominazione degli attributi. 1. Operazione di selezione unaria La prima operazione unaria che esamineremo è operazione di recupero - l'operazione di selezionare righe da una tabella che rappresenta una relazione, secondo un principio, ovvero selezionare tuple di righe che soddisfano una determinata condizione o condizioni. Operatore di recupero indicato con σ , condizione di campionamento - P , cioè l'operatore σ è sempre assunto con una certa condizione sulle tuple P, e la condizione P stessa è scritta in funzione dello schema della relazione S. Tenuto conto di tutto ciò, il operazione di recupero sullo schema della relazione S in relazione alla relazione r apparirà così: σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, False}; Il risultato di questa operazione sarà una nuova relazione con lo stesso schema di relazioni S, costituita da quelle tuple t(S) della relazione-operando originale che soddisfano la condizione di selezione P t. È chiaro che per applicare un qualche tipo di condizione a una tupla, è necessario sostituire i valori degli attributi della tupla al posto dei nomi degli attributi. Per capire meglio come funziona questa operazione, diamo un'occhiata a un esempio. Sia dato il seguente schema di relazioni: S: Sessione (Gradebook No., Cognome, Materia, Voto). Prendiamo la condizione di selezione come segue: P = (Soggetto = 'Informatica' e Valutazione > 3). Dobbiamo estrarre dalla relazione-operando iniziale quelle tuple che contengono informazioni sugli studenti che hanno superato la materia "Informatica" di almeno tre punti. Sia data anche la seguente tupla da questa relazione: t0(S) ∈ r(S): {(numero di registro: 100), (Cognome: 'Ivanov'), (Oggetto: 'Banche dati'), (Punteggio: 5)}; Applicando la nostra condizione di selezione alla tupla t0, noi abbiamo: Pt0 = ('Banca dati' = 'Informatica' e 5 > 3); Su questa particolare tupla, la condizione di selezione non è soddisfatta. In generale, il risultato di questo particolare campione σ<Materia = 'Informatica' e Grado > 3 > Sessione ci sarà una tabella "Session", in cui rimangono righe che soddisfano la condizione di selezione. 2. Operazione di proiezione unaria Un'altra operazione unaria standard che studieremo è l'operazione di proiezione. Operazione di proiezione è l'operazione di selezione delle colonne da una tabella che rappresenta una relazione, secondo alcuni attributi. Vale a dire, la macchina sceglie quegli attributi (cioè, letteralmente quelle colonne) della relazione dell'operando originale che sono stati specificati nella proiezione. operatore di proiezione indicato con [S'] o π . Qui S' è un sottoschema dello schema originale della relazione S, cioè alcune delle sue colonne. Cosa significa questo? Ciò significa che S' ha meno attributi di S, perché in S' sono rimasti solo quegli attributi per i quali è stata soddisfatta la condizione di proiezione. E nella tabella che rappresenta la relazione r(S' ), ci sono tante righe quante sono nella tabella r(S), e ci sono meno colonne, poiché rimangono solo quelle corrispondenti agli attributi rimanenti. Pertanto, l'operatore di proiezione π< S'> applicato alla relazione r(S) risulta in una nuova relazione con un diverso schema di relazione r(S' ), costituito da proiezioni t(S) [S' ] di tuple dell'originale relazione. Come vengono definite queste proiezioni di tupla? proiezione di qualsiasi tupla t(S) della relazione originaria r(S) al sottocircuito S' è determinata dalla seguente formula: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. È importante notare che le tuple duplicate sono escluse dal risultato, ovvero non ci saranno righe duplicate nella tabella che rappresentano quella nuova. Tenendo presente tutto quanto sopra, un'operazione di proiezione in termini di sistemi di gestione di database sarebbe simile a questa: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t ∈ r}; Diamo un'occhiata a un esempio che illustra come funziona l'operazione di recupero. Sia data la relazione "Sessione" e lo schema di questa relazione: S: Sessione (numero d'aula, Cognome, Materia, Voto); Saremo interessati solo a due attributi di questo schema, vale a dire "Gradebook #" e "Cognome" dello studente, quindi il sottoschema S' sarà simile a questo: S': (Numero anagrafica, Cognome). Dobbiamo proiettare la relazione iniziale r(S) sul sottocircuito S'. Quindi, diamo una tupla t0(S) dalla relazione originaria: t0(S) ∈ r(S): {(numero di registro: 100), (Cognome: 'Ivanov'), (Oggetto: 'Banche dati'), (Punteggio: 5)}; Quindi, la proiezione di questa tupla sul dato sottocircuito S' sarà simile a questa: t0(S) S': {(Numero registro: 100), (Cognome: 'Ivanov')}; Se parliamo dell'operazione di proiezione in termini di tabelle, allora la Sessione di proiezione [numero registro, Cognome] della relazione originaria è la tabella Sessione, dalla quale vengono cancellate tutte le colonne, tranne due: numero registro e Cognome. Inoltre, tutte le righe duplicate sono state rimosse. 3. Operazione di ridenominazione unary E l'ultima operazione unaria che esamineremo è operazione di ridenominazione degli attributi. Se parliamo della relazione come di una tabella, allora l'operazione di ridenominazione è necessaria per modificare i nomi di tutte o alcune delle colonne. rinomina operatore si presenta così: ρ<φ>, qui φ - rinominare la funzione. Questa funzione stabilisce una corrispondenza biunivoca tra i nomi degli attributi dello schema S e Ŝ, dove rispettivamente S è lo schema della relazione originale e Ŝ è lo schema della relazione con attributi rinominati. Pertanto, l'operatore ρ<φ> applicato alla relazione r(S) fornisce una nuova relazione con lo schema Ŝ, costituito da tuple della relazione originale con solo attributi rinominati. Scriviamo l'operazione di ridenominazione degli attributi in termini di sistemi di gestione dei database: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; Ecco un esempio di utilizzo di questa operazione: Consideriamo la relazione Session a noi già familiare, con lo schema: S: Sessione (numero d'aula, Cognome, Materia, Voto); Introduciamo un nuovo schema di relazione Ŝ, con nomi di attributi diversi che vorremmo vedere al posto di quelli esistenti: Ŝ : (n. ZK, Cognome, Oggetto, Punteggio); Ad esempio, un cliente del database desiderava vedere altri nomi nella tua relazione pronta all'uso. Per implementare questo ordine, è necessario progettare la seguente funzione di ridenominazione: φ : (n° libretto, Cognome, Materia, Voto) → (N. ZK, Cognome, Materia, Punteggio); In effetti, solo due attributi devono essere rinominati, quindi è legale scrivere la seguente funzione di ridenominazione invece di quella corrente: φ : (numero del libretto, voto) → (n. ZK, punteggio); Inoltre, sia data anche la già familiare tupla appartenente alla relazione Session: t0(S) ∈ r(S): {(numero di registro: 100), (Cognome: 'Ivanov'), (Oggetto: 'Banche dati'), (Punteggio: 5)}; Applicare l'operatore di ridenominazione a questa tupla: ρ<φ>t0(S): {(ZK#: 100), (Cognome: 'Ivanov'), (Oggetto: 'Banche dati'), (Punteggio: 5)}; Quindi, questa è una delle tuple della nostra relazione, i cui attributi sono stati rinominati. In termini tabellari, il rapporto ρ < Numero Registro dei voti, Grado → "No. ZK, Punteggio > Sessione - questa è una nuova tabella ottenuta dalla tabella delle relazioni "Session" rinominando gli attributi specificati. 4. Proprietà delle operazioni unarie Le operazioni unarie, come tutte le altre, hanno determinate proprietà. Consideriamo il più importante di loro. La prima proprietà delle operazioni unarie di selezione, proiezione e ridenominazione è la proprietà che caratterizza il rapporto delle cardinalità delle relazioni. (Ricordiamo che la cardinalità è il numero di tuple nell'una o nell'altra relazione.) È chiaro che qui stiamo considerando, rispettivamente, la relazione iniziale e la relazione ottenuta come risultato dell'applicazione dell'una o dell'altra operazione. Si noti che tutte le proprietà delle operazioni unarie derivano direttamente dalle loro definizioni, quindi possono essere facilmente spiegate e anche, se lo si desidera, dedotte in modo indipendente. Quindi: 1) rapporto di potenza: a) per l'operazione di selezione: | σ r |≤ |r|; b) per l'operazione di proiezione: | r[S'] | ≤ |r|; c) per l'operazione di ridenominazione: | ρ<φ>r | = |r|; In totale, vediamo che per due operatori, cioè per l'operatore di selezione e l'operatore di proiezione, la potenza delle relazioni originali - operandi è maggiore della potenza delle relazioni ottenute da quelle originali applicando le operazioni corrispondenti. Questo perché la selezione che accompagna queste due operazioni di selezione e progetto esclude alcune righe o colonne che non soddisfano le condizioni di selezione. Nel caso in cui tutte le righe o le colonne soddisfino le condizioni, non vi è alcuna diminuzione della potenza (cioè il numero di tuple), quindi la disuguaglianza nelle formule non è rigorosa. Nel caso dell'operazione di ridenominazione, la potenza della relazione non cambia, in quanto cambiando i nomi non sono escluse tuple dalla relazione; 2) proprietà idempotente: a) per l'operazione di campionamento: σ σ r = σ ; b) per l'operazione di proiezione: r [S'] [S'] = r [S']; c) per l'operazione di ridenominazione, nel caso generale, la proprietà di idempotenza non è applicabile. Questa proprietà significa che applicare lo stesso operatore due volte in successione a qualsiasi relazione equivale ad applicarlo una volta. Per l'operazione di ridenominazione degli attributi di relazione, in generale, questa proprietà può essere applicata, ma con riserve e condizioni speciali. La proprietà dell'idempotenza è molto spesso usata per semplificare la forma di un'espressione e portarla a una forma più economica e reale. E l'ultima proprietà che considereremo è la proprietà della monotonia. È interessante notare che in qualsiasi condizione tutti e tre gli operatori sono monotoni; 3) proprietà di monotonia: a) per un'operazione di recupero: r1 ⊆ r2 ⇒σ r1 ⇒ σ r2; b) per l'operazione di proiezione: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) per l'operazione di ridenominazione: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; Il concetto di monotonia nell'algebra relazionale è simile allo stesso concetto dell'algebra generale ordinaria. Chiariamo: se inizialmente le relazioni r1 e r2 erano collegati tra loro in modo tale che r ⊆ r2, anche dopo aver applicato uno qualsiasi dei tre operatori di selezione, proiezione o ridenominazione, questa relazione verrà preservata. Lezione n. 5. Algebra relazionale. Operazioni binarie 1. Operazioni di unione, intersezione, differenza Qualsiasi operazione ha le proprie regole di applicabilità che devono essere osservate in modo che le espressioni e le azioni non perdano il loro significato. Le operazioni binarie della teoria degli insiemi di unione, intersezione e differenza possono essere applicate solo a due relazioni necessariamente con lo stesso schema di relazioni. Il risultato di tali operazioni binarie saranno relazioni costituite da tuple che soddisfano le condizioni delle operazioni, ma con lo stesso schema di relazioni degli operandi. 1. Il risultato operazioni sindacali due relazioni r1(S) e r2(S) ci sarà una nuova relazione r3(S) costituito da quelle tuple di relazioni r1(S) e r2(S) che appartengono ad almeno una delle relazioni originarie e con lo stesso schema di relazioni. Quindi l'intersezione delle due relazioni è: r3(S) = R1(S) r2(S) = {t(S) | t∈r1 ∪t ∈r2}; Per chiarezza, ecco un esempio in termini di tabelle: Siano date due relazioni: r1(S):
r2(S):
Vediamo che gli schemi della prima e della seconda relazione sono gli stessi, solo che hanno un diverso numero di tuple. L'unione di queste due relazioni sarà la relazione r3(S), che corrisponderà alla seguente tabella: r3(S) = r1(S) r2(S):
Quindi, lo schema della relazione S non è cambiato, è solo aumentato il numero di tuple. 2. Passiamo alla considerazione della prossima operazione binaria - operazioni di intersezione due relazioni. Come sappiamo dalla geometria della scuola, la relazione risultante includerà solo quelle tuple delle relazioni originali che sono presenti simultaneamente in entrambe le relazioni r1(S) e r2(S) (di nuovo, nota lo stesso schema di relazione). L'operazione dell'intersezione di due relazioni sarà simile a questa: r4(S) = R1(S)∩r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; E ancora, considera l'effetto di questa operazione sulle relazioni presentate sotto forma di tabelle: r1(S):
r2(S):
Secondo la definizione dell'operazione per intersezione di relazioni r1(S) e r2(S) ci sarà una nuova relazione r4(S), la cui vista tabella sarebbe simile a questa: r4(S) = R1(S)∩r2(S):
Infatti, se osserviamo le tuple della prima e della seconda relazione iniziale, ce n'è solo una in comune tra loro: {b, 2}. Divenne l'unica tupla della nuova relazione r4(S). 3. Operazione differenziale due relazioni è definita in modo simile alle operazioni precedenti. Le relazioni operandi, come nelle operazioni precedenti, devono avere gli stessi schemi di relazione, quindi la relazione risultante includerà tutte quelle tuple della prima relazione che non sono nella seconda, ovvero: r5(S) = R1(S)\r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; Le già note relazioni r1(S) e r2(S), in una vista tabellare simile a questa: r1(S):
r2(S):
Considereremo entrambi gli operandi nell'operazione di intersezione di due relazioni. Quindi, seguendo questa definizione, la relazione risultante r5(S) sarà simile a questa: r5(S) = R1(S)\r2(S):
Le operazioni binarie considerate sono di base, altre operazioni, più complesse, si basano su di esse. 2. Prodotto cartesiano e operazioni di unione naturale L'operazione di prodotto cartesiano e l'operazione di unione naturale sono operazioni binarie del tipo di prodotto e si basano sull'unione di due operazioni di relazioni che abbiamo discusso in precedenza. Sebbene l'azione dell'operazione sul prodotto cartesiano possa sembrare familiare a molti, inizieremo comunque con l'operazione sul prodotto naturale, poiché è un caso più generale della prima operazione. Quindi, considera l'operazione di unione naturale. Va subito notato che gli operandi di questa azione possono essere relazioni con schemi diversi, in contrasto con le tre operazioni binarie di unione, intersezione e ridenominazione. Se consideriamo due relazioni con schemi di relazioni differenti r1(S1) e r2(S2), poi il loro composto naturale ci sarà una nuova relazione r3(S3), che consisterà solo di quelle tuple di operandi che corrispondono all'intersezione degli schemi di relazione. Di conseguenza, lo schema della nuova relazione sarà più ampio di qualsiasi schema di relazioni di quelli originali, poiché è la loro connessione, "incollaggio". A proposito, si chiamano tuple identiche in due relazioni di operandi, secondo le quali si verifica questo "incollaggio" collegabile. Scriviamo la definizione dell'operazione di natural join nel linguaggio delle formule dei sistemi di gestione di database: r3(S3) = R1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}; Consideriamo un esempio che ben illustra il lavoro di una connessione naturale, il suo "incollaggio". Sia due relazioni r1(S1) e r2(S2), nella forma tabellare di rappresentazione, rispettivamente, uguali: r1(S1):
r2(S2):
Vediamo che queste relazioni hanno tuple che coincidono all'intersezione degli schemi S1 e S2 relazioni. Elenchiamoli: 1) tupla {a, 1} della relazione r1(S1) corrisponde alla tupla {1, x} della relazione r2(S2); 2) tupla {b, 1} da r1(S1) corrisponde anche alla tupla {1, x} di r2(S2); 3) la tupla {c, 3} corrisponde alla tupla {3, z}. Quindi, per unione naturale, la nuova relazione r3(S3) si ottiene "incollando" esattamente su queste tuple. Quindi r3(S3) in una vista tabella apparirà così: r3(S3) = R1(S1)xr2(S2):
Risulta per definizione: schema S3 non coincide con lo schema S1, né con lo schema S2, abbiamo "incollato" i due schemi originali intersecando le tuple per ottenere la loro unione naturale. Mostriamo schematicamente come vengono unite le tuple quando si applica l'operazione di unione naturale. Sia la relazione r1 ha una forma condizionale:
E il rapporto r2 - Visualizza:
Quindi la loro connessione naturale sarà simile a questa:
Vediamo che l'"incollaggio" delle relazioni-operandi avviene secondo lo stesso schema che abbiamo dato in precedenza, considerando l'esempio. Operazione Collegamento cartesiano è un caso speciale dell'operazione di unione naturale. Più precisamente, quando si considera l'effetto dell'operazione del prodotto cartesiano sulle relazioni, si stabilisce volutamente che in questo caso si può parlare solo di schemi di relazioni non intersecantisi. Come risultato dell'applicazione di entrambe le operazioni si ottengono relazioni con schemi uguali all'unione di schemi di relazioni di operandi, solo tutte le possibili coppie delle loro tuple cadono nel prodotto cartesiano di due relazioni, poiché gli schemi di operandi non devono in nessun caso intersecarsi. Quindi, sulla base di quanto sopra, scriviamo una formula matematica per l'operazione del prodotto cartesiano: r4(S4) = R1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2= ∅; Ora esaminiamo un esempio per mostrare come apparirà lo schema di relazione risultante quando si applica l'operazione del prodotto cartesiano. Sia due relazioni r1(S1) e r2(S2), che sono presentati in forma tabellare come segue: r1(S1):
r2(S2):
Quindi vediamo che nessuna delle tuple delle relazioni r1(S1) e r2(S2), infatti, non coincide nella loro intersezione. Pertanto, nella relazione risultante r4(S4) tutte le possibili coppie di tuple delle relazioni del primo e del secondo operando cadranno. Ottenere: r4(S4) = R1(S1)xr2(S2):
Abbiamo ottenuto un nuovo schema di relazioni r4(S4) non "incollando" tuple come nel caso precedente, ma enumerando tutte le possibili diverse coppie di tuple che non corrispondono nell'intersezione degli schemi originali. Anche in questo caso, come nel caso dell'unione naturale, diamo un esempio schematico del funzionamento dell'operazione del prodotto cartesiano. Sia r1 impostare come segue:
E il rapporto r2 dato:
Allora il loro prodotto cartesiano può essere schematicamente rappresentato come segue:
È così che si ottiene la relazione risultante applicando l'operazione del prodotto cartesiano. 3. Proprietà delle operazioni binarie Dalle definizioni di cui sopra delle operazioni binarie di unione, intersezione, differenza, prodotto cartesiano e unione naturale, seguono le proprietà. 1. La prima proprietà, come nel caso delle operazioni unarie, illustra rapporto di potenza relazioni: 1) per l'operazione sindacale: |r1 ∪r2| ≤ |r1| + |r2|; 2) per l'operazione di intersezione: |r1 ∩r2 | ≤ minimo(|r1|, |r2|); 3) per l'operazione di differenza: |r1 \r2| ≤ |r1|; 4) per l'operazione di prodotto cartesiano: |r1 xr2| = |r1| |r2|; 5) per l'operazione di unione naturale: |r1 xr2| ≤ |r1| |r2|. Il rapporto delle potenze, come ricordiamo, caratterizza come il numero di tuple nelle relazioni cambia dopo aver applicato l'una o l'altra operazione. Allora cosa vediamo? Potenza associazioni due relazioni r1 e r2 minore della somma delle cardinalità delle relazioni originali degli operandi. Perché sta succedendo? Il fatto è che quando ti unisci, le tuple corrispondenti scompaiono, sovrapponendosi l'una all'altra. Quindi, facendo riferimento all'esempio che abbiamo considerato dopo aver eseguito questa operazione, puoi vedere che nella prima relazione c'erano due tuple, nella seconda - tre, e nella risultante - quattro, cioè meno di cinque (la somma delle cardinalità delle relazioni-operandi). Mediante la tupla corrispondente {b, 2}, queste relazioni sono "incollate insieme". Potenza risultante incroci due relazioni è minore o uguale alla cardinalità minima delle relazioni operando originali. Passiamo alla definizione di questa operazione: solo le tuple che sono presenti in entrambe le relazioni iniziali entrano nella relazione risultante. Ciò significa che la cardinalità della nuova relazione non può superare la cardinalità della relazione-operando il cui numero di tuple è il più piccolo dei due. E la potenza del risultato può essere uguale a questa cardinalità minima, poiché è sempre ammesso il caso quando tutte le tuple di una relazione con cardinalità inferiore coincidono con alcune tuple della seconda relazione-operando. In caso di operazione differenze tutto è abbastanza banale. Infatti, se tutte le tuple presenti anche nella seconda relazione vengono "sottratte" dalla prima relazione-operando, allora il loro numero (e, di conseguenza, la loro potenza) diminuirà. Nel caso in cui non una singola tupla della prima relazione corrisponda a nessuna tupla della seconda relazione, cioè non c'è nulla da "sottrarre", la sua potenza non diminuirà. È interessante notare che se l'operazione prodotto cartesiano la potenza della relazione risultante è esattamente uguale al prodotto delle potenze delle due relazioni operandi. È chiaro che ciò accade perché tutte le possibili coppie di tuple delle relazioni originali sono scritte nel risultato e nulla è escluso. E infine, l'operazione connessione naturale si ottiene una relazione la cui cardinalità è maggiore o uguale al prodotto delle cardinalità delle due relazioni originarie. Anche in questo caso, ciò accade perché le relazioni degli operandi sono "incollate" da tuple corrispondenti e quelle non corrispondenti sono del tutto escluse dal risultato. 2. Proprietà di idempotenza: 1) per l'operazione di unione: r ∪ r = r; 2) per l'operazione di intersezione: r ∩ r = r; 3) per l'operazione differenziale: r \ r ≠ r; 4) per l'operazione di prodotto cartesiano (nel caso generale la proprietà non è applicabile); 5) per l'operazione di natural join: rxr = r. È interessante notare che la proprietà dell'idempotenza non è vera per tutte le operazioni di cui sopra e per l'operazione del prodotto cartesiano non è affatto applicabile. In effetti, se combini, intersechi o colleghi naturalmente qualsiasi relazione con se stessa, non cambierà. Ma se sottrai da una relazione esattamente uguale ad essa, il risultato sarà una relazione vuota. 3. Proprietà commutativa: 1) per l'operazione sindacale: r1 ∪r2 = r2 ∪r1; 2) per l'operazione di intersezione: r∩r = r∩r; 3) per l'operazione di differenza: r1 \r2 ≠r2 \r1; 4) per l'operazione di prodotto cartesiano: r1 xr2 = r2 xr1; 5) per l'operazione di unione naturale: r1 xr2 = r2 xr1. La proprietà della commutatività vale per tutte le operazioni tranne l'operazione di differenza. Questo è facile da capire, perché la loro composizione (tuple) non cambia dalla riorganizzazione delle relazioni in luoghi. E quando si applica l'operazione di differenza, è importante quale delle relazioni dell'operando viene prima, perché dipende da quali tuple di quale relazione verranno prese come riferimento, cioè con quali tuple verranno confrontate altre tuple per l'esclusione. 4. Proprietà associativa: 1) per l'operazione sindacale: (r1 ∪r2)∪r3 = r1 ∪(r2 ∪r3); 2) per l'operazione di intersezione: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) per l'operazione di differenza: (r1 \r2)\r3 ≠r1 \ (R2 \r3); 4) per l'operazione di prodotto cartesiano: (r1 xr2)xr3 = r1 x(r2 xr3); 5) per l'operazione di unione naturale: (r1 xr2)xr3 = r1 x(r2 xr3). E di nuovo vediamo che la proprietà viene eseguita per tutte le operazioni tranne l'operazione di differenza. Ciò si spiega allo stesso modo del caso dell'applicazione della proprietà di commutatività. In generale, le operazioni di unione, intersezione, differenza e unione naturale non si preoccupano dell'ordine in cui si trovano le relazioni degli operandi. Ma quando le relazioni vengono "portate via" l'una dall'altra, l'ordine gioca un ruolo dominante. Sulla base delle proprietà e del ragionamento di cui sopra, si può trarre la seguente conclusione: le ultime tre proprietà, vale a dire la proprietà di idempotenza, commutatività e associatività, sono vere per tutte le operazioni che abbiamo considerato, ad eccezione dell'operazione della differenza di due relazioni , per la quale nessuna delle tre proprietà indicate risultava soddisfatta, e solo in un caso la proprietà è risultata inapplicabile. 4. Opzioni di operazione di connessione Utilizzando come base le operazioni unarie di selezione, proiezione, ridenominazione e operazioni binarie di unione, intersezione, differenza, prodotto cartesiano e join naturale considerate in precedenza (tutte generalmente sono chiamate operazioni di connessione), possiamo introdurre nuove operazioni derivate utilizzando i concetti e le definizioni di cui sopra. Questa attività è chiamata compilazione. unisci le opzioni di operazione. La prima di queste varianti delle operazioni di join è l'operazione connessione interna secondo la condizione di connessione specificata. L'operazione di un inner join, in base a una condizione specifica, è definita come un'operazione derivata dalle operazioni del prodotto cartesiano e della selezione. Scriviamo la definizione della formula di questa operazione: r1(S1) X P r2(S2) = σ (r1 xr2), S1 ∩S2 =∅; Qui P = P<S1 ∪S2> - una condizione imposta all'unione di due schemi delle originarie relazioni-operandi. È a questa condizione che le tuple vengono selezionate dalle relazioni r1 e r2 nella relazione risultante. Si noti che l'operazione di inner join può essere applicata a relazioni con schemi di relazioni differenti. Questi schemi possono essere qualsiasi, ma in nessun caso devono intersecarsi. Vengono chiamate le tuple degli operandi di relazione originali che sono il risultato dell'operazione di inner join tuple unibili. Per illustrare visivamente il funzionamento dell'operazione di inner join, daremo il seguente esempio. Diamo due relazioni r1(S1) e r2(S2) con diversi schemi di relazione: r1(S1):
r2(S2):
La tabella seguente darà il risultato dell'applicazione dell'operazione di inner join alla condizione P = (b1 = b2). r1(S1) X P r2(S2):
Quindi, vediamo che in effetti lo "sticking" delle due tabelle che rappresentano le relazioni è avvenuto proprio in quelle tuple in cui è soddisfatta la condizione dell'operazione di inner join P = (b1 = b2). Ora, in base all'operazione di inner join già introdotta, possiamo introdurre l'operazione join esterno sinistro и unione esterna destra. Spieghiamo. Il risultato dell'operazione left outer join è il risultato della inner join, completata con tuple non unibili della relazione-operando left source. Allo stesso modo, il risultato di un'operazione di join esterno destro è definito come il risultato di un'operazione di inner join aumentata con tuple non unibili dell'operando di relazione di origine destrorso. La domanda su come vengono reintegrate le relazioni risultanti delle operazioni dei giunti esterni sinistro e destro è abbastanza prevedibile. Le tuple di un operando di relazione sono completate sullo schema di un altro operando di relazione Valori nulli. Vale la pena notare che le operazioni di join esterno sinistro e destro introdotte in questo modo sono operazioni derivate dall'operazione di inner join. Per scrivere le formule generali per le operazioni di unione esterna sinistra e destra, eseguiremo alcune costruzioni aggiuntive. Diamo due relazioni r1(S1) e r2(S2) con diversi schemi di relazioni S1 e S2, che non si intersecano. Poiché abbiamo già stabilito che le operazioni di join interno sinistro e destro sono derivati, possiamo ottenere le seguenti formule ausiliarie per determinare l'operazione di join esterno sinistro: 1) r3 (S2 ∪S1) ≔ r1(S1) X Pr2(S2); r 3 (S2 ∪S1) è semplicemente il risultato dell'unione interna delle relazioni r1(S1) e r2(S2). Il left outer join è un'operazione derivata dall'operazione di inner join, motivo per cui iniziamo le nostre costruzioni con esso; 2) r4(S1) ≔ r 3(S2 ∪S1) [S1]; Quindi, con l'aiuto di un'operazione di proiezione unaria, abbiamo selezionato tutte le tuple unibili dell'operando relazione iniziale sinistro r1(S1). Il risultato è designato r4(S1) per facilità d'uso; 3) r5 (S1) ≔ r1(S1)\r4(S1); Qui r1(S1) sono tutte tuple dell'operando di relazione sorgente sinistro e r4(S1) - le sue tuple, solo connesse. Quindi, usando l'operazione binaria della differenza, rispetto a r5(S1) abbiamo ottenuto tutte le tuple non unibili della relazione dell'operando sinistro; 4) r6(S2)≔{∅(S2)}; {∅(s2)} è una nuova relazione con lo schema (S2) contenente solo una tupla e composta da valori Null. Per comodità, abbiamo indicato questo rapporto come r6(S2); 5) r7 (S2 ∪S1) ≔ r5(S1)xr6(S2); Qui abbiamo preso le tuple non connesse della relazione dell'operando sinistro (r5(S1)) e li ha integrati sullo schema del secondo operando di relazione S2 I valori nulli, cioè cartesiani, hanno moltiplicato la relazione costituita da queste stesse tuple non unificabili per la relazione r6(S2) definito al comma quattro; 6) r1(S1)→x P r2(S2) ≔ (r1 x P r2)∪r7 (S2 ∪S1); Questo è join esterno sinistro, ottenuto, come si vede, dall'unione del prodotto cartesiano delle relazioni-operandi originari r1 e r2 e relazioni r7 (S2 ∪ S1) definito al paragrafo XNUMX. Ora abbiamo tutti i calcoli necessari per determinare non solo il funzionamento del join esterno sinistro, ma per analogia e per determinare il funzionamento del join esterno destro. Così: 1) operazione join esterno sinistro in forma rigorosa si presenta così: r1(S1)→x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \ (R1 x P r2) [S1]) x {∅(S2)}]; 2) operazione unione esterna destra è definito in modo simile all'operazione di join esterno sinistro e ha la forma seguente: r1(S1)→x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \ (R1 x P r2) [S2]) x {∅(S1)}]; Queste due operazioni derivate hanno solo due proprietà degne di nota. 1. Proprietà di commutatività: 1) per l'operazione di join esterno sinistro: r1(S1)→x P r2(S2) ≠r2(S2)→x P r1(S1); 2) per l'operazione di join esterno destro: r1(S1) ←x P r2(S2) ≠r2(S2) ←x P r1(S1) Quindi, vediamo che la proprietà di commutatività non è soddisfatta per queste operazioni in termini generali, ma le operazioni dei join esterni sinistro e destro sono reciprocamente inverse, vale a dire, è vero quanto segue: 1) per l'operazione di join esterno sinistro: r1(S1)→x P r2(S2) = R2(S2)→x P r1(S1); 2) per l'operazione di join esterno destro: r1(S1) ←x P r2(S2) = R2(S2) ←x Pr1(S1). 2. La proprietà principale delle operazioni di join esterno sinistro e destro è che consentono восстановить la relazione-operando iniziale in base al risultato finale di una particolare operazione di unione, ovvero si eseguono le seguenti operazioni: 1) per l'operazione di join esterno sinistro: r1(S1) = (r1 →x P r2) [S1]; 2) per l'operazione di join esterno destro: r2(S2) = (r1 ←x P r2) [S2]. Quindi, vediamo che il primo operando relazione originale può essere ripristinato dal risultato dell'operazione di join sinistra-destra, e più specificamente, applicando al risultato di questo join (r1 xr2) l'operazione unaria di proiezione sullo schema S1, [S1]. E allo stesso modo, la seconda relazione-operando originale può essere ripristinata applicando il join esterno destro (r1 xr2) l'operazione unaria di proiezione sullo schema della relazione S2. Diamo un esempio per una considerazione più dettagliata del funzionamento delle operazioni dei join esterni sinistro e destro. Introduciamo le già note relazioni r1(S1) e r2(S2) con diversi schemi di relazione: r1(S1):
r2(S2):
Tupla non unificabile dell'operando relazionale sinistro r2(S2) è una tupla {d, 4}. Seguendo la definizione, sono loro che dovrebbero completare il risultato della connessione interna delle due relazioni originali dell'operando. Condizione di unione interna delle relazioni r1(S1) e r2(S2) lasciamo anche lo stesso: P = (b1 = b2). Poi il risultato dell'operazione join esterno sinistro ci sarà la seguente tabella: r1(S1)→x P r2(S2):
Infatti, come possiamo vedere, come risultato dell'impatto dell'operazione di left external join, il risultato dell'operazione di inner join è stato reintegrato con tuple non unibili di sinistra, ovvero, nel nostro caso, la prima relazione- operando. Il riempimento della tupla nello schema del secondo (destra) relazione-operando sorgente, per definizione, è avvenuto con l'aiuto di valori Nulli. E simile al risultato unione esterna destra come prima, la condizione P = (b1 = b2) delle relazioni-operandi originari r1(S1) e r2(S2) è la seguente tabella: r1(S1) ←x P r2(S2):
Infatti, in questo caso, il risultato dell'operazione di inner join dovrebbe essere reintegrato con tuple non unibili di destra, nel nostro caso, la seconda relazione-operando iniziale. Tale tupla, come non è difficile da vedere, nella seconda relazione r2(S2) uno, vale a dire {2, y}. Successivamente, agiamo sulla definizione dell'operazione del join esterno destro, integriamo la tupla del primo operando (sinistro) nello schema del primo operando con valori Null. Infine, diamo un'occhiata alla terza versione delle operazioni di join sopra. Operazione di join esterno completo. Questa operazione può essere considerata non solo come un'operazione derivata da operazioni di inner join, ma anche come un'unione di operazioni di outer join sinistra e destra. Operazione di join esterno completo è definito come il risultato del completamento dello stesso inner join (come nel caso della definizione di outer join sinistro e destro) con tuple non unibili di entrambe le relazioni dell'operando iniziale sinistro e destro. Sulla base di questa definizione, diamo la forma formulativa di questa definizione: r1(S1) ↔x P r2(S2) = (r1 →x P r2) ∪ (r1 ←x P r2); L'operazione di join esterno completo ha anche una proprietà simile a quella delle operazioni di join esterno sinistro e destro. Solo a causa della natura reciproca originale dell'operazione di unione esterna completa (dopotutto era definita come l'unione delle operazioni di unione esterna sinistra e destra), esegue proprietà di commutatività: r1(S1) ↔x P r2(S2)=r2(S2) ↔x P r1(S1); E per completare la considerazione delle opzioni per le operazioni di join, diamo un'occhiata a un esempio che illustra il funzionamento di un'operazione di join esterno completo. Introduciamo due relazioni r1(S1) e r2(S2) e la condizione di unione. lasciare r1(S1)
r2(S2):
E lasciamo che la condizione di connessione delle relazioni r1(S1) e r2(S2) sarà: P = (b1 = b2), come negli esempi precedenti. Quindi il risultato dell'operazione di join esterno completo delle relazioni r1(S1) e r2(S2) dalla condizione P = (b1 = b2) si avrà la seguente tabella: r1(S1) ↔x P r2(S2):
Quindi, vediamo che l'operazione di join esterno completo giustifica chiaramente la sua definizione come unione dei risultati delle operazioni di join esterno sinistro e destro. La relazione risultante dell'operazione di inner join è completata da tuple simultanee non unibili come la sinistra (first, r1(S1)), ea destra (secondo, r2(S2)) della relazione-operando originaria. 5. Operazioni su derivati Quindi, abbiamo considerato varie varianti delle operazioni di join, vale a dire le operazioni di inner join, left, right e full external join, che sono derivati dalle otto operazioni originali dell'algebra relazionale: operazioni unarie di selezione, proiezione, ridenominazione e operazioni binarie di unione, intersezione, differenza, prodotto cartesiano e connessione naturale. Ma anche tra queste operazioni originali ci sono esempi di operazioni derivate. 1. Ad esempio, operazione incroci due rapporti è una derivata dell'operazione della differenza degli stessi due rapporti. Mostriamolo. L'operazione di intersezione può essere espressa dalla seguente formula: r1(S)∩r2(S) = R1 \r1 \r2 oppure, che dà lo stesso risultato: r1(S)∩r2(S) = R2 \r2 \r1; 2. Un altro esempio, la derivata dell'operazione di base dalle otto operazioni originali è l'operazione connessione naturale. Nella sua forma più generale, questa operazione deriva dall'operazione binaria del prodotto cartesiano e dalle operazioni unarie di selezione, proiezione e ridenominazione degli attributi. Tuttavia, a sua volta, l'operazione di inner join è un'operazione derivata della stessa operazione del prodotto cartesiano delle relazioni. Pertanto, per dimostrare che un'operazione di join naturale è un'operazione derivata, si consideri l'esempio seguente. Confrontiamo gli esempi precedenti per le operazioni di unione naturale e interna. Diamo due relazioni r1(S1) e r2(S2) che fungeranno da operandi. Sono uguali: r1(S1):
r2(S2):
Come abbiamo già ricevuto in precedenza, il risultato dell'operazione di join naturale di queste relazioni sarà una tabella della forma seguente: r3(S3) ≔ r1(S1)xr2(S2):
E il risultato dell'unione interna delle stesse relazioni r1(S1) e r2(S2) dalla condizione P = (b1 = b2) si avrà la seguente tabella: r4(S4) ≔ r1(S1) X P r2(S2):
Confrontiamo questi due risultati, le nuove relazioni risultanti r3(S3) e r4(S4). È chiaro che l'operazione di unione naturale si esprime attraverso l'operazione di unione interna, ma, soprattutto, con una condizione di unione di una forma speciale. Scriviamo una formula matematica che descrive l'azione dell'operazione di unione naturale come una derivata dell'operazione di unione interna. r1(S1)xr2(S2) = { ρ<ϕ1>r1 x E ρ< ϕ2>r2}[S1 ∪S2], dove E - condizione di connettività tuple; E= ∀a ∈S1 ∩S2 [ÈNull(b1) & ÈNullo(2) ∪b1 = b2]; b1 = φ1 (nome(a)), b2 = φ2 (nome(a)); Ecco uno di rinominare le funzioni ϕ1 è identica e un'altra funzione di ridenominazione (vale a dire, ϕ2) rinomina gli attributi in cui i nostri schemi si intersecano. La condizione di connettività E per le tuple è scritta in forma generale, tenendo conto della possibile occorrenza di valori Null, poiché l'operazione di inner join (come menzionato sopra) è un'operazione derivata dall'operazione del prodotto cartesiano di due relazioni e del operazione di selezione unaria. 6. Espressioni di algebra relazionale Mostriamo come le espressioni e le operazioni di algebra relazionale considerate in precedenza possono essere utilizzate nel funzionamento pratico di vari database. Mettiamo, ad esempio, a nostra disposizione un frammento di qualche database commerciale: Fornitori (Codice fornitore, Nome del venditore, Città del venditore); Strumenti (Codice utensile, Nome utensile,...); Consegne (Codice fornitore, Codice componente); I nomi degli attributi sottolineati[1] sono attributi chiave (cioè identificativi), ciascuno nella propria relazione. Supponiamo che a noi, come sviluppatori di questo database e custodi delle informazioni su questo argomento, venga ordinato di ottenere i nomi dei fornitori (Supplier Name) e la loro ubicazione (Supplier City) nel caso in cui questi fornitori non forniscano strumenti con un nome generico "Pinza". Per determinare tutti i fornitori che soddisfano questo requisito nel nostro database forse molto grande, scriviamo alcune espressioni di algebra relazionale. 1. Formiamo un raccordo naturale dei rapporti "Fornitori" e "Forniture" al fine di far corrispondere con ciascun fornitore i codici dei pezzi da lui forniti. La nuova relazione - frutto dell'applicazione dell'operazione di unione naturale - per comodità di ulteriore applicazione, indichiamo con r1. Fornitori x Forniture ≔ r1 (Codice fornitore, nome fornitore, città fornitore, Tra parentesi abbiamo elencato tutti gli attributi delle relazioni coinvolte in questa operazione di join naturale. Possiamo vedere che l'attributo "Vendor ID" è duplicato, ma nel record di riepilogo della transazione, ogni nome di attributo dovrebbe apparire solo una volta, ovvero: Fornitori x Forniture ≔ r1 (Codice fornitore, nome fornitore, città fornitore, codice strumento); 2. ancora una volta si forma un nesso naturale, solo questa volta il rapporto ottenuto nel comma uno e il rapporto Strumenti. Lo facciamo per far corrispondere il nome di questo utensile con ogni codice utensile ottenuto nel paragrafo precedente. r1 x Utensili [Codice utensile, Nome utensile] ≔ r2 (Codice fornitore, nome fornitore, città fornitore, Il risultato risultante sarà indicato con r2, sono esclusi gli attributi duplicati: r1 x Utensili [Codice utensile, Nome utensile] ≔ r2 (Codice fornitore, nome fornitore, città fornitore, codice strumento, nome strumento); Si noti che prendiamo solo due attributi dalla relazione Strumenti: "Codice utensile" e "Nome utensile". Per fare questo, come si evince dalla notazione della relazione r2, ha applicato l'operazione di proiezione unaria: Strumenti [Codice utensile, Nome utensile], ovvero, se la relazione Strumenti fosse presentata come una tabella, il risultato di questa operazione di proiezione sarebbero le prime due colonne con le intestazioni "Codice utensile" e "Strumento nome" rispettivamente ". È interessante notare che i primi due passaggi che abbiamo già considerato sono abbastanza generali, ovvero possono essere utilizzati per implementare eventuali altre richieste. Ma i prossimi due punti, a loro volta, rappresentano passi concreti per raggiungere il compito specifico che ci è stato assegnato. 3. Scrivere un'operazione di selezione unaria secondo la condizione <"Nome utensile" = "Pinza"> in relazione al rapporto r2ottenuto nel paragrafo precedente. E noi, a nostra volta, applichiamo l'operazione di proiezione unaria [Codice fornitore, Nome fornitore, Città fornitore] al risultato di questa operazione per ottenere tutti i valori di questi attributi, perché dobbiamo ottenere queste informazioni in base al ordine. Quindi: (σ<Nome utensile = "Pinza"> r2) [Codice fornitore, nome fornitore, città fornitore] ≔ r3 (Codice fornitore, Nome fornitore, Città fornitore, Codice utensile, Nome utensile). Nel rapporto risultante, indicato con r3, solo quei fornitori (con tutti i loro dati identificativi) sono risultati fornire strumenti con il nome generico "Pinza". Ma in virtù dell'ordinanza, occorre individuare quei fornitori che, al contrario, non forniscono tali strumenti. Quindi, passiamo al passaggio successivo del nostro algoritmo e scriviamo l'ultima espressione di algebra relazionale, che ci darà le informazioni che stiamo cercando. 4. Innanzitutto, facciamo la differenza tra il rapporto "Fornitori" e il rapporto r3e dopo aver applicato questa operazione binaria, applichiamo l'operazione di proiezione unaria sugli attributi "Nome fornitore" e "Città fornitore". (Fornitori\r3) [Nome fornitore, città fornitore] ≔ r4 (Codice fornitore, nome fornitore, città fornitore); Il risultato è designato r4, questa relazione includeva proprio quelle tuple della relazione originale "Fornitori" che corrispondono alla condizione del nostro ordine. Quindi, abbiamo mostrato come, usando espressioni e operazioni di algebra relazionale, puoi eseguire tutti i tipi di azioni con database arbitrari, eseguire vari ordini, ecc. Lezione n. 6. Linguaggio SQL Diamo prima un piccolo retroscena storico. Il linguaggio SQL, progettato per interagire con i database, è apparso a metà degli anni '1970. (le prime pubblicazioni risalgono al 1974) ed è stato sviluppato da IBM nell'ambito di un progetto sperimentale di sistema di gestione di database relazionali. Il nome originale della lingua è SEQUEL (Structured English Query Language) - rifletteva solo in parte l'essenza di questo linguaggio. Inizialmente, subito dopo la sua invenzione e durante il periodo principale di funzionamento del linguaggio SQL, il suo nome era l'abbreviazione della frase Structured Query Language, che si traduce come "Structured Query Language". Naturalmente, il linguaggio si è concentrato principalmente sulla formulazione di interrogazioni a database relazionali che risultasse conveniente e comprensibile per gli utenti. Ma, in effetti, quasi fin dall'inizio, era un linguaggio di database completo, fornendo, oltre ai mezzi per formulare query e manipolare database, le seguenti caratteristiche: 1) mezzi per definire e manipolare lo schema della banca dati; 2) mezzi per definire vincoli di integrità e trigger (di cui si parlerà in seguito); 3) modalità di definizione delle viste del database; 4) mezzi per definire strutture di livello fisico che supportino l'efficiente esecuzione delle richieste; 5) modalità di autorizzazione all'accesso alle relazioni e ai loro campi. Il linguaggio mancava dei mezzi per sincronizzare esplicitamente l'accesso agli oggetti del database dal lato delle transazioni parallele: sin dall'inizio si presumeva che la sincronizzazione necessaria fosse implicitamente eseguita dal sistema di gestione del database. Attualmente SQL non è più un'abbreviazione, ma il nome di una lingua indipendente. Inoltre, attualmente, il linguaggio di query strutturato è implementato in tutti i sistemi di gestione di database relazionali commerciali e in quasi tutti i DBMS che originariamente non erano basati su un approccio relazionale. Tutte le aziende manifatturiere affermano che la loro implementazione è conforme allo standard SQL, e infatti i dialetti implementati dello Structured Query Language sono molto simili. Ciò non è stato ottenuto immediatamente. Una caratteristica della maggior parte dei moderni sistemi di gestione di database commerciali che rende difficile confrontare i dialetti SQL esistenti è la mancanza di una descrizione uniforme del linguaggio. In genere, la descrizione è sparpagliata in vari manuali e mescolata con una descrizione delle caratteristiche del linguaggio specifiche del sistema che non sono direttamente correlate al linguaggio di query strutturato. Tuttavia, si può affermare che l'insieme di base di istruzioni SQL, che include istruzioni per determinare lo schema del database, recuperare e manipolare dati, autorizzare l'accesso ai dati, supporto per incorporare SQL nei linguaggi di programmazione e istruzioni SQL dinamiche, è ben consolidato in implementazioni commerciali e più o meno conforme alla norma. Con il tempo e il lavoro sullo Structured Query Language, è stato possibile ottenere uno standard per una chiara standardizzazione della sintassi e della semantica delle istruzioni di recupero dati, manipolazione dei dati e correzione dei vincoli di integrità del database. Sono stati specificati i mezzi per definire le chiavi primarie ed esterne delle relazioni e i cosiddetti vincoli di verifica dell'integrità, che sono un sottoinsieme di vincoli di integrità SQL immediatamente verificati. Gli strumenti per la definizione di chiavi esterne consentono di formulare facilmente i requisiti della cosiddetta integrità referenziale dei database (di cui parleremo più avanti). Questo requisito, comune nei database relazionali, potrebbe essere formulato anche sulla base del meccanismo generale dei vincoli di integrità SQL, ma la formulazione basata sul concetto di chiave esterna è più semplice e comprensibile. Quindi, tenendo conto di tutto ciò, attualmente il linguaggio di query strutturato non è solo il nome di una lingua, ma il nome di un'intera classe di linguaggi, poiché, nonostante gli standard esistenti, vengono implementati vari dialetti del linguaggio di query strutturato in vari sistemi di gestione di database, che, ovviamente, hanno una base comune. 1. L'istruzione Select è l'istruzione di base del linguaggio di query strutturato Il posto centrale nel linguaggio di query strutturato SQL è occupato dall'istruzione Select, che implementa l'operazione più richiesta quando si lavora con i database: le query. L'istruzione Select valuta sia le espressioni algebriche relazionali che quelle pseudo-relazionali. In questo corso considereremo l'implementazione delle sole operazioni unarie e binarie dell'algebra relazionale di cui abbiamo già parlato, nonché l'implementazione di query utilizzando le cosiddette subquery. A proposito, va notato che nel caso di lavoro con operazioni di algebra relazionale, nelle relazioni risultanti possono apparire tuple duplicate. Non esiste un divieto rigoroso contro la presenza di righe duplicate nelle relazioni nelle regole del linguaggio di query strutturato (a differenza della normale algebra relazionale), quindi non è necessario escludere i duplicati dal risultato. Diamo quindi un'occhiata alla struttura di base dell'istruzione Select. È abbastanza semplice e include le seguenti frasi obbligatorie standard: Selezionare... Da ... Dove... ; Al posto dei puntini di sospensione in ogni riga dovrebbero esserci relazioni, attributi e condizioni di un particolare database e attività per esso. Nel caso più generale, la struttura di selezione di base dovrebbe assomigliare a questa: Seleziona seleziona alcuni attributi Da da una tale relazione Dove con tali e tali condizioni per tuple di campionamento Quindi, selezioniamo gli attributi dallo schema delle relazioni (intestazioni di alcune colonne), indicando da quali relazioni (e, come puoi vedere, possono essercene diverse) facciamo la nostra selezione e, infine, in base a quali condizioni ci fermiamo la nostra scelta su alcune tuple. È importante notare che i riferimenti agli attributi vengono effettuati utilizzando i loro nomi. Si ottiene così quanto segue algoritmo di lavoro questa istruzione di base Select: 1) si ricordano le condizioni per selezionare le tuple dalla relazione; 2) viene verificato quali tuple soddisfano le proprietà specificate. Tali tuple vengono ricordate; 3) vengono emessi gli attributi elencati nella prima riga della struttura di base dell'istruzione Select con i relativi valori. (Se parliamo della forma tabulare della relazione, verranno visualizzate quelle colonne della tabella le cui intestazioni sono state elencate come attributi necessari; ovviamente, le colonne non verranno visualizzate completamente, in ognuna di esse solo quelle tuple che soddisfano le condizioni indicate rimarranno.) Si consideri un esempio. Diamo la seguente relazione r1, come frammento di alcuni database di librerie:
Supponiamo di avere anche la seguente espressione con l'istruzione Select: Seleziona Titolo del libro, Autore del libro Da r1 Dove Prezzo libro > 200; Il risultato di questo operatore sarà il seguente frammento di tupla: (Telefono cellulare, S. King). (In quanto segue, considereremo molti esempi di implementazioni di query che utilizzano questa struttura di base e ne studieremo l'applicazione in dettaglio.) 2. Operazioni unarie nel linguaggio delle query strutturate In questa sezione considereremo come le già familiari operazioni unarie di selezione, proiezione e ridenominazione vengono implementate nel linguaggio di query strutturato utilizzando l'operatore Select. È importante notare che se prima potessimo lavorare solo con singole operazioni, allora anche una singola istruzione Select nel caso generale ci consente di definire un'intera espressione di algebra relazionale e non solo una singola operazione. Procediamo quindi direttamente all'analisi della rappresentazione delle operazioni unarie nel linguaggio delle query strutturate. 1. Operazione di campionamento. L'operazione di selezione in SQL è implementata dall'istruzione Select della seguente forma: Seleziona tutti gli attributi Da nome della relazione Dove condizione di selezione; Qui, invece di scrivere "tutti gli attributi", puoi usare il segno "*". Nella teoria del linguaggio di query strutturato, questa icona significa selezionare tutti gli attributi dallo schema di relazione. La condizione di selezione qui (e in tutte le altre implementazioni di operazioni) è scritta come un'espressione logica con connettivi standard not (not) e (and) o (or). Gli attributi di relazione sono indicati con i loro nomi. Considera un esempio. Definiamo il seguente schema di relazioni: rendimento scolastico (Numero registro, semestre, codice materia, Valutazione, Data); Qui, come accennato in precedenza, gli attributi sottolineati formano la chiave di relazione. Componiamo un'istruzione Select della forma seguente, che implementa l'operazione di selezione unaria: Seleziona * Dal rendimento scolastico Dove Registro dei voti # = 100 e Semestre = 6; È chiaro che per effetto di questo operatore, la macchina visualizzerà i progressi dello studente con il numero del record di cento per il sesto semestre. 2. Operazione di proiezione. L'operazione di proiezione nello Structured Query Language è ancora più facile da implementare rispetto all'operazione di recupero. Ricordiamo che quando si applica l'operazione di proiezione, non vengono selezionate le righe (come quando si applica l'operazione di selezione), ma le colonne. Pertanto, è sufficiente elencare le intestazioni delle colonne richieste (cioè i nomi degli attributi), senza specificare condizioni estranee. In totale, otteniamo un operatore della seguente forma: Seleziona elenco di nomi di attributi Da nome della relazione; Dopo aver applicato questa istruzione, la macchina restituirà quelle colonne della tabella delle relazioni i cui nomi sono stati specificati nella prima riga di questa istruzione Select. Come accennato in precedenza, non è necessario escludere righe e colonne duplicate dalla relazione risultante. Ma se in un ordine o in un'attività è necessario eliminare i duplicati, è necessario utilizzare un'opzione speciale del linguaggio di query strutturato - distinto. Questa opzione imposta l'eliminazione automatica delle tuple duplicate dalla relazione. Con questa opzione applicata, l'istruzione Select apparirà così: Seleziona elenco distinto di nomi di attributi Da nome della relazione; In SQL esiste una notazione speciale per gli elementi opzionali delle espressioni: parentesi quadre [...]. Pertanto, nella sua forma più generale, l’operazione di proiezione sarà simile a questa: Seleziona [distinto] elenco di nomi di attributi Da nome della relazione; Tuttavia, se è garantito che il risultato dell'applicazione dell'operazione non contenga duplicati, o i duplicati sono ancora ammissibili, allora l'opzione distinto meglio non specificare per non ingombrare la scheda, cioè per ragioni di performance dell'operatore. Consideriamo un esempio che illustra la possibilità di una fiducia del XNUMX% in assenza di duplicati. Sia dato lo schema delle relazioni a noi già noto: rendimento scolastico (Numero registro, semestre, codice materia, Valutazione, Data). Sia data la seguente istruzione Select: Seleziona Numero registro, semestre, codice materia Da rendimento scolastico; Qui è facile vedere che i tre attributi restituiti dall'operatore formano la chiave della relazione. Ecco perché l'opzione distinto diventa ridondante, perché è garantito l'assenza di duplicati. Ciò deriva da un requisito sulle chiavi chiamato vincolo univoco. Considereremo questa proprietà in modo più dettagliato in seguito, ma se l'attributo è chiave, non ci sono duplicati in esso. 3. Rinominare l'operazione. L'operazione di ridenominazione degli attributi nel linguaggio di query strutturato è abbastanza semplice. Vale a dire, è incarnato in realtà dal seguente algoritmo: 1) nell'elenco dei nomi degli attributi della frase Select sono elencati gli attributi che devono essere rinominati; 2) la parola chiave speciale as viene aggiunta a ciascun attributo specificato; 3) dopo ogni occorrenza della parola as, viene indicato il nome dell'attributo corrispondente, a cui è necessario modificare il nome originario. Pertanto, tenendo conto di tutto quanto sopra, l'operatore corrispondente all'operazione di ridenominazione degli attributi sarà simile al seguente: Seleziona nome attributo 1 come nuovo nome attributo 1,... Da nome della relazione; Mostriamo come funziona questo operatore con un esempio. Sia dato lo schema di relazioni a noi già familiare: rendimento scolastico (Numero registro, semestre, codice materia,Valutazione, Data); Diamo un ordine per modificare i nomi di alcuni attributi, ovvero, al posto di "Numero registro" dovrebbe esserci "Numero account" e invece di "Punteggio" - "Punteggio". Scriviamo come apparirà l'istruzione Select che implementa questa operazione di ridenominazione: Seleziona registro come numero di registrazione, semestre, codice materia, voto come punteggio, data Da rendimento scolastico; Pertanto, il risultato dell'applicazione di questo operatore sarà un nuovo schema di relazione che differisce dallo schema di relazione "Achievement" originale nei nomi di due attributi. 3. Operazioni binarie nel linguaggio delle query strutturate Come le operazioni unarie, anche le operazioni binarie hanno la propria implementazione nel linguaggio di query strutturato o SQL. Consideriamo quindi l'implementazione in questo linguaggio delle operazioni binarie che abbiamo già superato, ovvero le operazioni di unione, intersezione, differenza, prodotto cartesiano, natural join, inner e left, right, full external join. 1. Operazione sindacale. Per implementare l'operazione di combinazione di due relazioni, è necessario utilizzare contemporaneamente due operatori Select, ognuno dei quali corrisponde ad una delle relazioni-operandi originari. E un'operazione speciale deve essere applicata a queste due istruzioni di base Select Unione. Considerando tutto quanto sopra, scriviamo come apparirà l'operazione di unione usando la semantica del linguaggio di query strutturato: Seleziona elenca i nomi degli attributi della relazione 1 Da nome della relazione 1 Unione Seleziona elenca i nomi degli attributi della relazione 2 Da nome della relazione 2; È importante notare che gli elenchi dei nomi degli attributi delle due relazioni unite devono fare riferimento ad attributi di tipi compatibili ed essere elencati in ordine coerente. Se questo requisito non viene soddisfatto, la tua richiesta non può essere soddisfatta e il computer visualizzerà un messaggio di errore. Ma ciò che è interessante notare è che i nomi degli attributi stessi in queste relazioni possono essere diversi. In questo caso, alla relazione risultante vengono assegnati i nomi degli attributi specificati nella prima istruzione Select. È inoltre necessario sapere che l'utilizzo dell'operazione di unione esclude automaticamente tutte le tuple duplicate dalla relazione risultante. Pertanto, se è necessario che tutte le righe duplicate siano conservate nel risultato finale, invece dell'operazione di Unione, è necessario utilizzare una modifica di questa operazione: l'operazione Unione tutto. In questo caso, l'operazione di combinazione di due relazioni sarà simile a questa: Seleziona elenca i nomi degli attributi della relazione 1 Da nome della relazione 1 Unione tutto Seleziona elenca i nomi degli attributi della relazione 2 Da nome della relazione 2; In questo caso, le tuple duplicate non verranno rimosse dalla relazione risultante. Usando la notazione menzionata in precedenza per gli elementi opzionali e le opzioni nelle istruzioni Select, scriviamo la forma più generale dell'operazione di unione di due relazioni nel linguaggio di query strutturato: Seleziona elenca i nomi degli attributi della relazione 1 Da nome della relazione 1 Unione [Tutti] Seleziona elenca i nomi degli attributi della relazione 2 Da nome della relazione 2; 2. Operazione di intersezione. L'operazione di intersezione e l'operazione di differenza di due relazioni nel linguaggio di interrogazione strutturato sono implementate in modo simile (consideriamo il metodo di rappresentazione più semplice, poiché più semplice è il metodo, più economico, più rilevante e, quindi, il più richiesto). Quindi, analizzeremo il modo per implementare l'operazione di intersezione utilizzando chiavi. Questo metodo prevede la partecipazione di due costrutti Select, ma non sono uguali (come nella rappresentazione dell'operazione sindacale), uno di essi è, per così dire, una "sottocostruzione", "sottociclo". Di solito viene chiamato un tale operatore sottoquery. Quindi, supponiamo di avere due schemi di relazione (R1 e R2), grosso modo definito come segue: R1 (chiave,...) e R2 (chiave,...); Durante la registrazione di questa operazione, utilizzeremo anche l'opzione speciale in, che letteralmente significa "in" o (come in questo caso particolare) "contenuto in". Quindi, tenendo conto di tutto quanto sopra, l'operazione di intersezione di due relazioni utilizzando il linguaggio di query strutturato sarà scritta come segue: Seleziona * Da R1 Dove digitare (Seleziona ключ Da R2); Quindi, vediamo che la sottoquery in questo caso sarà l'operatore tra parentesi. Questa sottoquery nel nostro caso restituisce un elenco di valori chiave della relazione R2. E, come segue dalla nostra notazione degli operatori, dall'analisi della condizione di selezione, solo quelle tuple della relazione R cadranno nella relazione risultante1, la cui chiave è contenuta nell'elenco delle chiavi della relazione R2. Cioè, nella relazione finale, se ricordiamo la definizione dell'intersezione di due relazioni, rimarranno solo quelle tuple che appartengono ad entrambe le relazioni. 3. Operazione di differenza. Come accennato in precedenza, l'operazione unaria della differenza di due relazioni è implementata in modo simile all'operazione di intersezione. Qui, oltre alla query principale con l'operatore Seleziona, viene utilizzata una seconda query ausiliaria, la cosiddetta sottoquery. Ma a differenza dell'implementazione dell'operazione precedente, quando si implementa l'operazione di differenza, è necessario utilizzare un'altra parola chiave, vale a dire Non in, che nella traduzione letterale significa "non in" oppure (come è opportuno tradurre nel nostro caso in esame) - "non è contenuto in". Quindi, come nell'esempio precedente, abbiamo due schemi di relazione (R1 e R2), data approssimativamente da: R1 (chiave,...) e R2 (chiave,...); Come puoi vedere, gli attributi chiave sono nuovamente impostati tra gli attributi di queste relazioni. Pertanto, otteniamo il seguente modulo per rappresentare l'operazione di differenza nel linguaggio di query strutturato: Seleziona * Da R1 Dove ключ Non in (Seleziona ключ Da R2); Pertanto, solo quelle tuple della relazione R1, la cui chiave non è contenuta nell'elenco delle chiavi della relazione R2. Se consideriamo la notazione alla lettera, risulta davvero che dalla relazione R1 "sottrai" il rapporto R2. Da qui concludiamo che la condizione di selezione in questo operatore è scritta correttamente (dopotutto viene eseguita la definizione della differenza di due relazioni) e l'uso delle chiavi, come nel caso dell'implementazione dell'operazione di intersezione, è pienamente giustificato . I due usi del "metodo chiave" che abbiamo visto sono i più comuni. Si conclude così lo studio dell'uso delle chiavi nella costruzione di operatori che rappresentano relazioni. Tutte le restanti operazioni binarie dell'algebra relazionale sono scritte in altri modi. 4. Funzionamento del prodotto cartesiano Come ricordiamo dalle lezioni precedenti, il prodotto cartesiano di due relazioni-operandi è composto come un insieme di tutte le possibili coppie di valori nominati di tuple su attributi. Pertanto, nel linguaggio di query strutturato, l'operazione del prodotto cartesiano viene implementata utilizzando un cross join, indicato dalla parola chiave unione incrociata, che si traduce letteralmente in "cross join" o "cross join". C'è un solo operatore Select nella struttura che rappresenta l'operazione del prodotto cartesiano nel Structured Query Language e ha la forma seguente: Seleziona * Da R1 unione incrociata R2 qui R1 e R2 - nomi delle relazioni iniziali-operandi. Opzione unione incrociata assicura che la relazione risultante contenga tutti gli attributi (tutti, perché la prima riga dell'operatore ha il segno "*") corrispondenti a tutte le coppie di tuple di relazione R1 e R2. È molto importante ricordare una caratteristica dell'implementazione del funzionamento del prodotto cartesiano. Questa caratteristica è conseguenza della definizione dell'operazione binaria del prodotto cartesiano. Ricordalo: r4(S4) = R1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2=∅; Come si può vedere dalla definizione di cui sopra, le coppie di tuple sono formate con schemi di relazioni necessariamente non intersecanti. Pertanto, quando si lavora nel linguaggio di query strutturato SQL, è invariabilmente stabilito che le relazioni degli operandi iniziali non devono avere nomi di attributi corrispondenti. Ma se queste relazioni hanno ancora gli stessi nomi, la situazione attuale può essere facilmente risolta usando l'operazione di ridenominazione degli attributi, cioè in questi casi basta usare l'opzione as, di cui si è parlato prima. Consideriamo un esempio in cui dobbiamo trovare il prodotto cartesiano di due relazioni che hanno alcuni degli stessi nomi di attributi. Quindi, date le seguenti relazioni: R1 (A, B), R2 (AVANTI CRISTO); Vediamo che gli attributi R1.B e R2.B hanno gli stessi nomi. Tenendo presente questo, l'istruzione Select che implementa questa operazione del prodotto cartesiano nel linguaggio di query strutturato sarà simile a questa: Seleziona A, R1.B as B1, r2.B as B2, DO Da R1 unione incrociata R2; Pertanto, utilizzando l'opzione di ridenominazione come, la macchina non avrà "domande" sui nomi corrispondenti delle due relazioni di operandi originali. 5. Operazioni di unione interna A prima vista, può sembrare strano considerare l'operazione di inner join prima dell'operazione di join naturale, perché quando abbiamo eseguito le operazioni binarie, tutto era il contrario. Ma analizzando l'espressione delle operazioni nel linguaggio di query strutturato, si può giungere alla conclusione che l'operazione di join naturale è un caso speciale dell'operazione di inner join. Ecco perché è razionale considerare queste operazioni in quest'ordine. Quindi, per prima cosa, ricordiamo la definizione dell'operazione di inner join che abbiamo esaminato in precedenza: r1(S1) X P r2(S2) = σ (r1 xr2), S1 ∩ S2 =∅. Per noi, in questa definizione, è particolarmente importante che gli schemi considerati di relazioni-operandi S1 e S2 non deve intersecare. Per implementare l'operazione di inner join nel linguaggio di query strutturato, è disponibile un'opzione speciale join interno, che è letteralmente tradotto dall'inglese come "inner join" o "inner join". L'istruzione Select nel caso di un'operazione di inner join sarà simile a questa: Seleziona * Da R1 join interno R2; Qui, come prima, R1 e R2 - nomi delle relazioni iniziali-operandi. Nell'attuazione di questa operazione, gli schemi degli operandi di relazione non devono potersi incrociare. 6. Operazione di unione naturale Come abbiamo già detto, l'operazione di join naturale è un caso speciale dell'operazione di inner join. Come mai? Sì, perché durante l'azione di un join naturale, le tuple delle relazioni originali dell'operando vengono unite secondo una condizione speciale. Vale a dire, dalla condizione di uguaglianza delle tuple all'intersezione di relazioni-operandi, mentre con l'azione dell'operazione di inner join, una tale situazione non potrebbe essere consentita. Poiché l'operazione di unione naturale che stiamo considerando è un caso speciale dell'operazione di unione interna, per implementarla viene utilizzata la stessa opzione dell'operazione considerata in precedenza, ovvero l'opzione join interno. Ma poiché, quando si compila l'operatore Select per l'operazione di unione naturale, è anche necessario tenere conto della condizione di uguaglianza delle tuple delle relazioni-operandi iniziali all'intersezione dei loro schemi, quindi oltre all'opzione indicata, la parola chiave viene applicata on. Tradotto dall'inglese, significa letteralmente "su", e in relazione al nostro significato, può essere tradotto come "soggetto a". La forma generale dell'istruzione Select per eseguire un'operazione di unione naturale è la seguente: Seleziona * Da nome della relazione 1 join interno nome della relazione 2 on condizione di uguaglianza di tupla; Si consideri un esempio. Siano date due relazioni: R1 (A, B, C), R2 (Si, Do, Re); L'operazione di join naturale di queste relazioni può essere implementata utilizzando il seguente operatore: Seleziona A, R1.B, R1.CD Da R1 join interno R2 on R1.B=R2.B e R1.C=R2.C Come risultato di questa operazione, nel risultato verranno visualizzati gli attributi specificati nella prima riga dell'operatore Seleziona, corrispondenti a tuple uguali all'intersezione specificata. Va notato che qui ci riferiamo agli attributi comuni B e C, non solo al nome. Questo deve essere fatto non per la stessa ragione come nel caso di attuazione dell'operazione di prodotto cartesiano, ma perché altrimenti non sarà chiaro a quale relazione si riferiscono. È interessante notare che la formulazione utilizzata della condizione di unione (R1.B=R2.B e R1.C=R2.C) presuppone che gli attributi condivisi delle relazioni Null-value unite non siano consentiti. Questo è integrato nel sistema Structured Query Language sin dall'inizio. 7. Operazione di join esterno sinistro L'espressione del linguaggio di query strutturato SQL dell'operazione di join esterno sinistro è ottenuta dall'implementazione dell'operazione di join naturale sostituendo la parola chiave interno per parola chiave esterno sinistro. Pertanto, nel linguaggio delle query strutturate, questa operazione sarà scritta come segue: Seleziona * Da nome della relazione 1 left outer join nome della relazione 2 on condizione di uguaglianza di tupla; 8. Operazione di join esterno destro L'espressione per un'operazione di join esterno destro nel linguaggio di query strutturato è ottenuta dall'esecuzione di un'operazione di join naturale sostituendo la parola chiave interno per parola chiave esterno destro. Quindi, otteniamo che nel linguaggio di query strutturato SQL, l'operazione del join esterno destro sarà scritta come segue: Seleziona * Da nome della relazione 1 join esterno destro nome della relazione 2 on condizione di uguaglianza di tupla; 9. Operazione di join esterno completo L'espressione Structured Query Language per un'operazione di full outer join si ottiene, come nei due casi precedenti, dall'espressione per un'operazione di natural join sostituendo la parola chiave interno per parola chiave esterno completo. Pertanto, nel linguaggio delle query strutturate, questa operazione sarà scritta come segue: Seleziona * Da nome della relazione 1 unione esterna completa nome della relazione 2 on condizione di uguaglianza di tupla; È molto conveniente che queste opzioni siano integrate nella semantica del linguaggio di query strutturato SQL, perché altrimenti ogni programmatore dovrebbe emetterle in modo indipendente e inserirle in ogni nuovo database. 4. Utilizzo di sottoquery Come si può capire dal materiale trattato, il concetto di "subquery" nel linguaggio di query strutturato è un concetto di base ed è abbastanza ampiamente applicabile (a volte, tra l'altro, vengono anche chiamate query SQL. Infatti, la pratica della programmazione e lavorare con i database mostra che la compilazione di un sistema di sottoquery per la risoluzione di vari compiti correlati - un'attività che è molto più gratificante rispetto ad altri metodi di lavoro con informazioni strutturate. Consideriamo quindi un esempio per comprendere meglio le azioni con le sottoquery, la loro compilazione e usa. Lascia che ci sia il seguente frammento di un determinato database, che può essere utilizzato in qualsiasi istituto di istruzione: Elementi (Codice articolo, Nome dell'oggetto); Studenti (numero di registro, Nome e cognome); Sessione (Codice oggetto, numero del registro dei voti, Grado); Formuliamo una query SQL che restituisca un'istruzione indicante il numero del libro dei voti dello studente, il cognome e le iniziali, e il voto per la materia denominata "Banche dati". Le università hanno bisogno di ricevere tali informazioni sempre e in modo tempestivo, quindi la seguente query è forse l'unità di programmazione più popolare che utilizza tali database. Per comodità, supponiamo inoltre che gli attributi "Cognome", "Nome" e "Patronimico" non consentano valori Null e non siano vuoti. Questo requisito è abbastanza comprensibile e logico, perché il primo dei dati per un nuovo studente che viene inserito nel database di qualsiasi istituto di istruzione sono i dati sul suo cognome, nome e patronimico. E va da sé che in un database del genere non può esserci una voce che contenga dati su uno studente, ma allo stesso tempo il suo nome è sconosciuto. Si noti che l'attributo "Nome oggetto" dello schema di relazione "Articoli" è una chiave, quindi come segue dalla definizione (ne parleremo più avanti), tutti i nomi degli elementi sono univoci. Questo è comprensibile anche senza spiegare la rappresentazione della chiave, perché tutte le materie insegnate in un istituto di istruzione devono avere e avere nomi diversi. Ora, prima di iniziare a compilare il testo dell'operatore stesso, introdurremo due funzioni che ci saranno utili man mano che procediamo. Innanzitutto, avremo bisogno della funzione Trim, è scritto Trim ("stringa"), ovvero l'argomento di questa funzione è una stringa. Cosa fa questa funzione? Restituiscono l'argomento stesso senza spazi all'inizio e alla fine di questa riga, ovvero questa funzione viene utilizzata, ad esempio, nei casi: Trim ("Bogucharnikov") o Trim ("Maksimenko"), quando dopo o prima gli argomenti sono vale qualche spazio in più. E in secondo luogo, è necessario considerare anche la funzione Left, che si scrive Left (stringa, numero), cioè una funzione di già due argomenti, uno dei quali è, come prima, una stringa. Il suo secondo argomento è un numero, indica quanti caratteri dal lato sinistro della stringa devono essere emessi nel risultato. Ad esempio, il risultato dell'operazione: Sinistra ("Mikhail, 1") + "." + Sinistra ("Zinovievich, 1") saranno le iniziali "M. Z." È per visualizzare le iniziali degli studenti che utilizzeremo questa funzione nella nostra query. Quindi, iniziamo a compilare la query desiderata. Per prima cosa, facciamo una piccola query ausiliaria, che poi usiamo nella query principale principale: Seleziona Numero di registro, Grado Da Sessione Dove Codice articolo = (Seleziona Codice articolo Da oggetti Dove Nome elemento = "Banche dati") as Banche dati "Stime" "; L'utilizzo dell'opzione as qui significa che abbiamo alias questa query "Stime database". Lo abbiamo fatto per comodità di lavorare ulteriormente con questa richiesta. Successivamente, in questa query, una sottoquery: Seleziona Codice articolo Da oggetti Dove Nome elemento = "Banche dati"; permette di selezionare dalla relazione "Sessione" quelle tuple che riguardano l'argomento in esame, ovvero le banche dati. È interessante notare che questa sottoquery interna può restituire solo un valore, poiché l'attributo "Nome oggetto" è la chiave della relazione "Elementi", ovvero tutti i suoi valori sono univoci. E l'intera query "Database Punteggi" consente di selezionare dalla relazione "Sessione" i dati relativi a quegli studenti (numeri e voti del registro dei voti) che soddisfano la condizione specificata nella sottoquery, ovvero informazioni sulla materia denominata "Database". Ora faremo la richiesta principale, utilizzando i risultati già ricevuti. Seleziona Studenti. numero di registro, Trim (Cognome) + " " + sinistra (Nome, 1) + "." + sinistra (Patronimico, 1) + "."as Nome completo, stime "Banche dati". Grado Da studenti join interno ( Seleziona Numero di registro, Grado Da Sessione Dove Codice articolo = (Seleziona Codice articolo Da oggetti Dove Nome elemento = "Banche dati") ) come Banche dati "Stime"". on Studenti. Registro dei voti # = voti "Database". Registra il numero del libro. Quindi, per prima cosa elenchiamo gli attributi che dovranno essere visualizzati dopo il completamento della query. Va detto che l'attributo "Numero registro" è dalla relazione Studenti, da lì - gli attributi "Cognome", "Nome" e "Patronimico". È vero, gli ultimi due attributi non sono completamente dedotti, ma solo le prime lettere. Citiamo anche l'attributo "Punteggio" dalla query "Punteggio database" che abbiamo inserito in precedenza. Selezioniamo tutti questi attributi dall'inner join della relazione "Studenti" e dalla query "Voti database". Questa unione interiore, come possiamo vedere, è da noi presa a condizione di uguaglianza dei numeri del registro. Come risultato di questa operazione di inner join, i voti vengono aggiunti alla relazione Studenti. Si noti che poiché gli attributi "Cognome", "Nome" e "Patronimico" per condizione non consentono valori Null e non sono vuoti, la formula di calcolo che restituisce l'attributo "Nome" (Trim (Cognome) + " " + sinistra (Nome, 1) + "." + sinistra (Patronimico, 1) + "."as Il nome completo), rispettivamente, non richiede ulteriori controlli, è semplificato. Lezione numero 7. Relazioni di base Come già sappiamo, i database sono come una sorta di contenitore, il cui scopo principale è archiviare i dati presentati sotto forma di relazioni. Devi sapere che, a seconda della loro natura e struttura, le relazioni si dividono in: 1) relazioni di base; 2) relazioni virtuali. Le relazioni della vista di base contengono solo dati indipendenti e non possono essere espresse in termini di altre relazioni di database. Nei sistemi di gestione di database commerciali, le relazioni di base sono generalmente indicate semplicemente come tavoli in contrasto con le rappresentazioni corrispondenti al concetto di relazioni virtuali. In questo corso considereremo in dettaglio solo le relazioni di base, le tecniche principali e i principi per lavorare con esse. 1. Tipi di dati di base I tipi di dati, come le relazioni, sono divisi in di base и virtuale. (Parleremo dei tipi di dati virtuali un po' più avanti; dedicheremo un capitolo separato a questo argomento.) Tipi di dati di base - si tratta di tutti i tipi di dati inizialmente definiti nei sistemi di gestione dei database, ovvero presenti lì per impostazione predefinita (al contrario di un tipo di dati definito dall'utente, che analizzeremo immediatamente dopo aver attraversato il tipo di dati di base). Prima di procedere alla considerazione degli effettivi tipi di dati di base, elenchiamo quali tipi di dati esistono in generale: 1) dati numerici; 2) dati logici; 3) dati di stringa; 4) dati che definiscono la data e l'ora; 5) dati identificativi. Per impostazione predefinita, i sistemi di gestione dei database hanno introdotto molti dei tipi di dati più comuni, ognuno dei quali appartiene a uno dei tipi di dati elencati. Chiamiamoli. 1. In numerico tipo di dati si distingue: 1) Intero. Questa parola chiave di solito denota un tipo di dati intero; 2) Real, corrispondente al tipo di dato reale; 3) Decimale(n, m). Questo è un tipo di dati decimale. Inoltre, nella notazione n è un numero che fissa il numero totale di cifre del numero, e m mostra quanti caratteri ci sono dopo il punto decimale; 4) Money or Currency, introdotto appositamente per una comoda rappresentazione dei dati del tipo di dati monetari. 2. In logico il tipo di dati di solito alloca un solo tipo di base, questo è Logico. 3. Corda il tipo di dati ha quattro tipi fondamentali (intendendo, ovviamente, i più comuni): 1) Bit(n). Si tratta di stringhe di bit con lunghezza fissa n; 2) Varbit(n). Anche queste sono stringhe di bit, ma di lunghezza variabile non superiore a n bit; 3) Char(n). Si tratta di stringhe di caratteri con lunghezza costante n; 4) Varcar(n). Si tratta di stringhe di caratteri, di lunghezza variabile non superiore a n caratteri. 4. Digitare data e ora include i seguenti tipi di dati di base: 1) Data - tipo di dati data; 2) Ora - tipo di dato che esprime l'ora del giorno; 3) La data e l'ora è un tipo di dati che esprime sia la data che l'ora. 5. identificazione Il tipo di dati contiene solo un tipo incluso per impostazione predefinita nel sistema di gestione del database, ovvero GUID (Globally Unique Identifier). Va notato che tutti i tipi di dati di base possono avere varianti di diversi intervalli di rappresentazione dei dati. Per fare un esempio, le varianti del tipo di dati intero a quattro byte possono essere tipi di dati a otto byte (bigint) ea due byte (smallint). Parliamo separatamente del tipo di dati GUID di base. Questo tipo ha lo scopo di memorizzare valori di sedici byte del cosiddetto identificatore univoco globale. Tutti i diversi valori di questo identificatore vengono generati automaticamente quando viene chiamata una speciale funzione incorporata NewId(). Questa designazione deriva dalla frase inglese completa New Identification, che letteralmente significa "nuovo valore identificatore". Ogni valore identificatore generato su un determinato computer è univoco all'interno di tutti i computer prodotti. L'identificatore GUID viene utilizzato, in particolare, per organizzare la replica del database, ovvero quando si creano copie di alcuni database esistenti. Tali GUID possono essere utilizzati dagli sviluppatori di database insieme ad altri tipi di base. Una posizione intermedia tra il tipo GUID e altri tipi di base è occupata da un altro tipo di base speciale: il tipo contatore. Una parola chiave speciale viene utilizzata per designare dati di questo tipo. Contatore(x0, ∆x), che letteralmente si traduce dall'inglese e significa "contatore". Parametro x0 imposta il valore iniziale, e Δx - passo di incremento. I valori di questo tipo Contatore sono necessariamente numeri interi. Va notato che lavorare con questo tipo di dati di base include una serie di funzionalità molto interessanti. Ad esempio, i valori di questo tipo di contatore non sono impostati, come siamo abituati quando lavoriamo con tutti gli altri tipi di dati, vengono generati su richiesta, proprio come per i valori del tipo di identificatore univoco globale. È anche insolito che il tipo di contatore possa essere specificato solo durante la definizione della tabella, e solo allora! Questo tipo non può essere utilizzato nel codice. È inoltre necessario ricordare che quando si definisce una tabella, il tipo di contatore può essere specificato solo per una colonna. I valori dei dati del contatore vengono generati automaticamente quando vengono inserite le righe. Inoltre, questa generazione viene eseguita senza ripetizione, in modo che il contatore identifichi sempre in modo univoco ogni riga. Ma questo crea qualche inconveniente quando si lavora con tabelle contenenti dati contatore. Se, ad esempio, i dati nella relazione data dalla tabella cambiano e devono essere cancellati o scambiati, i valori dei contatori possono facilmente "confondere le carte", soprattutto se sta lavorando un programmatore inesperto. Facciamo un esempio per illustrare una situazione del genere. Sia data la seguente tabella che rappresenta una relazione, in cui sono inserite quattro righe:
Il contatore assegnava automaticamente a ogni nuova riga un nome univoco. E ora rimuoviamo la seconda e la quarta riga dalla tabella, quindi aggiungiamo una riga aggiuntiva. Queste operazioni comporteranno la seguente trasformazione della tabella di origine:
Pertanto, il contatore ha rimosso la seconda e la quarta riga insieme ai loro nomi univoci e non le ha "riassegnate" a nuove righe, come ci si potrebbe aspettare. Inoltre, il sistema di gestione del database non consentirà mai di modificare manualmente il valore del contatore, così come non consentirà di dichiarare più contatori in una tabella contemporaneamente. Tipicamente, il contatore viene utilizzato come surrogato, cioè una chiave artificiale nella tabella. È interessante sapere che i valori univoci di un contatore a quattro byte a una velocità di generazione di un valore al secondo dureranno più di 100 anni. Mostriamo come viene calcolato: 1 anno = 365 giorni * 24 h * 60 s * 60 s < 366 giorni * 24 h * 60 s * 60 s < 225 con. 1 secondo > 2 all'25 ottobre anno. 24*8 valori / 1 valore/secondo = 232 c > 27 anno > 100 anni. 2. Tipo di dati personalizzato Un tipo di dati personalizzato differisce da tutti i tipi di base in quanto non è stato originariamente integrato nel sistema di gestione del database, non è stato dichiarato come tipo di dati predefinito. Questo tipo può essere creato da qualsiasi utente e programmatore di database in base alle proprie richieste e requisiti. Pertanto, un tipo di dati definito dall'utente è un sottotipo di un tipo di base, ovvero è un tipo di base con alcune restrizioni sull'insieme di valori consentiti. Nella notazione pseudo-codice, viene creato un tipo di dati personalizzato utilizzando la seguente istruzione standard: Crea sottotipo nome del sottotipo Tipologia nome del tipo di base As vincolo di sottotipo; Quindi, nella prima riga, dobbiamo specificare il nome del nostro nuovo tipo di dati definito dall'utente, nella seconda - quale dei tipi di dati di base esistenti abbiamo preso come modello, creando il nostro e, infine, nella terza - quelle restrizioni che dobbiamo aggiungere a quelle esistenti restrizioni sull'insieme dei valori del tipo di dati di base - campione. I vincoli del sottotipo vengono scritti come una condizione che dipende dal nome del sottotipo definito. Per comprendere meglio come funziona l'istruzione Create, considera l'esempio seguente. Supponiamo di dover creare il nostro tipo di dati specializzato, ad esempio, per lavorare nella posta. Questo sarà il tipo per lavorare con dati come i numeri di codice postale. I nostri numeri differiranno dai normali numeri decimali a sei cifre in quanto possono essere solo positivi. Scriviamo un operatore per creare il sottotipo di cui abbiamo bisogno: Crea sottotipo CAP Tipologia decimale(6, 0) As Codice postale > 0. Perché abbiamo scelto decimal(6, 0)? Richiamando la forma usuale dell'indice, vediamo che tali numeri devono essere costituiti da sei interi da zero a nove. Ecco perché abbiamo preso il tipo decimale come tipo di dati di base. È curioso notare che, in generale, la condizione imposta al tipo di dati di base, ovvero il vincolo di sottotipo, può contenere i connettivi logici non, e, o, e in generale, essere espressione di qualsiasi complessità arbitraria. I sottotipi di dati personalizzati definiti in questo modo possono essere utilizzati liberamente insieme ad altri tipi di dati di base sia nel codice del programma che durante la definizione dei tipi di dati nelle colonne della tabella, ovvero i tipi di dati di base e i tipi di dati utente sono completamente uguali quando si lavora con essi. Nell'ambiente di sviluppo visivo, vengono visualizzati in elenchi di tipi validi insieme ad altri tipi di dati di base. La probabilità che potremmo aver bisogno di un tipo di dati non documentato (definito dall'utente) durante la progettazione di un nostro nuovo database è piuttosto alta. Di default, infatti, nel sistema di gestione del database vengono cuciti solo i tipi di dati più comuni, adatti, rispettivamente, a risolvere i compiti più comuni. Quando si compilano database di soggetti, è quasi impossibile fare a meno di progettare i propri tipi di dati. Ma, curiosamente, con uguale probabilità, potremmo aver bisogno di rimuovere il sottotipo che abbiamo creato, in modo da non ingombrare e complicare il codice. Per fare ciò, i sistemi di gestione dei database di solito hanno un operatore speciale integrato. cadere, che significa "rimuovere". La forma generale di questo operatore per rimuovere i tipi personalizzati non necessari è la seguente: Sottotipo di drop il nome del tipo personalizzato; I tipi di dati personalizzati sono generalmente consigliati per i sottotipi sufficientemente generali. 3. Valori predefiniti I sistemi di gestione del database possono avere la capacità di creare valori predefiniti arbitrari o, come vengono anche chiamati, valori predefiniti. Questa operazione in qualsiasi ambiente di programmazione ha un peso abbastanza grande, perché in quasi tutte le attività potrebbe essere necessario introdurre costanti, valori predefiniti immutabili. Per creare un default nei sistemi di gestione dei database, viene utilizzata la funzione a noi già familiare dal passaggio di un tipo di dati definito dall'utente Creare. Solo nel caso di creazione di un valore predefinito, viene utilizzata anche una parola chiave aggiuntiva difetto, che significa "predefinito". In altre parole, per creare un valore predefinito in un database esistente, è necessario utilizzare la seguente istruzione: Crea predefinito nome predefinito As espressione costante; È chiaro che al posto di un valore costante quando si applica questo operatore, è necessario scrivere il valore o l'espressione che vogliamo rendere il valore o l'espressione di default. E, naturalmente, dobbiamo decidere con quale nome sarà conveniente per noi usarlo nel nostro database e scrivere questo nome nella prima riga dell'operatore. Si noti che in questo caso particolare, questa istruzione Create segue la sintassi Transact-SQL incorporata nel sistema Microsoft SQL Server. Allora cosa abbiamo? Abbiamo dedotto che il valore predefinito è una costante denominata memorizzata nei database, proprio come il suo oggetto. Nell'ambiente di sviluppo visivo, le impostazioni predefinite vengono visualizzate nell'elenco delle impostazioni predefinite evidenziate. Ecco un esempio di creazione di un'impostazione predefinita. Supponiamo che per il corretto funzionamento del nostro database sia necessario che in esso funzioni un valore con il significato di una vita illimitata di qualcosa. Quindi è necessario inserire nell'elenco dei valori di questo database il valore predefinito che soddisfa questo requisito. Questo potrebbe essere necessario, se non altro perché ogni volta che incontri questa espressione piuttosto ingombrante nel testo del codice, sarà estremamente scomodo scriverla di nuovo. Questo è il motivo per cui useremo l'istruzione Create sopra per creare un valore predefinito, con il significato di una durata illimitata di qualcosa. Crea predefinito "nessun limite di tempo" As ‘9999-12-31 23: 59:59’ Qui è stata utilizzata anche la sintassi Transact-SQL, secondo la quale i valori delle costanti di data e ora (in questo caso, '9999-12-31 23:59:59') vengono scritti come stringhe di caratteri di una certa direzione. L'interpretazione delle stringhe di caratteri come valori datetime è determinata dal contesto in cui vengono utilizzate le stringhe. Ad esempio, nel nostro caso particolare, nella riga costante viene scritto prima il valore limite dell'anno, quindi l'ora. Tuttavia, nonostante tutta la loro utilità, le impostazioni predefinite, come un tipo di dati definito dall'utente, a volte possono anche richiedere la loro rimozione. I sistemi di gestione del database di solito hanno uno speciale predicato integrato, simile a un operatore che rimuove un tipo di dati più definito dall'utente che non è più necessario. Questo è un predicato Cadere e l'operatore stesso si presenta così: Elimina predefinito nome predefinito; 4. Attributi virtuali Tutti gli attributi nei sistemi di gestione dei database sono divisi (per assoluta analogia con le relazioni) in di base e virtuali. Così chiamato attributi di base sono attributi memorizzati che devono essere utilizzati più di una volta, pertanto è consigliabile salvarli. E, a sua volta, attributi virtuali non vengono memorizzati, ma attributi calcolati. Cosa significa? Ciò significa che i valori dei cosiddetti attributi virtuali non vengono effettivamente memorizzati, ma vengono calcolati al volo tramite gli attributi di base tramite formule date. In questo caso, i domini degli attributi virtuali calcolati vengono determinati automaticamente. Diamo un esempio di una tabella che definisce una relazione, in cui due attributi sono ordinari, di base e il terzo attributo è virtuale. Sarà calcolato secondo una formula appositamente inserita.
Quindi, vediamo che gli attributi "Peso Kg" e "Prezzo Rub per Kg" sono attributi di base, perché hanno valori ordinari e sono memorizzati nel nostro database. Ma l'attributo "Costo" è un attributo virtuale, perché è impostato dalla formula del suo calcolo e non verrà effettivamente memorizzato nel database. È interessante notare che, per loro natura, gli attributi virtuali non possono assumere valori predefiniti e, in generale, il concetto stesso di valore predefinito per un attributo virtuale è privo di significato e quindi non applicabile. E devi anche essere consapevole del fatto che, sebbene i domini degli attributi virtuali siano determinati automaticamente, il tipo di valori calcolati a volte deve essere modificato da quello esistente a un altro. Per fare ciò, il linguaggio dei sistemi di gestione dei database dispone di uno speciale predicato Convert, con l'aiuto del quale è possibile ridefinire il tipo dell'espressione calcolata. Convert è la cosiddetta funzione di conversione di tipo esplicito. È scritto come segue: convertire (tipo di dati, espressione); L'espressione che è il secondo argomento della funzione Converti verrà calcolata e restituita come tale dato, il cui tipo è indicato dal primo argomento della funzione. Considera un esempio. Supponiamo di dover calcolare il valore dell'espressione "2 * 2", ma dobbiamo emetterlo non come un intero "4", ma come una stringa di caratteri. Per eseguire questo compito, scriviamo la seguente funzione di conversione: convertire (Cart(1), 2 * 2). Quindi, possiamo vedere che questa notazione della funzione Converti darà esattamente il risultato di cui abbiamo bisogno. 5. Il concetto di chiavi Quando si dichiara lo schema di una relazione di base, è possibile fornire dichiarazioni di più chiavi. L'abbiamo già incontrato molte volte. Infine, è il momento di parlare più in dettaglio di quali sono le chiavi di relazione, e non limitarsi a frasi generali e definizioni approssimative. Quindi, diamo una definizione rigorosa di una chiave di relazione. Chiave dello schema di relazione è un sottoschema dello schema originale, costituito da uno o più attributi per i quali è dichiarato condizione di unicità valori nelle tuple di relazione. Per capire qual è la condizione di unicità, o, come viene anche chiamata, vincolo unico, iniziamo con la definizione di una tupla e l'operazione unaria di proiettare una tupla su un sottocircuito. Portiamoli: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - definizione di una tupla, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S è la definizione dell'operazione di proiezione unaria; È chiaro che la proiezione della tupla sul sottoschema corrisponde ad una sottostringa della riga della tabella. Quindi, qual è esattamente un vincolo di unicità di un attributo chiave? La dichiarazione della chiave K per lo schema della relazione S porta alla formulazione della seguente condizione invariante, chiamata, come abbiamo già detto, vincolo di unicità e indicato come: Inv < K → S > r(S): Inv < K → S > r(S) = ∀t1, T2 ∈ r(t 1[K]=t2 [K] → t 1(S) = t2(S)), K ⊆ S; Quindi, questo vincolo di unicità Inv < K → S > r(S) della chiave K significa che se due tuple t1 e t2, appartenenti alla relazione r(S), sono uguali nella proiezione sulla chiave K, quindi ciò comporta necessariamente l'uguaglianza di queste due tuple e nella proiezione sull'intero schema della relazione S. In altre parole, tutti i valori delle tuple appartenenti agli attributi chiave sono uniche, uniche nella loro relazione. E il secondo requisito importante per una chiave di relazione è requisito di ridondanza. Cosa significa? Questo requisito significa che nessun sottoinsieme rigoroso della chiave deve essere univoco. A livello intuitivo, è chiaro che l'attributo chiave è quell'attributo di relazione che identifica in modo univoco e preciso ogni tupla della relazione. Ad esempio, nella seguente relazione data da una tabella:
L'attributo chiave è l'attributo "Gradebook #", perché studenti diversi non possono avere lo stesso numero di registro, ovvero questo attributo è soggetto a un vincolo univoco. È interessante notare che nello schema di qualsiasi relazione può verificarsi una varietà di chiavi. Elenchiamo i principali tipi di chiavi: 1) chiave semplice è una chiave composta da uno e non più attributi. Ad esempio, in un foglio d'esame per una determinata materia, una semplice chiave è il numero della carta di credito, perché può identificare in modo univoco qualsiasi studente; 2) chiave composita è una chiave composta da due o più attributi. Ad esempio, una chiave composta nell'elenco delle classi è il numero dell'edificio e il numero della classe. Dopotutto, non è possibile identificare in modo univoco ogni audience con uno di questi attributi, ed è abbastanza facile farlo con la loro totalità, cioè con una chiave composita; 3) super chiave è un superset di qualsiasi chiave. Pertanto, lo schema della relazione stessa è certamente una superchiave. Da ciò possiamo concludere che ogni relazione ha teoricamente almeno una chiave e può averne diverse. Tuttavia, dichiarare una superchiave al posto di una chiave normale è logicamente illegale, poiché implica l'allentamento del vincolo di unicità imposto automaticamente. In fondo la super chiave, pur avendo la proprietà di unicità, non ha la proprietà di non ridondanza; 4) chiave primaria è semplicemente la chiave che è stata dichiarata per prima quando è stata definita la relazione di base. È importante che venga dichiarata una e una sola chiave primaria. Inoltre, gli attributi della chiave primaria non possono mai assumere valori null. Quando si crea una relazione di base in una voce di pseudocodice, viene indicata la chiave primaria chiave primaria e tra parentesi c'è il nome dell'attributo, che è questa chiave; 5) chiavi candidate sono tutte le altre chiavi dichiarate dopo la chiave primaria. Quali sono le principali differenze tra le chiavi candidate e le chiavi primarie? Innanzitutto, possono esserci diverse chiavi candidate, mentre la chiave primaria, come accennato in precedenza, può essere solo una. E, in secondo luogo, se gli attributi della chiave primaria non possono assumere valori Null, questa condizione non viene imposta agli attributi delle chiavi candidate. Nello pseudocodice, quando si definisce una relazione di base, le chiavi candidate vengono dichiarate utilizzando le parole chiave candidata e poi tra parentesi, come nel caso della dichiarazione di una chiave primaria, viene indicato il nome dell'attributo, che è la chiave candidata data; 6) chiave esterna è una chiave dichiarata in una relazione di base che si riferisce anche a una chiave primaria o candidata della stessa o di qualche altra relazione di base. In questo caso, la relazione a cui si riferisce la chiave esterna è chiamata riferimento (o genitore) atteggiamento. Viene chiamata una relazione contenente una chiave esterna bambino. In pseudocodice, la chiave esterna è indicata come chiave esterna, tra parentesi subito dopo queste parole, viene indicato il nome dell'attributo di questa relazione, che è una chiave esterna, e successivamente viene scritta la parola chiave Riferimenti ("riferito a") e specificare il nome della relazione di base e il nome dell'attributo a cui fa riferimento questa particolare chiave esterna. Inoltre, quando si crea una relazione di base, per ogni chiave esterna viene scritta una condizione, chiamata vincolo di integrità referenziale, ma di questo parleremo in dettaglio più avanti. Lezione #8 L'argomento di questa lezione sarà una discussione abbastanza dettagliata dell'operatore di creazione di relazioni di base. Analizzeremo l'operatore stesso in un record di pseudo-codice, analizzeremo tutti i suoi componenti e il loro lavoro e analizzeremo i metodi di modifica, ovvero cambiando le relazioni di base. 1. Simboli metalinguistici Quando si descrivono le costruzioni sintattiche utilizzate nella scrittura dell'operatore di creazione della relazione di base in pseudocodice, vengono utilizzati vari metodi. simboli metalinguistici. Questi sono tutti i tipi di parentesi di apertura e chiusura, varie combinazioni di punti e virgole, in una parola, simboli che portano ciascuno il proprio significato e rendono più facile per il programmatore scrivere codice. Introduciamo e spieghiamo il significato dei principali simboli metalinguistici che sono più spesso utilizzati nella progettazione delle relazioni di base. Così: 1) carattere metalinguistico "{}". I costrutti sintattici tra parentesi graffe lo sono obbligatorio unità sintattiche. Quando si definisce una relazione di base, gli elementi richiesti sono, ad esempio, attributi di base; senza dichiarare gli attributi di base, non è possibile progettare alcuna relazione. Pertanto, quando si scrive l'operatore di creazione della relazione di base in pseudocodice, gli attributi di base sono elencati tra parentesi graffe; 2) il simbolo metalinguistico "[]". In questo caso è vero il contrario: i costrutti di sintassi tra parentesi quadre rappresentano opzionale elementi di sintassi. Le unità sintattiche facoltative nell'operatore di creazione della relazione di base, a loro volta, sono gli attributi virtuali delle chiavi primaria, candidata ed esterna. Qui, ovviamente, ci sono anche delle sottigliezze, ma ne parleremo più avanti, quando si procederà direttamente alla progettazione dell'operatore per la creazione della relazione di base; 3) simbolo metalinguistico "|". Questo simbolo significa letteralmente "o", come l'analogo simbolo in matematica. L'uso di questo simbolo metalinguistico significa che si deve scegliere tra due o più costruzioni separate, rispettivamente, da questo simbolo; 4) simbolo metalinguistico "...". I puntini di sospensione posti immediatamente dopo qualsiasi unità sintattica indicano la possibilità ripetizioni questi elementi sintattici che precedono il simbolo metalinguistico; 5) simbolo metalinguistico ",..". Questo simbolo significa quasi lo stesso del precedente. Solo quando si utilizza il simbolo metalinguistico ",..", ripetizione si verificano costruzioni sintattiche separati da virgoleche spesso è molto più conveniente. Con questo in mente, possiamo parlare dell'equivalenza delle seguenti due costruzioni sintattiche: unità [, unità]... и unità,.. ; 2. Un esempio di creazione di una relazione di base in una voce di pseudocodice Ora che abbiamo chiarito i significati dei principali simboli metalinguistici utilizzati nella scrittura dell'operatore di creazione della relazione di base in pseudocodice, si può procedere alla considerazione vera e propria di tale operatore stesso. Come si evince dai riferimenti precedenti, l'operatore per la creazione di una relazione di base nella voce di pseudocodice include dichiarazioni di attributi di base e virtuali, chiavi primarie, candidate ed esterne. Inoltre, come verrà mostrato e spiegato in precedenza, questo operatore copre anche i vincoli di valore di attributo e di tupla, nonché i cosiddetti vincoli di integrità referenziale. I primi due vincoli, vale a dire il vincolo del valore dell'attributo e il vincolo della tupla, sono dichiarati dopo la parola riservata speciale dai un'occhiata. I vincoli di integrità referenziale possono essere di due tipi: in aggiornamento, che significa "durante l'aggiornamento", e in cancellazione, che significa "in caso di eliminazione". Cosa significa? Ciò significa che durante l'aggiornamento o l'eliminazione degli attributi delle relazioni a cui fa riferimento una chiave esterna, è necessario mantenere l'integrità dello stato. (Ne parleremo più avanti.) Lo stesso operatore di creazione della relazione di base viene utilizzato da noi già studiato: l'operatore Creare, solo per creare una relazione di base, viene aggiunta la parola chiave tavolo ("atteggiamento"). E, naturalmente, poiché la relazione stessa è più ampia e include tutti i costrutti discussi in precedenza, nonché nuovi costrutti aggiuntivi, l'operatore create sarà piuttosto impressionante. Quindi, scriviamo in pseudocodice la forma generale dell'operatore utilizzato per creare le relazioni di base: Crea una tabella nome della relazione di base { nome dell'attributo di base tipo di valore dell'attributo di base dai un'occhiata (limite valore attributo) {Nulla | non nullo} difetto (valore di default) },.. [nome attributo virtuale as (formula di calcolo) ],.. [,dai un'occhiata (vincolo tupla)] [,chiave primaria (nome attributo,..)] [,chiave candidata (nome attributo,..)]... [,chiave esterna (nome attributo,..) Riferimenti nome della relazione di riferimento (nome attributo,..) in aggiornamento { Limita | cascata | Imposta nullo} su elimina { Limita | cascata | Imposta nullo} ] ... Quindi, vediamo che possono essere dichiarati diversi attributi di base e virtuali, candidate e chiavi esterne, poiché dopo le corrispondenti costruzioni sintattiche c'è un simbolo metalinguistico ",.." Dopo la dichiarazione della chiave primaria, questo simbolo non è presente, perché le relazioni di base, come accennato in precedenza, consentono una sola chiave primaria. Successivamente, diamo un'occhiata più da vicino al meccanismo di dichiarazione. attributi di base. Quando si descrive qualsiasi attributo nell'operatore di creazione della relazione di base, nel caso generale, vengono specificati il nome, il tipo, le restrizioni sui suoi valori, il flag di validità dei valori Null e i valori predefiniti. È facile vedere che il tipo di un attributo e i suoi vincoli di valore determinano il suo dominio, cioè letteralmente l'insieme di valori validi per quel particolare attributo. Attributo Valore Limite viene scritto come una condizione dipendente dal nome dell'attributo. Ecco un piccolo esempio per rendere più facile la comprensione di questo materiale: Crea una tabella nome della relazione di base Corso numero intero dai un'occhiata (1 <= Corso e Corso <= 5; Qui, la condizione "1 <= Heading and Heading <= 5" insieme alla definizione di un tipo di dati intero condiziona davvero completamente l'insieme dei valori consentiti dell'attributo, cioè letteralmente il suo dominio. Il flag di indennità valori Null (Null | not Null) vieta (non Null) o, al contrario, consente (Null) la comparsa di valori Null tra i valori degli attributi. Prendendo l'esempio appena discusso, il meccanismo per applicare i flag di validità nulla è il seguente: Crea una tabella nome della relazione di base Corso numero intero dai un'occhiata (1 <= Corso e Corso <= 5); Non nullo; Quindi, il numero del corso di uno studente non può mai essere nullo, non può essere sconosciuto ai compilatori di database e non può non esistere. Valori predefiniti (difetto (valore predefinito)) vengono utilizzati quando si inserisce una tupla in una relazione se i valori degli attributi non sono impostati in modo esplicito nell'istruzione insert. È interessante notare che i valori predefiniti possono anche essere valori Null, purché i valori Null per quel particolare attributo siano dichiarati validi. Consideriamo ora la definizione attributo virtuale nell'operatore di creazione della relazione di base. Come abbiamo detto in precedenza, l'impostazione di un attributo virtuale consiste nell'impostazione di formule per il suo calcolo tramite altri attributi di base. Consideriamo un esempio di dichiarazione di un attributo virtuale "Cost Rub". sotto forma di formula che dipende dagli attributi di base "Peso Kg" e "Prezzo Rub. per Kg". Crea una tabella nome della relazione di base Peso (kg attributo base tipo valore Peso Kg dai un'occhiata (limitazione del valore dell'attributo Peso Kg) non nullo difetto (valore di default) Prezzo, strofinare. al kg tipo di valore dell'attributo di base Prezzo Rub. al kg dai un'occhiata (limitazione del valore dell'attributo Prezzo Rub. al Kg) non nullo difetto (valore di default) ... Costo, strofinare. as (Peso Kg. * Prezzo Rub. al Kg) Poco prima, abbiamo esaminato i vincoli di attributo, che sono stati scritti come condizioni dipendenti dai nomi di attributo. Consideriamo ora il secondo tipo di vincoli dichiarati durante la creazione di una relazione di base, vale a dire vincoli di tupla. Che cos'è un vincolo di tupla, in che modo è diverso da un vincolo di attributo? Un vincolo di tupla viene anche scritto come condizione dipendente dal nome dell'attributo di base, ma solo nel caso di un vincolo di tupla, la condizione può dipendere da più nomi di attributo contemporaneamente. Si consideri un esempio che illustra il meccanismo di lavoro con i vincoli di tupla: Crea una tabella nome della relazione di base Peso min Kg valore tipo di attributo base min Peso Kg dai un'occhiata (limitazione del valore dell'attributo min Peso Kg) non nullo difetto (valore di default) Peso max Kg valore tipo di attributo di base Peso max Kg dai un'occhiata (limitazione del valore dell'attributo Peso max Kg) non nullo difetto (valore di default) dai un'occhiata (0 < min Peso Kg ed Peso min Kg < Peso max Kg); Pertanto, applicare un vincolo a una tupla equivale a sostituire i valori della tupla con i nomi degli attributi. Passiamo a considerare l'operatore di creazione della relazione di base. Una volta dichiarati, gli attributi di base e virtuali possono essere dichiarati o meno. Tasti: primario, candidato ed esterno. Come abbiamo detto in precedenza, si chiama il sottoschema di una relazione di base che in un'altra (o la stessa) relazione di base corrisponde a una chiave primaria o candidata nel contesto della prima relazione chiave esterna. Le chiavi esterne rappresentano meccanismo di collegamento tuple di alcune relazioni su tuple di altre relazioni, cioè ci sono dichiarazioni di chiave esterna associate all'imposizione del già citato vincoli di integrità referenziale. (Questo vincolo sarà il fulcro della prossima lezione, poiché l'integrità dello stato (cioè l'integrità imposta dai vincoli di integrità) è fondamentale per il successo della relazione di base e dell'intero database.) La dichiarazione di chiavi primarie e candidate, a sua volta, impone i vincoli di unicità appropriati allo schema della relazione di base, di cui abbiamo discusso in precedenza. E, infine, va detto sulla possibilità di cancellare la relazione di base. Spesso nella pratica di progettazione di database, è necessario rimuovere una vecchia relazione non necessaria in modo da non ingombrare il codice del programma. Questo può essere fatto utilizzando l'operatore già familiare Cadere. Nella sua forma generale completa, l'operatore di eliminazione della relazione di base ha il seguente aspetto: tavola a caduta il nome della relazione di base; 3. Vincolo di integrità da parte dello stato Vincolo di integrità oggetto di dati relazionali come di è il cosiddetto data invariant. Allo stesso tempo, l'integrità dovrebbe essere distinta con sicurezza dalla sicurezza, che, a sua volta, implica la protezione dei dati dall'accesso non autorizzato agli stessi al fine di divulgare, modificare o distruggere i dati. In generale, vengono classificati i vincoli di integrità sugli oggetti di dati relazionali per livelli gerarchici questi stessi oggetti dati relazionali (la gerarchia degli oggetti dati relazionali è una sequenza di concetti annidati: "attributo - tupla - relazione - database"). Cosa significa questo? Ciò significa che i vincoli di integrità dipendono da: 1) a livello di attributo - dai valori di attributo; 2) a livello di tupla - dai valori della tupla, cioè dai valori di diversi attributi; 3) a livello di relazioni - da una relazione, cioè da più tuple; 4) a livello di database - da diverse relazioni. Quindi, ora ci resta solo da considerare più in dettaglio i vincoli di integrità sullo stato di ciascuno dei concetti di cui sopra. Ma prima, diamo i concetti di supporto procedurale e dichiarativo per i vincoli di integrità dello stato. Pertanto, il supporto per i vincoli di integrità può essere di due tipi: 1) procedurale, cioè creato scrivendo il codice del programma; 2) dichiarativo, ovvero creato dichiarando determinate restrizioni per ciascuno dei concetti nidificati sopra. Il supporto dichiarativo per i vincoli di integrità viene implementato nel contesto dell'istruzione Create per la creazione della relazione di base. Parliamo di questo in modo più dettagliato. Iniziamo a considerare l'insieme delle restrizioni dal fondo della nostra scala gerarchica di oggetti dati relazionali, cioè dal concetto di attributo. Vincolo a livello di attributo Esso comprende: 1) restrizioni sul tipo di valori degli attributi. Ad esempio, una condizione intera per i valori, ovvero una condizione intera per l'attributo "Corso" da una delle relazioni di base discusse in precedenza; 2) un vincolo del valore dell'attributo, scritto come condizione dipendente dal nome dell'attributo. Ad esempio, analizzando la stessa relazione di base del paragrafo precedente, vediamo che in quella relazione c'è anche un vincolo sui valori degli attributi utilizzando l'opzione dai un'occhiata, cioè.: dai un'occhiata (1 <= Corso e Corso <= 5); 3) Il vincolo a livello di attributo include i vincoli di valore Null definiti dal noto flag di validità (Null) o, al contrario, di inammissibilità (non Null) dei valori Null. Come accennato in precedenza, i primi due vincoli definiscono il vincolo di dominio dell'attributo, ovvero il valore del suo insieme di definizioni. Inoltre, secondo la scala gerarchica degli oggetti di dati relazionali, dobbiamo parlare di tuple. Così, vincolo di livello tupla si riduce a un vincolo di tupla ed è scritto come una condizione che dipende dai nomi di diversi attributi di base dello schema di relazione, ovvero questo vincolo di integrità dello stato è molto più piccolo e semplice di quello simile, corrispondente solo all'attributo. E ancora, sarebbe utile ricordare l'esempio della relazione di base che abbiamo esaminato in precedenza, che ha il vincolo di tupla di cui abbiamo bisogno ora, ovvero: dai un'occhiata (0 < min Peso Kg ed Peso min Kg < Peso max Kg); E, infine, l'ultimo concetto significativo nel contesto del vincolo di integrità dello Stato è il concetto di livello di relazione. Come abbiamo detto prima, vincolo a livello di relazione include la limitazione dei valori del primario (chiave primaria) e candidato (chiave candidata) chiavi. È curioso che le restrizioni imposte ai database non siano più vincoli di integrità dello stato, ma vincoli di integrità referenziale. 4. Vincoli di integrità referenziale Pertanto, il vincolo a livello di database include il vincolo di integrità referenziale della chiave esterna (chiave esterna). Ne abbiamo già accennato brevemente quando abbiamo parlato dei vincoli di integrità referenziale durante la creazione di una relazione di base e di chiavi esterne. Ora è il momento di parlare di questo concetto in modo più dettagliato. Come abbiamo detto prima, la chiave esterna della relazione di base dichiarata si riferisce alla chiave primaria o candidata di qualche altra relazione di base (il più delle volte). Ricordiamo che in questo caso viene chiamata la relazione a cui fa riferimento la chiave esterna riferimento o parentale, perché in un certo senso "genera" uno o più attributi nella relazione di base di riferimento. E, a sua volta, viene chiamata una relazione contenente una chiave esterna bambino, anche per ovvi motivi. Quale è vincolo di integrità referenziale? E consiste nel fatto che ogni valore della chiave esterna della relazione figlio deve necessariamente corrispondere al valore di una qualsiasi chiave della relazione genitore, a meno che il valore della chiave esterna non contenga valori Null in eventuali attributi. Vengono chiamate tuple di una relazione figlio che violano questa condizione impiccagione. Infatti, se la chiave esterna della relazione figlio si riferisce a un attributo che in realtà non esiste nella relazione genitore, allora non si riferisce a nulla. Sono proprio queste situazioni che devono essere evitate in ogni modo possibile, e questo significa mantenere l'integrità referenziale. Ma, sapendo che nessun database consentirà mai la creazione di una tupla penzolante, gli sviluppatori si assicurano che non ci siano tuple penzolanti inizialmente nel database e che tutte le chiavi disponibili si riferiscano a un attributo molto reale della relazione genitore. Tuttavia, ci sono situazioni in cui si formano tuple penzolanti già durante il funzionamento del database. Quali sono queste situazioni? È noto che quando le tuple vengono rimosse dalla relazione padre o quando il valore chiave di una tupla della relazione padre viene aggiornato, l'integrità referenziale può essere violata, ovvero possono verificarsi tuple penzolanti. Per escludere la possibilità che si verifichino quando si dichiara un valore di chiave esterna, viene specificato uno dei seguenti: tre disponibile regole mantenendo l'integrità referenziale, applicata di conseguenza quando si aggiorna il valore chiave nella relazione padre (cioè, come accennato in precedenza, in aggiornamento) o quando si rimuove una tupla dalla relazione padre (in cancellazione). Va notato che l'aggiunta di una nuova tupla alla relazione genitore non può violare l'integrità referenziale, per ovvi motivi. Dopotutto, se questa tupla è stata appena aggiunta alla relazione di base, nessun attributo potrebbe riferirsi ad essa prima a causa della sua assenza! Quindi quali sono queste tre regole utilizzate per mantenere l'integrità referenziale nei database? Elenchiamoli. 1. limitareO regola di restrizione. Se, quando si imposta la nostra relazione di base, quando si dichiarano chiavi esterne in un vincolo di integrità referenziale, abbiamo applicato questa regola per mantenerla, l'aggiornamento di una chiave nella relazione genitore o l'eliminazione di una tupla dalla relazione genitore semplicemente non possono essere eseguiti se questa tupla è referenziato da almeno una tupla della relazione figlio, cioè operazione limitare vieta categoricamente di eseguire qualsiasi azione che possa portare alla comparsa di tuple sospese. Illustriamo l'applicazione di questa regola con il seguente esempio. Siano date due relazioni: Atteggiamento genitoriale
relazione con il bambino
Vediamo che le tuple della relazione figlia (2,...) e (2,...) si riferiscono alla tupla della relazione genitore (..., 2), e la tupla della relazione figlio (3,...) si riferisce a il (…,3) atteggiamento genitoriale. La tupla (100,...) della relazione figlia è penzolata e non è valida. Qui, solo le tuple della relazione genitore (..., 1) e (..., 4) consentono l'aggiornamento dei valori delle chiavi e l'eliminazione delle tuple perché non fanno riferimento a nessuna delle chiavi esterne della relazione figlio. Componiamo l'operatore per la creazione di una relazione di base, che includa la dichiarazione di tutte le chiavi di cui sopra: Crea una tabella Atteggiamento genitoriale Chiave primaria Numero intero non nullo chiave primaria (Chiave primaria) Crea una tabella relazione con il bambino Chiave_esterna Numero intero Nullo chiave esterna (Chiave_esterna) Riferimenti Relazione genitore (chiave_primaria) all'aggiornamento Limita elimina Limita 2. CascataO regola di modifica a cascata. Se, quando si dichiarano le chiavi esterne nella nostra relazione di base, abbiamo utilizzato la regola del mantenimento dell'integrità referenziale Cascata, quindi l'aggiornamento di una chiave nella relazione padre o l'eliminazione di una tupla dalla relazione padre fa sì che le chiavi e le tuple corrispondenti della relazione figlio vengano aggiornate o eliminate automaticamente. Diamo un'occhiata a un esempio per capire meglio come funziona la regola di modifica a cascata. Si forniscano le relazioni di base già a noi familiari dall'esempio precedente: Atteggiamento genitoriale
и relazione con il bambino
Supponiamo di aggiornare alcune tuple nella tabella che definisce la relazione “Relazione genitore”, ovvero di sostituire la tupla (..., 2) con la tupla (..., 20), cioè otteniamo una nuova relazione: Atteggiamento genitoriale
E allo stesso tempo nella dichiarazione di creazione della nostra relazione di base "Relazione figlio" quando si dichiarano le chiavi esterne, abbiamo utilizzato la regola del mantenimento dell'integrità referenziale Cascata, ovvero l'operatore per creare la nostra relazione di base è simile al seguente: Crea una tabella Atteggiamento genitoriale Chiave primaria Numero intero non nullo chiave primaria (Chiave primaria) Crea una tabella relazione con il bambino Chiave_esterna Numero intero Nullo chiave esterna (Chiave_esterna) Riferimenti Relazione genitore (chiave_primaria) sull'aggiornamento Cascata su eliminare Cascade Allora cosa succede alla relazione con il figlio quando la relazione con il genitore viene aggiornata nel modo sopra descritto? Avrà la seguente forma: relazione con il bambino
Così, appunto, la regola Cascata fornisce un aggiornamento a cascata di tutte le tuple nella relazione figlio in risposta agli aggiornamenti della relazione padre. 3. Imposta nulloO regola di assegnazione nulla. Se, nella dichiarazione di creazione della nostra relazione di base, quando dichiariamo chiavi esterne, applichiamo la regola del mantenimento dell'integrità referenziale Imposta nullo, quindi aggiornare la chiave di una relazione genitore o eliminare una tupla da una relazione genitore comporta l'assegnazione automatica di valori Null a quegli attributi di chiave esterna della relazione figlia che consentono valori Null. Pertanto, la regola è applicabile se tali attributi esistono. Diamo un'occhiata a un esempio che abbiamo già utilizzato in precedenza. Supponiamo di avere due relazioni fondamentali: "Genitori"
relazione con il bambino
Come puoi vedere, gli attributi di relazione figlio consentono valori Null, da cui la regola Imposta nullo applicabile in questo caso particolare. Supponiamo ora che la tupla (..., 1) sia stata rimossa dalla relazione genitore e che la tupla (..., 2) sia stata aggiornata, come nell'esempio precedente. Pertanto, la relazione genitore assume la seguente forma: Atteggiamento genitoriale
Quindi, tenendo conto del fatto che nel dichiarare le chiavi esterne della relazione figlio, abbiamo applicato la regola del mantenimento dell'integrità referenziale Imposta nullo, la relazione figlio sarà simile a questa: relazione con il bambino
La tupla (..., 1) non è stata referenziata da alcuna chiave di relazione figlio, quindi la sua eliminazione non ha conseguenze. Lo stesso operatore di creazione della relazione di base che utilizza la regola Imposta nullo quando si dichiarano le chiavi esterne, la relazione è simile alla seguente: Crea una tabella Atteggiamento genitoriale Chiave primaria Numero intero non nullo chiave primaria (Chiave primaria) Crea una tabella relazione con il bambino Chiave_esterna Numero intero Nullo chiave esterna (Chiave_esterna) Riferimenti Relazione genitore (chiave_primaria) all'aggiornamento Imposta Null su eliminare Imposta Null Quindi, vediamo che la presenza di tre diverse regole per mantenere l'integrità referenziale assicura che nelle frasi in aggiornamento и in cancellazione le funzioni possono variare. Va ricordato e compreso che l'inserimento di tuple in una relazione figlio o l'aggiornamento dei valori chiave delle relazioni figlio non verranno eseguiti se ciò comporta una violazione dell'integrità referenziale, ovvero alla comparsa delle cosiddette tuple penzolanti. Rimuovere le tuple da una relazione figlio in nessun caso può portare a una violazione dell'integrità referenziale. È interessante notare che una relazione figlio può agire contemporaneamente come una relazione genitore con le proprie regole per mantenere l'integrità referenziale, se le chiavi esterne di altre relazioni di base si riferiscono ad alcuni dei suoi attributi come chiavi primarie. Se i programmatori vogliono garantire che l'integrità referenziale sia applicata da alcune regole diverse dalle regole standard di cui sopra, il supporto procedurale per tali regole non standard per il mantenimento dell'integrità referenziale viene fornito con l'aiuto dei cosiddetti trigger. Sfortunatamente, una considerazione dettagliata di questo concetto non scende nel nostro corso di lezioni. 5. Il concetto di indici La creazione di chiavi nelle relazioni di base è automaticamente collegata alla creazione di indici. Definiamo la nozione di indice. Indice - questa è una struttura di dati di sistema che contiene un elenco di valori necessariamente ordinato di una chiave con collegamenti a quelle tuple della relazione in cui si verificano questi valori. Esistono due tipi di indici nei sistemi di gestione dei database: 1) semplice. Un semplice indice viene preso per un sottoschema dello schema della relazione di base da un singolo attributo; 2) composito. Di conseguenza, un indice composito è un indice per un sottoschema costituito da diversi attributi. Ma, oltre alla divisione in indici semplici e compositi, nei sistemi di gestione di database esiste una divisione degli indici in univoci e non univoci. Così: 1) unico gli indici sono indici che fanno riferimento al massimo a un attributo. Gli indici univoci generalmente corrispondono alla chiave primaria della relazione; 2) non unico gli indici sono indici che possono corrispondere a più attributi contemporaneamente. Le chiavi non univoche, a loro volta, corrispondono molto spesso alle chiavi esterne della relazione. Si consideri un esempio che illustra la divisione degli indici in univoci e non univoci, ovvero si considerino le seguenti relazioni definite dalle tabelle:
Qui, rispettivamente, Chiave primaria è la chiave primaria della relazione, Chiave esterna è la chiave esterna. È chiaro che in queste relazioni l'indice dell'attributo Chiave primaria è unico, poiché corrisponde alla chiave primaria, cioè un attributo, e l'indice dell'attributo Chiave esterna non è univoco, perché corrisponde a chiavi. E il suo valore "20" corrisponde sia alla prima che alla terza riga della tabella delle relazioni. Ma a volte gli indici possono essere creati indipendentemente dalle chiavi. Questo viene fatto nei sistemi di gestione del database per supportare l'esecuzione delle operazioni di ordinamento e ricerca. Ad esempio, una ricerca dicotomica per un valore di indice in tuple verrà implementata nei sistemi di gestione di database in venti iterazioni. Da dove provengono queste informazioni? Sono stati ottenuti con semplici calcoli, ovvero come segue: 106 = (103)2 = 220; Gli indici vengono creati nei sistemi di gestione di database utilizzando l'istruzione Create a noi già nota, ma solo con l'aggiunta della parola chiave index. Un tale operatore si presenta così: Crea indice nome dell'indice On nome della relazione di base (nome attributo,..); Qui vediamo il familiare simbolo metalinguistico ",.." che denota la possibilità di ripetere un argomento separato da una virgola, cioè un indice corrispondente a più attributi può essere creato in questo operatore. Se vuoi dichiarare un indice univoco, aggiungi la parola chiave univoca prima della parola indice, quindi l'intera istruzione di creazione nella relazione dell'indice di base diventa: Crea un indice univoco nome dell'indice On nome della relazione di base (nome attributo); Quindi, nella forma più generale, se ricordiamo la regola per designare elementi opzionali (il simbolo metalinguistico []), l'operatore di creazione dell'indice nella relazione di base sarà simile a questo: Crea indice [unico]. nome dell'indice On nome della relazione di base (nome attributo,..); Se vuoi rimuovere un indice già esistente dalla relazione di base, usa l'operatore Drop, anche a noi già noto: indice di caduta {nome della relazione di base. Nome indice},.. ; Perché qui viene utilizzato il nome di indice completo "nome relazione di base. Nome indice"? Un operatore di rilascio dell'indice utilizza sempre il proprio nome completo perché il nome dell'indice deve essere univoco all'interno della stessa relazione, ma non di più. 6. Modifica delle relazioni di base Per lavorare con successo e in modo produttivo con varie relazioni di base, molto spesso gli sviluppatori devono modificare in qualche modo questa relazione di base. Quali sono le principali opzioni di modifica richieste che si incontrano più spesso nella pratica di progettazione di database? Elenchiamoli: 1) inserimento di tuple. Molto spesso è necessario inserire nuove tuple in una relazione di base già formata; 2) aggiornamento dei valori degli attributi. E la necessità di questa modifica nella pratica di programmazione è ancora più comune della precedente, perché quando arrivano nuove informazioni sugli argomenti del tuo database, dovrai inevitabilmente aggiornare alcune vecchie informazioni; 3) rimozione delle tuple. E con circa uguale probabilità, diventa necessario rimuovere dalla relazione di base quelle tuple la cui presenza nel database non è più richiesta a causa delle nuove informazioni ricevute. Quindi, abbiamo delineato i punti principali della modifica delle relazioni di base. Come si può raggiungere ciascuno di questi obiettivi? Nei sistemi di gestione dei database, nella maggior parte dei casi sono presenti operatori di modifica delle relazioni di base incorporati. Descriviamoli in una voce pseudo-codice: 1) operatore di inserimento nella relazione di base delle nuove tuple. Questo è l'operatore inserire. Si presenta così: Inserire nome della relazione di base (nome attributo,..) Valori (valore attributo,..); Il simbolo metalinguistico ",.." dopo il nome dell'attributo e il valore dell'attributo ci dice che questo operatore consente di aggiungere più attributi alla relazione di base contemporaneamente. In questo caso, è necessario elencare i nomi degli attributi ei valori degli attributi, separati da virgole, in un ordine coerente. Ключевое слово ai miglioramenti in combinazione con il nome generale dell'operatore inserire significa "inserire in" e indica in quale relazione vanno inseriti gli attributi tra parentesi. Ключевое слово Valori in questa affermazione, e significa "valori", "valori", che sono assegnati a questi attributi appena dichiarati; 2) ora considera operatore di aggiornamento valori degli attributi nella relazione di base. Questo operatore è chiamato Aggiornanento, che è tradotto dall'inglese e significa letteralmente "aggiornamento". Diamo la forma generale completa di questo operatore in una notazione pseudo-codice e decifralo: Aggiornanento nome della relazione di base Impostato {nome attributo - valore attributo},.. Dove condizione; Quindi, nella prima riga dell'operatore dopo la parola chiave Aggiornanento viene scritto il nome della relazione di base in cui devono essere effettuati gli aggiornamenti. La parola chiave Set è tradotta dall'inglese come "set" e questa riga dell'istruzione specifica i nomi degli attributi da aggiornare ei corrispondenti nuovi valori di attributo. È possibile aggiornare più attributi contemporaneamente in un'unica affermazione, che deriva dall'uso del simbolo metalinguistico ",..". Sulla terza riga dopo la parola chiave Dove viene scritta una condizione che mostra esattamente quali attributi di questa relazione di base devono essere aggiornati; 3) operatore Eliminapermettendo rimuovere qualsiasi tupla dalla relazione di base. Scriviamo la sua forma completa in pseudocodice e spieghiamo il significato di tutte le singole unità sintattiche: Elimina da nome della relazione di base Dove condizione; Ключевое слово da abbinato al nome dell'operatore Elimina si traduce come "rimuovere da". E dopo queste parole chiave nella prima riga dell'operatore, viene indicato il nome della relazione di base, dalla quale devono essere rimosse eventuali tuple. E nella seconda riga dell'operatore dopo la parola chiave Dove ("dove") indica la condizione in base alla quale vengono selezionate le tuple che non sono più richieste nella nostra relazione di base. Lezione numero 9. Dipendenze funzionali 1. Limitazione della dipendenza funzionale Il vincolo di unicità imposto dalle dichiarazioni di chiave primaria e candidata di una relazione è un caso speciale del vincolo associato alla nozione dipendenze funzionali. Per spiegare il concetto di dipendenza funzionale, si consideri il seguente esempio. Ci venga data una relazione contenente dati sui risultati di una particolare sessione. Lo schema di questa relazione si presenta così: Sessione (numero di registro, Nome e cognome, soggetto, Grado); Gli attributi "Numero registro" e "Soggetto" formano una chiave primaria composta (poiché due attributi sono dichiarati come chiave) di questa relazione. In effetti, questi due attributi possono determinare in modo univoco i valori di tutti gli altri attributi. Tuttavia, oltre al vincolo di unicità associato a questa chiave, la relazione deve necessariamente essere soggetta alla condizione che un registro dei voti sia rilasciato a una determinata persona e, quindi, a questo proposito, le tuple con lo stesso numero di registro devono contenere gli stessi valori degli attributi "Cognome", "Nome e secondo nome".
Se abbiamo il seguente frammento di un determinato database di studenti di un istituto di istruzione dopo una determinata sessione, quindi in tuple con un numero di registro di 100, gli attributi "Cognome", "Nome" e "Patronimico" sono gli stessi, e gli attributi "Soggetto" e "Valutazione" - non corrispondono (il che è comprensibile, perché parlano di argomenti e prestazioni diverse in essi). Ciò significa che gli attributi "Cognome", "Nome" e "Patronimico" funzionalmente dipendente sull'attributo "Numero registro", mentre gli attributi "Soggetto" e "Valutazione" sono funzionalmente indipendenti. Così, la dipendenza funzionale è una dipendenza a valore singolo tabulata nei sistemi di gestione dei database. Diamo ora una definizione rigorosa di dipendenza funzionale. Definizione: siano X, Y sottoschemi dello schema della relazione S, definenti sopra lo schema S diagramma di dipendenza funzionale X → Y (leggi "Freccia X Y"). Definiamo vincoli di dipendenza funzionale inv<X → Y> come affermazione che, in relazione allo schema S, due tuple qualsiasi che corrispondono in proiezione al sottoschema X devono corrispondere anche in proiezione al sottoschema Y. Scriviamo la stessa definizione sotto forma di formula: Inv<X → Y> r(S) = t1, T2 ∈ r(t1[X] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; Curiosamente, questa definizione utilizza il concetto di un'operazione di proiezione unaria, che abbiamo incontrato in precedenza. In effetti, in quale altro modo, se non si utilizza questa operazione, per mostrare l'uguaglianza di due colonne della tabella delle relazioni, e non righe, l'una all'altra? Pertanto, abbiamo scritto nei termini di questa operazione che la coincidenza di tuple nella proiezione su qualche attributo o più attributi (sottoschema X) comporterà sicuramente la coincidenza delle stesse colonne-tuple sul sottoschema Y nel caso in cui Y dipenda funzionalmente da X. È interessante notare che nel caso di una dipendenza funzionale di Y da X, si dice anche che X definisce funzionalmente Y o cosa Y funzionalmente dipendente su X. Nello schema di dipendenza funzionale X → Y, il sottocircuito X è chiamato lato sinistro e il sottocircuito Y è chiamato lato destro. Nella pratica di progettazione del database, lo schema di dipendenza funzionale è comunemente indicato come dipendenza funzionale per brevità. Fine della definizione. Nel caso speciale in cui il lato destro della dipendenza funzionale, cioè il sottoschema Y, corrisponde all'intero schema della relazione, il vincolo di dipendenza funzionale diventa un vincolo di unicità della chiave primaria o candidata. Veramente: inv r(S) = ∀ t1, T2 ∈ r(t1[K] = t2 [K] → t1(S) = t2(S)), K ⊆ S; È solo che nel definire una dipendenza funzionale, invece del sottoschema X, devi prendere la designazione della chiave K, e invece del lato destro della dipendenza funzionale, sottoschema Y, prendi l'intero schema delle relazioni S, cioè, in effetti, la restrizione all'unicità delle chiavi delle relazioni è un caso speciale di restrizione della dipendenza funzionale quando il lato destro è uguale a schemi di dipendenza funzionale in tutto lo schema delle relazioni. Ecco alcuni esempi dell'immagine della dipendenza funzionale: {Numero registro} → {Cognome, Nome, Patronimico}; {numero registro, materia} → {voto}; 2. Regole di inferenza di Armstrong Se una qualsiasi relazione di base soddisfa le dipendenze funzionali definite dal vettore, allora con l'aiuto di varie regole di inferenza speciali è possibile ottenere altre dipendenze funzionali che questa relazione di base soddisferà sicuramente. Un buon esempio di tali regole speciali sono le regole di inferenza di Armstrong. Ma prima di procedere all'analisi delle stesse regole di inferenza di Armstrong, introduciamo un nuovo simbolo metalinguistico "├", che si chiama simbolo di meta-asserzione di derivabilità. Questo simbolo, quando si formulano le regole, è scritto tra due espressioni sintattiche e indica che la formula alla sua destra deriva dalla formula alla sua sinistra. Formuliamo ora le stesse regole di inferenza di Armstrong nella forma del seguente teorema. Teorema. Sono valide le seguenti regole, denominate regole di inferenza di Armstrong. Regola di inferenza 1. ├ X → X; Regola di inferenza 2. X → Y├ X ∪ Z → Y; Regola di inferenza 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Qui X, Y, Z, W sono sottoschemi arbitrari dello schema della relazione S. Il simbolo della meta-affermazione di derivabilità separa elenchi di premesse ed elenchi di asserzioni (conclusioni). 1. La prima regola di inferenza si chiama "riflessività" e recita come segue: "la regola è dedotta:" X implica funzionalmente X "". Questa è la più semplice delle regole di derivazione di Armstrong. Deriva letteralmente dal nulla. È interessante notare che viene chiamata una dipendenza funzionale che ha parti sia sinistra che destra riflessivo. Secondo la regola della riflessività, il vincolo della dipendenza riflessiva viene eseguito automaticamente. 2. La seconda regola di inferenza si chiama "ricarica" e recita come segue: "se X determina funzionalmente Y, allora viene derivata la regola: "l'unione dei sottocircuiti X e Z comporta funzionalmente Y". La regola di completamento consente di espandere il lato sinistro del vincolo di dipendenza funzionale. 3. La terza regola di inferenza si chiama "pseudotransitività" e recita come segue: "se il sottocircuito X comporta funzionalmente il sottocircuito Y, e l'unione dei sottocircuiti Y e W comporta funzionalmente Z, allora la regola è derivata: "l'unione dei sottocircuiti X e W determina funzionalmente il sottocircuito Z"". La regola di pseudotransitività generalizza la regola di transitività corrispondente al caso speciale W: = 0. Diamo una notazione formale di questa regola: X→Y, Y→Z ├X→Z. Va notato che le premesse e le conclusioni fornite in precedenza sono state presentate in forma abbreviata dalle designazioni degli schemi di dipendenza funzionale. In forma estesa, corrispondono ai seguenti vincoli di dipendenza funzionale. Regola di inferenza 1. inv r(S); Regola di inferenza 2. inv r(S) ⇒ inv r(S); Regola di inferenza 3. inv r(S)&inv r(S) ⇒ inv r(S); Disegnare prova queste regole di inferenza. 1. Prova della regola riflessività segue direttamente dalla definizione del vincolo di dipendenza funzionale quando il sottoschema X è sostituito dal sottocircuito Y. Infatti, prendi il vincolo di dipendenza funzionale: inv r(S) e sostituiamo X invece di Y, otteniamo: inv r(S), e questa è la regola della riflessività. La regola della riflessività è dimostrata. 2. Prova della regola rifornimento Illustriamo su diagrammi di dipendenza funzionale. Il primo diagramma è il diagramma del pacchetto: premessa: X → Y
Secondo diagramma: conclusione: X ∪ Z → Y
Sia le tuple uguali su X ∪ Z. Allora sono uguali su X. Secondo la premessa, saranno uguali anche su Y. La regola di rifornimento è provata. 3. Prova della regola pseudotransitività illustreremo anche sui diagrammi, che in questo caso particolare saranno tre. Il primo diagramma è la prima premessa: premessa 1: X → Y
premessa 2: Y ∪ W → Z
E infine, il terzo diagramma è il diagramma di conclusione: conclusione: X ∪ W → Z
Sia le tuple uguali su X ∪ W. Allora sono uguali sia su X che su W. Secondo la Premessa 1, saranno uguali anche su Y. Quindi, secondo la Premessa 2, saranno uguali anche su Z. La regola della pseudotransitività è dimostrata. Tutte le regole sono provate. 3. Regole di inferenza derivata Un altro esempio di regole da cui si possono, se necessario, derivare nuove regole di dipendenza funzionale sono le cosiddette regole di inferenza derivate. Quali sono queste regole, come si ottengono? È noto che se altri vengono dedotti da alcune regole già esistenti con metodi logici legittimi, allora queste nuove regole, chiamate derivati, può essere utilizzato insieme alle regole originali. Va notato in particolare che queste regole molto arbitrarie sono "derivate" proprio dalle regole di inferenza di Armstrong che abbiamo esaminato in precedenza. Formuliamo le regole derivate per derivare dipendenze funzionali nella forma del seguente teorema. Teorema. Le seguenti regole sono derivate dalle regole di inferenza di Armstrong. Regola di inferenza 1. ├ X ∪ Z → X; Regola di inferenza 2. X → Y, X → Z ├ X ∪ Y → Z; Regola di inferenza 3. X → Y ∪ Z ├ X → Y, X → Z; Qui X, Y, Z, W, come nel caso precedente, sono sottoschemi arbitrari dello schema della relazione S. 1. Viene chiamata la prima regola derivata regola della banalità e si legge così: "Si deriva la regola: 'l'unione dei sottocircuiti X e Z comporta funzionalmente X'". Viene chiamata una dipendenza funzionale in cui il lato sinistro è un sottoinsieme del lato destro banale. Secondo la regola della banalità, i vincoli di dipendenza banale vengono applicati automaticamente. È interessante notare che la regola della banalità è una generalizzazione della regola della riflessività e, come quest'ultima, potrebbe essere derivata direttamente dalla definizione del vincolo di dipendenza funzionale. Il fatto che questa regola sia derivata non è casuale ed è correlato alla completezza del sistema di regole di Armstrong. Parleremo di più della completezza del sistema di regole di Armstrong un po' più avanti. 2. Viene chiamata la seconda regola derivata regola di additività e si legge come segue: "Se il sottocircuito X determina funzionalmente il sottocircuito Y e X determina contemporaneamente Z funzionalmente, da queste regole si deduce la seguente regola: "X determina funzionalmente l'unione dei sottocircuiti Y e Z"". 3. Viene chiamata la terza regola derivata regola della proiettività o la regolainversione dell'additività". Si legge come segue: "Se il sottocircuito X determina funzionalmente l'unione dei sottocircuiti Y e Z, allora da questa regola si deduce la seguente regola: "X determina funzionalmente il sottocircuito Y e allo stesso tempo X determina funzionalmente il sottocircuito Z" ", cioè, in effetti, questa la regola derivata è la regola dell'additività invertita. È curioso che le regole di additività e proiettività applicate alle dipendenze funzionali con le stesse parti sinistre consentano di combinare o, al contrario, dividere le parti destre della dipendenza. Quando si costruiscono catene di inferenza, dopo aver formulato tutte le premesse, viene applicata la regola della transitività per includere una dipendenza funzionale con il lato destro nella conclusione. Disegnare prova regole di inferenza arbitraria elencate. 1. Prova della regola banalità. Eseguiamolo, come tutte le successive dimostrazioni, passo dopo passo: 1) abbiamo: X → X (dalla regola della riflessività dell'inferenza di Armstrong); 2) inoltre abbiamo: X ∪ Z → X (ottenuto applicando prima la regola di completamento dell'inferenza di Armstrong, e poi come conseguenza del primo passo della dimostrazione). La regola della banalità è stata provata. 2. Effettueremo una dimostrazione passo passo della regola additività: 1) abbiamo: X → Y (questa è la premessa 1); 2) abbiamo: X → Z (questa è la premessa 2); 3) abbiamo: Y ∪ Z → Y ∪ Z (dalla regola di Armstrong della riflessività dell'inferenza); 4) abbiamo: X ∪ Z → Y ∪ Z (ottenuto applicando la regola della pseudotransitività dell'inferenza di Armstrong, e quindi come conseguenza del primo e del terzo passo della dimostrazione); 5) abbiamo: X ∪ X → Y ∪ Z (ottenuto applicando la regola di Armstrong della pseudotransitività dell'inferenza, e quindi segue dal secondo e dal quarto passaggio); 6) abbiamo X → Y ∪ Z (segue dal quinto passo). La regola dell'additività è dimostrata. 3. E infine costruiremo una dimostrazione della regola proiettività: 1) abbiamo: X → Y ∪ Z, X → Y ∪ Z (questa è una premessa); 2) abbiamo: Y → Y, Z → Z (derivato utilizzando la regola di riflessività dell'inferenza di Armstrong); 3) abbiamo: Y ∪ z → y, Y ∪ z → Z (ottenuto dalla regola di completamento dell'inferenza di Armstrong e dal corollario del secondo passo della dimostrazione); 4) abbiamo: X → Y, X → Z (ottenuti applicando la regola della pseudotransitività dell'inferenza di Armstrong, e quindi come conseguenza del primo e del terzo passaggio della dimostrazione). La regola della proiettività è dimostrata. Tutte le regole di inferenza derivativa sono dimostrate. 4. Completezza del sistema delle regole Armstrong Sia F(S) un dato insieme di dipendenze funzionali definite sullo schema di relazione S. Indica con inv il vincolo imposto da questo insieme di dipendenze funzionali. Scriviamolo: inv r(S) = ∀X → Y ∈F(S) [inv r(S)]. Quindi, questo insieme di restrizioni imposte dalle dipendenze funzionali viene decifrato come segue: per ogni regola del sistema delle dipendenze funzionali X → Y appartenente all'insieme delle dipendenze funzionali F(S), la restrizione delle dipendenze funzionali inv r(S) definito sull'insieme della relazione r(S). Sia qualche relazione r(S) che soddisfi questo vincolo. Applicando le regole di inferenza di Armstrong alle dipendenze funzionali definite per l'insieme F(S), si possono ottenere nuove dipendenze funzionali, come abbiamo già detto e dimostrato in precedenza. E, che è indicativo, la relazione F(S) soddisferà automaticamente le restrizioni di queste dipendenze funzionali, come si può vedere dalla forma estesa delle regole di inferenza di Armstrong. Ricordiamo la forma generale di queste regole di inferenza estesa: Regola di inferenza 1. inv < X → X > r(S); Regola di inferenza 2. inv r(S) ⇒ inv<X ∪ Z → Y> r(S); Regola di inferenza 3. inv r(S) & inv <Y ∪ W → Z> r(S) ⇒ inv<X ∪ W→Z>; Tornando al nostro ragionamento, riempiamo l'insieme F(S) con nuove dipendenze da esso derivate usando le regole di Armstrong. Applicheremo questa procedura di rifornimento fino a quando non avremo più nuove dipendenze funzionali. Come risultato di questa costruzione, otterremo un nuovo insieme di dipendenze funzionali, chiamato chiusura impostare F(S) e denotare F+(S). In effetti, un tale nome è abbastanza logico, perché noi personalmente, attraverso una lunga costruzione, abbiamo "chiuso" su se stesso l'insieme delle dipendenze funzionali esistenti, aggiungendo (da cui il "+") tutte le nuove dipendenze funzionali risultanti da quelle esistenti. Va notato che questo processo di costruzione di una chiusura è finito, perché lo schema di relazioni stesso, su cui vengono eseguite tutte queste costruzioni, è finito. Va da sé che una chiusura è un superset dell'insieme che si sta chiudendo (anzi, è più grande!) e non cambia in alcun modo quando viene richiuso. Se scriviamo quanto appena detto in forma stereotipata, otteniamo: F(S) ⊆ F+(S), [F+(S)]+=F+(S); Inoltre, dalla verità provata (vale a dire, legalità, legittimità) delle regole di inferenza di Armstrong e la definizione di chiusura, ne consegue che qualsiasi relazione che soddisfi i vincoli di un dato insieme di dipendenze funzionali soddisferà il vincolo della dipendenza appartenente alla chiusura . X → Y ∈ F+(S) ⇒ ∀r(S) [inv r(S) ⇒ inv r(S)]; Quindi, il teorema di completezza di Armstrong per il sistema di regole di inferenza afferma che l'implicazione esterna può essere legittimamente e giustamente sostituita dall'equivalenza. (Non considereremo la dimostrazione di questo teorema, poiché il processo di dimostrazione in sé non è così importante nel nostro particolare corso di lezioni.) Lezione numero 10. Forme normali 1. Il significato della normalizzazione dello schema del database Il concetto che considereremo in questa sezione è legato al concetto di dipendenze funzionali, ovvero il significato di normalizzare gli schemi di database è indissolubilmente legato al concetto di restrizioni imposte da un sistema di dipendenze funzionali, e deriva in gran parte da questo concetto. Il punto di partenza di qualsiasi progettazione di database è rappresentare il dominio come una o più relazioni e in ogni fase della progettazione viene prodotta una serie di schemi di relazioni con proprietà "potenziate". Pertanto, il processo di progettazione è un processo di normalizzazione dei modelli di relazione, in cui ogni forma normale successiva ha proprietà che sono in un certo senso migliori della precedente. Ogni forma normale ha un certo insieme di vincoli e una relazione è in una certa forma normale se soddisfa il proprio insieme di vincoli. Un esempio è la restrizione della prima forma normale: i valori di tutti gli attributi della relazione sono atomici. Nella teoria dei database relazionali, di solito si distingue la seguente sequenza di forme normali: 1) prima forma normale (1 NF); 2) seconda forma normale (2 NF); 3) terza forma normale (3 NF); 4) Forma normale Boyce-Codd (BCNF); 5) quarta forma normale (4 NF); 6) quinta forma normale, o forma normale a proiezione (5 NF o PJ/NF). (Questo corso di lezioni include una discussione dettagliata delle prime quattro forme normali di relazioni di base, quindi non analizzeremo in dettaglio la quarta e la quinta forma normale.) Le principali proprietà delle forme normali sono le seguenti: 1) ogni forma normale successiva è in un certo senso migliore della precedente forma normale; 2) quando si passa alla successiva forma normale, vengono conservate le proprietà delle precedenti forme normali. Il processo di progettazione si basa sul metodo della normalizzazione, ovvero la scomposizione di una relazione che si trova nella forma normale precedente in due o più relazioni che soddisfano i requisiti della forma normale successiva (lo incontreremo quando dovremo normalizzare quella mentre esaminiamo il materiale) o qualche altra relazione di base). Come accennato nella sezione sulla creazione di relazioni di base, gli insiemi dati di dipendenze funzionali impongono restrizioni appropriate agli schemi delle relazioni di base. Queste restrizioni sono generalmente implementate in due modi: 1) in modo dichiarativo, cioè dichiarando vari tipi di chiavi primarie, candidate ed esterne nella relazione di base (questo è il metodo più utilizzato); 2) proceduralmente, ovvero scrivendo il codice del programma (usando i cosiddetti trigger sopra citati). Con l'aiuto di una logica semplice, puoi capire qual è lo scopo di normalizzare gli schemi di database. Normalizzare i database o portare i database a una forma normale significa definire tali schemi di relazioni di base al fine di ridurre al minimo la necessità di scrivere codice di programma, aumentare le prestazioni del database e facilitare il mantenimento dell'integrità dei dati mediante l'integrità dello stato e referenziale. Cioè, per rendere il codice e lavorarci il più semplice e conveniente possibile per sviluppatori e utenti. Per dimostrare visivamente in confronto il funzionamento di un database non normalizzato e normalizzato, si consideri il seguente esempio. Prendiamo una relazione di base contenente informazioni sui risultati della sessione d'esame. Abbiamo già considerato un database di questo tipo in precedenza. Così, opzione 1 schemi di database. Sessione (numero di registro, Nome e cognome, soggetto, Grado) In questa relazione, come puoi vedere dall'immagine dello schema della relazione di base, viene definita una chiave primaria composita: Chiave primaria (numero del libro di classe, Soggetto); Anche a questo proposito viene impostato un sistema di dipendenze funzionali: {Numero registro} → {Cognome, Nome, Patronimico}; Ecco una vista tabellare di un piccolo frammento di un database con questo schema di relazione. Abbiamo già utilizzato questo frammento per considerare i limiti delle dipendenze funzionali, quindi sarà abbastanza facile per noi capire questo argomento usando il suo esempio.
Qui, al fine di mantenere l'integrità dei dati per stato, cioè per soddisfare la restrizione del sistema di dipendenza funzionale {numero libro di classe} → {Cognome, Nome, Patronimico} quando si cambia, ad esempio, il cognome, è necessario esaminare tutte le tuple di questa relazione di base e inserire in sequenza le modifiche necessarie. Tuttavia, poiché si tratta di un processo piuttosto macchinoso e dispendioso in termini di tempo (soprattutto se si tratta di un database di un grande istituto di istruzione), gli sviluppatori di sistemi di gestione di database sono giunti alla conclusione che questo processo deve essere automatizzato, ovvero , reso automatico. Ora, il controllo sull'adempimento di questa (e di ogni altra) dipendenza funzionale può essere organizzato automaticamente utilizzando la corretta dichiarazione di varie chiavi nella relazione di base e la cosiddetta scomposizione (cioè, spezzando qualcosa in più parti indipendenti) di questa relazione. Quindi, dividiamo il nostro schema di relazione "Sessione" esistente in due schemi: lo schema "Studenti", che contiene solo informazioni sugli studenti di un determinato istituto di istruzione, e lo schema "Sessione", che contiene informazioni sull'ultima sessione passata. E poi dichiareremo le chiavi in modo tale da poter ottenere facilmente tutte le informazioni necessarie. Mostriamo come appariranno questi nuovi schemi di relazione con le loro chiavi. opzione 2 schemi di database. Studenti (numero di registro, Nome e cognome), Chiave primaria (numero di registro). Sessione (Numero del registro, Oggetto, Grado), Chiave primaria (numero di registro, Soggetto), Riferimenti chiave straniera (numero di registro) Studenti (numero di registro). Cosa abbiamo adesso? In relazione a "Studenti", la chiave primaria "Numero registro" determina funzionalmente gli altri tre attributi: "Cognome", "Nome" e "Patronimico". E in relazione a "Sessione", anche la chiave primaria composita "Gradebook No., Subject" definisce in modo inequivocabile l'ultimo attributo di questo schema di relazione - "Punteggio". E il collegamento tra questi due rapporti è stato stabilito: lo si realizza attraverso la chiave esterna del rapporto “Session” “Gradebook No”, che fa riferimento all'attributo omonimo nel rapporto “Studenti” e, quando richiesto, fornisce tutte le informazioni necessarie. Mostriamo ora come saranno le relazioni rappresentate dalle tabelle corrispondenti alla seconda opzione di specificare gli schemi di database corrispondenti.
Quindi, vediamo che l'obiettivo della normalizzazione in termini di restrizioni imposte dalle dipendenze funzionali è la necessità di imporre le dipendenze funzionali richieste a qualsiasi database utilizzando dichiarazioni di vari tipi di chiavi primarie, candidate ed esterne delle relazioni di base. 2. Prima forma normale (1NF) Nelle prime fasi della progettazione del database e dello sviluppo di schemi di gestione del database, attributi semplici e non ambigui sono stati utilizzati come unità di codice più produttive e razionali. Quindi hanno utilizzato insieme agli attributi semplici e composti, nonché agli attributi a valore singolo e multivalore. Spieghiamo il significato di ciascuno di questi concetti. Attributi compositi, a differenza di quelli semplici, sono attributi composti da più attributi semplici. Attributi multivalore, a differenza di quelli a valore singolo, sono attributi che rappresentano più valori. Di seguito sono riportati esempi di attributi semplici, composti, a valore singolo e multivalore. Considera la seguente tabella che rappresenta la relazione:
Qui l'attributo "Telefono" è semplice, non ambiguo e l'attributo "Indirizzo" è semplice, ma multivalore. Consideriamo ora un'altra tabella, con attributi diversi:
In questa relazione, rappresentata dalla tabella, l'attributo "Telefoni" è semplice ma multivalore e l'attributo "Indirizzi" è sia composto che multivalore. In generale, sono possibili varie combinazioni di attributi semplici o composti. In diversi casi, le tabelle che rappresentano le relazioni possono apparire in generale così:
Quando si normalizzano gli schemi di relazione di base, i programmatori possono utilizzare uno dei quattro tipi più comuni di forme normali: prima forma normale (1NF), seconda forma normale (2NF), terza forma normale (3NF) o forma normale Boyce-Codd (NFBC) . Per chiarire: l'abbreviazione NF è un'abbreviazione della frase inglese Normal Form. Formalmente, oltre a quanto sopra, ci sono altri tipi di forme normali, ma le sopra sono una delle più popolari. Attualmente, gli sviluppatori di database stanno cercando di evitare attributi composti e multivalore per non complicare la scrittura del codice, non sovraccaricarne la struttura e non confondere gli utenti. Da queste considerazioni discende logicamente la definizione della prima forma normale. Definizione. Qualsiasi relazione di base è in prima forma normale se e solo se lo schema di questa relazione contiene solo attributi semplici e solo a valore singolo, e necessariamente con la stessa semantica. Per spiegare visivamente le differenze tra relazioni normalizzate e non normalizzate, considera un esempio. Sia, esiste una relazione non normalizzata, con il seguente schema. Così, opzione 1 schemi di relazione con una semplice chiave primaria definita su di essa: Dipendenti (numero del personale, Cognome, Nome, Patronimico, Prefisso, Telefono, Data di ammissione o di licenziamento); Chiave primaria (numero personale); Elenchiamo quali errori ci sono in questo schema di relazione, cioè chiameremo quei segni che rendono questo schema proprio non normalizzato: 1) l'attributo "Cognome Nome Patronimico" è composto, cioè composto da elementi eterogenei; 2) l'attributo "Telefoni" è multivalore, ovvero il suo valore è un insieme di valori; 3) l'attributo "Data di accettazione o di licenziamento" non ha una semantica univoca, ovvero in quest'ultimo caso non è chiaro quale data venga inserita. Se, ad esempio, viene introdotto un attributo aggiuntivo per definire più precisamente il significato di una data, il valore di tale attributo sarà semanticamente chiaro, ma resta comunque possibile memorizzare solo una delle date specificate per ciascun dipendente. Cosa bisogna fare per riportare questa relazione alla forma normale? In primo luogo, è necessario dividere gli attributi compositi in attributi semplici per escludere questi attributi molto compositi, così come gli attributi con semantica composita. E in secondo luogo, è necessario scomporre questa relazione, cioè è necessario romperla in diverse nuove relazioni indipendenti per escludere attributi multivalore. Pertanto, tenendo conto di tutto quanto sopra, dopo aver ridotto la relazione "Impiegati" alla prima forma normale o 1NF scomponendola, otterremo un sistema delle seguenti relazioni con chiavi primarie ed esterne impostate su di esse. Così, opzione 2 relazioni: Dipendenti (numero del personale, Cognome, Nome, Patronimico, Incarico, Data di ammissione, Data di licenziamento); Chiave primaria (numero personale); telefoni (Numero del personale, telefono); Chiave primaria (numero personale, telefono); Riferimenti chiave esterna (numero personale) Dipendenti (numero personale); Allora cosa vediamo? L'attributo composto "Cognome Nome Patronimico" non è più nella nostra relazione, al suo posto sono presenti tre semplici attributi "Cognome", "Nome" e "Patronimico", pertanto tale motivo di "anomalia" del rapporto è stato escluso . Inoltre, al posto dell'attributo con semantica poco chiara "Data di assunzione o licenziamento", ora abbiamo due attributi "Data di ammissione" e "Data di licenziamento", ognuno dei quali ha una semantica univoca. Pertanto, anche la seconda ragione per cui la nostra relazione "Dipendenti" non è in forma normale viene eliminata in modo sicuro. E, infine, l'ultimo motivo per cui la relazione "Dipendenti" non è stata normalizzata è la presenza dell'attributo multivalore "Telefoni". Per sbarazzarsi di questo attributo, è stato necessario scomporre l'intera relazione. Come risultato di questa scomposizione, l'attributo "Telefoni" è stato escluso dalla relazione originale "Dipendenti" in generale, ma si è formata una seconda relazione - "Telefoni", in cui sono presenti due attributi: "numero personale del dipendente" e "Telefono ", cioè tutti gli attributi - ancora semplice, la condizione di appartenenza alla prima forma normale è soddisfatta. Questi attributi "Numero dipendente" e "Telefono" formano una chiave primaria composita della relazione "Telefoni" e l'attributo "Numero dipendente", a sua volta, è una chiave esterna che fa riferimento all'attributo con lo stesso nome in "Dipendenti "relazione, ovvero in relazione "Telefoni" l'attributo della chiave primaria "numero personale" è anche una chiave esterna riferita alla chiave primaria della relazione "Dipendenti". Pertanto, viene fornito un collegamento tra le due relazioni. Utilizzando questo collegamento, puoi visualizzare l'intero elenco dei suoi telefoni in base al numero di personale di qualsiasi dipendente senza troppi sforzi e tempo senza ricorrere all'uso di attributi compositi. Si noti che se ci fossero dipendenze funzionali in relazione al sistema, dopo tutte le trasformazioni di cui sopra, la normalizzazione non sarebbe completata. Tuttavia, in questo particolare esempio, non ci sono vincoli di dipendenza funzionale, quindi non è richiesta un'ulteriore normalizzazione di questa relazione. 3. Seconda forma normale (2NF) Requisiti più severi sono imposti alle relazioni dalla seconda forma normale, o 2NF. Questo perché la definizione della seconda forma normale delle relazioni implica, in contrasto con la prima forma normale, la presenza di un sistema di vincoli alle dipendenze funzionali. Definizione. La relazione di base è in seconda forma normale relativo a un dato insieme di dipendenze funzionali se e solo se è in prima forma normale e, inoltre, ogni attributo non chiave è completamente dipendente funzionalmente da ciascuna chiave. In questa definizione attributo non chiave è qualsiasi attributo di relazione che non è contenuto in alcuna chiave primaria o candidata della relazione. La piena dipendenza funzionale da una chiave non implica alcuna dipendenza funzionale da nessuna parte di quella chiave. Pertanto, ora, quando si normalizza una relazione, dobbiamo anche monitorare il rispetto delle condizioni affinché la relazione sia nella prima forma normale, ovvero garantire che i suoi attributi siano semplici e non ambigui, nonché il rispetto della seconda condizione relativa le restrizioni delle dipendenze funzionali. È chiaro che le relazioni con chiavi semplici (primarie e candidate) sono certamente in seconda forma normale. In effetti, in questo caso, la dipendenza da una parte della chiave semplicemente non sembra possibile, perché la chiave semplicemente non ha parti separate. Consideriamo ora, come nel passaggio dell'argomento precedente, un esempio di schema di relazioni non normalizzate e il processo di normalizzazione stesso. Così, opzione 1 schemi di relazione: Pubblico (Edificio n., Auditorium n., Superficie mq. m, n. comandante di servizio del corpo); Chiave primaria (numero del corpus, numero del pubblico); Inoltre, viene definito il seguente sistema di dipendenza funzionale: {N. di corpo} → {N. di servizio comandante di corpo}; Cosa vediamo? Tutte le condizioni perché questa relazione "Pubblico" rimanga nella prima forma normale sono soddisfatte, perché ogni singolo attributo di questa relazione è inequivocabile e semplice. Ma la condizione che ogni elemento non chiave debba essere completamente dipendente funzionalmente dalla chiave non è soddisfatta. Come mai? Sì, perché l'attributo "n. del comandante di stato maggiore" dipende funzionalmente non dalla chiave composita "n. del corpo, n. dell'uditorio", ma da una parte di questa chiave, cioè dall'attributo "No. del corpo". In effetti, dopotutto, è il numero di corpo che determina completamente quale particolare comandante gli è assegnato e, a sua volta, il numero di personale del comandante di corpo non può dipendere da alcun numero di auditorium. Pertanto, il compito principale della nostra normalizzazione diventa il compito di garantire che le chiavi siano distribuite in modo tale che, in particolare, l'attributo "n. Per ottenere ciò dovremo applicare nuovamente, come nel paragrafo precedente, la scomposizione della relazione. Quindi, il seguente sistema di relazioni, che è opzione 2 La relazione “Pubblico” è stata appena ricavata dalla relazione originaria scomponendola in diverse nuove relazioni indipendenti: Corpo (Scafo n., numero del personale comandante di corpo); Chiave primaria (numero del caso); Pubblico (Edificio n., Auditorium n., Superficie mq. m); Chiave primaria (numero del corpus, numero del pubblico); Riferimenti chiave esterna (numero caso) Casi (numero caso); Cosa vediamo ora? Per quanto riguarda l'attributo non chiave "Corpo", il "Numero del personale del comandante del corpo" dipende in modo completo dalla chiave primaria "Numero del corpo". Qui è pienamente soddisfatta la condizione per trovare la relazione nella seconda forma normale. Passiamo ora alla considerazione della seconda relazione - "Pubblico". Rispetto a "Pubblico", l'attributo della chiave primaria "Caso #" è anche una chiave esterna che fa riferimento alla chiave primaria della relazione "Caso". A questo proposito, l'attributo non chiave "Area mq" è completamente dipendente dall'intera chiave primaria composita "Edificio #, Auditorium #" e non può nemmeno dipendere da nessuna delle sue parti. Così, scomponendo la relazione originaria, siamo giunti alla conclusione che tutte le condizioni della definizione della seconda forma normale sono pienamente soddisfatte. In questo esempio, tutti i requisiti di dipendenza funzionale sono imposti dalla dichiarazione di chiavi primarie (nessuna chiave candidata qui) e chiavi esterne. Pertanto, non è necessaria un'ulteriore normalizzazione. 4. Terza forma normale (3NF) La prossima forma normale che esamineremo è la terza forma normale (o 3NF). A differenza della prima forma normale, così come della seconda forma normale, la terza implica l'assegnazione di un sistema di dipendenze funzionali insieme alla relazione. Formuliamo quali proprietà deve avere una relazione per ridurla alla terza forma normale. Definizione. La relazione di base è in terza forma normale rispetto a un dato insieme di dipendenze funzionali se e solo se è in seconda forma normale e ogni attributo non chiave è completamente dipendente funzionalmente solo dalle chiavi. Pertanto, i requisiti della terza forma normale sono più forti dei requisiti della prima e della seconda forma normale, anche combinati. Infatti, nella terza forma normale, ogni attributo non chiave dipende dalla chiave, e dall'intera chiave, e da nient'altro che la chiave. Illustriamo il processo per portare una relazione non normalizzata alla terza forma normale. Per fare ciò, consideriamo un esempio: una relazione che non è in terza forma normale. Così, opzione 1 schemi del rapporto "Dipendenti": Dipendenti (numero del personale, Cognome, Nome, Patronimico, Incarico, Stipendio); Chiave primaria (numero personale); Inoltre, il seguente sistema di dipendenze funzionali è impostato al di sopra di questa relazione "Dipendenti": {Codice posizione} → {Stipendio}; Infatti, di norma, l'importo del salario, ovvero l'importo del salario, dipende direttamente dalla posizione, e quindi dal suo codice nel database corrispondente. Ecco perché questa relazione "Dipendenti" non è nella terza forma normale, perché risulta che l'attributo non chiave "Stipendio" è completamente dipendente funzionalmente dall'attributo "Codice posizione", sebbene questo attributo non sia chiave. Curiosamente, ogni relazione si riduce alla terza forma normale esattamente nello stesso modo delle due forme prima di questa, cioè per decomposizione. Scomposta la relazione "Dipendenti", otteniamo il seguente sistema di nuove relazioni indipendenti: Così, opzione 2 schemi del rapporto "Dipendenti": Posizioni (Codice posizione, Stipendio); Chiave primaria (codice posizione); Dipendenti (numero del personale, Cognome, Nome, Patronimico, Incarico); Chiave primaria (codice posizione); Riferimenti chiave esterna (Codice posizione) Posizioni (Codice posizione); Ora, come possiamo vedere, in relazione a "Posizione", l'attributo non chiave "Stipendio" è completamente dipendente funzionalmente dalla semplice chiave primaria "Codice posizione" e solo da questa chiave. Si noti che in relazione a "Dipendenti" tutti e quattro gli attributi non chiave "Cognome", "Nome", "Patronimico" e "Codice posizione" dipendono in modo completo dal punto di vista funzionale dalla chiave primaria semplice "Numero di occupazione". A questo proposito, l'attributo "ID posizione" è una chiave esterna che fa riferimento alla chiave primaria della relazione "Posizioni". In questo esempio, tutti i requisiti vengono imposti dichiarando semplici chiavi primarie ed esterne, quindi non è necessaria un'ulteriore normalizzazione. È interessante e utile sapere che in pratica ci si limita solitamente a portare i database alla terza forma normale. Allo stesso tempo, alcune dipendenze funzionali degli attributi chiave su altri attributi della stessa relazione potrebbero non essere imposte. Il supporto per tali dipendenze funzionali non standard viene implementato utilizzando i trigger menzionati in precedenza (ovvero, proceduralmente, scrivendo il codice di programma appropriato). Inoltre, i trigger devono operare con tuple di questa relazione. 5. Forma normale Boyce-Codd (NFBC) La forma normale di Boyce-Codd segue in "complessità" subito dopo la terza forma normale. Pertanto, la forma normale di Boyce-Codd è talvolta chiamata anche semplicemente terza forma normale forte (o rinforzato 3 NF). Perché è rinforzata? Formuliamo la definizione della forma normale di Boyce-Codd: Definizione. La relazione di base è in Boyce forma normale - Kodd se e solo se è nella terza forma normale, e non solo qualsiasi attributo non chiave è completamente dipendente funzionalmente da qualsiasi chiave, ma qualsiasi attributo chiave deve essere completamente dipendente funzionalmente da qualsiasi chiave. Pertanto, il requisito che gli attributi non chiave dipendano effettivamente dall'intera chiave e da nient'altro che la chiave si applica anche agli attributi chiave. In una relazione che è nella forma normale di Boyce-Codd, tutte le dipendenze funzionali all'interno della relazione sono imposte dalla dichiarazione di chiavi. Tuttavia, quando si riducono le relazioni di database alla forma Boyce-Codd, sono possibili situazioni in cui le dipendenze tra gli attributi di varie relazioni risultano non essere dipendenze funzionali imposte. Supportare tali dipendenze funzionali con trigger che operano su tuple di relazioni diverse è più difficile che nel caso della terza forma normale, quando i trigger operano su tuple di una singola relazione. Tra l'altro, la pratica di progettare sistemi di gestione di database ha dimostrato che non è sempre possibile riportare la relazione di base alla forma normale di Boyce-Codd. La ragione delle anomalie rilevate è che i requisiti della seconda forma normale e della terza forma normale non richiedevano una dipendenza funzionale minima dalla chiave primaria degli attributi che sono componenti di altre possibili chiavi. Questo problema è risolto dalla forma normale, che è storicamente chiamata forma normale di Boyce-Codd e che è un perfezionamento della terza forma normale nel caso della presenza di più chiavi possibili sovrapposte. In generale, la normalizzazione dello schema del database rende gli aggiornamenti del database più efficienti per l'esecuzione del sistema di gestione del database poiché riduce il numero di controlli e backup che mantengono l'integrità del database. Quando si progetta un database relazionale, si ottiene quasi sempre la seconda forma normale di tutte le relazioni nel database. Nei database che vengono aggiornati frequentemente, di solito cercano di fornire la terza forma normale della relazione. La forma normale di Boyce-Codd riceve molta meno attenzione perché, in pratica, le situazioni in cui una relazione ha diverse chiavi candidate composite sovrapposte sono rare. Tutto quanto sopra rende la forma normale di Boyce-Codd non molto comoda da usare durante lo sviluppo del codice di programma, quindi, come accennato in precedenza, in pratica, gli sviluppatori di solito si limitano a portare i loro database nella terza forma normale. Tuttavia, ha anche una sua caratteristica piuttosto curiosa. Il punto è che le situazioni in cui una relazione è nella terza forma normale ma non nella forma normale di Boyce-Codd sono estremamente rare nella pratica, cioè, dopo la riduzione alla terza forma normale, di solito tutte le dipendenze funzionali sono imposte da dichiarazioni di primaria, candidata e chiavi esterne, quindi non sono necessari trigger per supportare le dipendenze funzionali. Tuttavia, resta la necessità di trigger per supportare i vincoli di integrità che non sono collegati da dipendenze funzionali. 6. Nidificazione di forme normali Cosa significa annidamento di forme normali? Nidificazione di forme normali - questo è il rapporto tra i concetti di forme indebolite e rafforzate l'una rispetto all'altra. L'annidamento delle forme normali segue completamente dalle rispettive definizioni. Immaginiamo un diagramma che illustri la relazione di annidamento delle forme normali a noi note:
Spieghiamo i concetti di forme normali indebolite e rafforzate l'una rispetto all'altra usando esempi specifici. La prima forma normale è indebolita rispetto alla seconda forma normale (e anche in relazione a tutte le altre forme normali). Infatti, ricordando le definizioni di tutte le forme normali che abbiamo attraversato, possiamo vedere che i requisiti di ciascuna forma normale includevano il requisito di appartenere alla prima forma normale (in fondo era incluso in ogni definizione successiva). La seconda forma normale è più forte della prima forma normale, ma più debole della terza forma normale e della forma normale di Boyce-Codd. Infatti, l'appartenenza alla seconda forma normale è inclusa nella definizione della terza, e la seconda forma stessa, a sua volta, include la prima forma normale. La forma normale di Boyce-Codd non è solo rafforzata rispetto alla terza forma normale, ma anche rispetto a tutte le altre che la precedono. E la terza forma normale, a sua volta, è indebolita solo rispetto alla forma normale Boyce-Codd. Lezione n. 11. Progettazione di schemi di database Il mezzo più comune per astrarre gli schemi di database durante la progettazione a livello logico è il cosiddetto modello entità-relazione. A volte è anche chiamato modello ER, dove ER è un'abbreviazione della frase inglese Entity - Relationship, che letteralmente si traduce come "entità - relazione". Gli elementi di tali modelli sono classi di entità, i loro attributi e relazioni. Daremo spiegazioni e definizioni di ciascuno di questi elementi. Classe di entità è come una classe di oggetti senza metodo nel senso della programmazione orientata agli oggetti. Quando si passa al livello fisico, le classi di entità vengono convertite in relazioni di database relazionali di base per sistemi di gestione di database specifici. Loro, come le stesse relazioni di base, hanno i loro attributi. Diamo una definizione più precisa e rigorosa degli oggetti appena dati. classe è chiamata descrizione con nome di una raccolta di oggetti con attributi, operazioni, relazioni e semantica comuni. Graficamente, una classe è solitamente rappresentata come un rettangolo. Ogni classe deve avere un nome (una stringa di testo) che la distingua in modo univoco da tutte le altre classi. attributo di classe è una proprietà denominata di una classe che descrive l'insieme di valori che le istanze di questa proprietà possono assumere. Una classe può avere un numero qualsiasi di attributi (in particolare, non può avere attributi). Una proprietà espressa da un attributo è una proprietà dell'entità modellata che è comune a tutti gli oggetti della classe data. Quindi un attributo è un'astrazione dello stato di un oggetto. Qualsiasi attributo di qualsiasi oggetto di classe deve avere un valore. Le cosiddette relazioni vengono implementate utilizzando la dichiarazione di chiavi esterne (abbiamo già incontrato fenomeni simili in precedenza), ovvero, in relazione, vengono dichiarate chiavi esterne che si riferiscono alle chiavi primarie o candidate di qualche altra relazione. E attraverso questo, diverse relazioni di base indipendenti sono "collegate" in un unico sistema chiamato database. Inoltre, il diagramma che costituisce la base grafica del modello entità-relazione è rappresentato utilizzando il linguaggio di modellazione unificato UML. Moltissimi libri sono dedicati al linguaggio di modellazione orientato agli oggetti UML (o Unified Modeling Language), molti dei quali sono stati tradotti in russo (e alcuni scritti da autori russi). In generale, UML consente di modellare diversi tipi di sistemi: puramente software, puramente hardware, software-hardware, misti, includendo esplicitamente le attività umane, ecc. Ma, tra le altre cose, come abbiamo già accennato, il linguaggio UML è attivamente utilizzato per progettare database relazionali. Per questo viene utilizzata una piccola parte del linguaggio (diagrammi di classe), e anche allora non per intero. Dal punto di vista della progettazione di database relazionali, le capacità di modellazione non sono troppo diverse da quelle dei diagrammi ER. Abbiamo anche voluto mostrare che nel contesto della progettazione di database relazionali, i metodi di progettazione strutturale basati sull'uso di diagrammi ER e i metodi orientati agli oggetti basati sull'uso del linguaggio UML differiscono principalmente solo nella terminologia. Il modello ER è concettualmente più semplice di UML, ha meno concetti, termini e opzioni applicative. E questo è comprensibile, dal momento che diverse versioni dei modelli ER sono state sviluppate specificamente per supportare la progettazione di database relazionali e i modelli ER non contengono quasi nessuna funzionalità che vada oltre le reali esigenze di un progettista di database relazionali. L'UML appartiene al mondo degli oggetti. Questo mondo è molto più complicato (se vuoi, più incomprensibile, più confuso) del mondo relazionale. Poiché l'UML può essere utilizzato per la modellazione unificata orientata agli oggetti di qualsiasi cosa, il linguaggio contiene una pletora di concetti, termini e casi d'uso che sono ridondanti dal punto di vista della progettazione di database relazionali. Se estraiamo dal meccanismo generale dei diagrammi di classe ciò che è realmente necessario per la progettazione di database relazionali, otterremo esattamente diagrammi ER con una diversa notazione e terminologia. È curioso che quando si formano i nomi delle classi nell'UML, sia consentita una combinazione arbitraria di lettere, numeri e persino segni di punteggiatura. Tuttavia, in pratica, si consiglia di utilizzare aggettivi e nomi brevi e significativi come nomi di classi, ognuno dei quali inizia con una lettera maiuscola. (Tratteremo il concetto di diagramma in modo più dettagliato nel prossimo paragrafo della nostra lezione.) 1. Vari tipi e molteplicità di obbligazioni La relazione tra le relazioni nella progettazione degli schemi di database è rappresentata come linee che collegano le classi di entità. Inoltre, ciascuno degli estremi della connessione può (e generalmente dovrebbe) essere caratterizzato dal nome (cioè dal tipo di connessione) e dalla molteplicità del ruolo della classe nella connessione. Consideriamo più in dettaglio i concetti di molteplicità e tipi di connessioni. molteplicità (molteplicità) è una caratteristica che indica quanti attributi di una classe di entità con un determinato ruolo possono o dovrebbero partecipare a ciascuna istanza di una relazione di qualche tipo. Il modo più comune per impostare la cardinalità di un ruolo di relazione consiste nello specificare direttamente un numero o un intervallo specifico. Ad esempio, specificando "1" si dice che ogni classe con un determinato ruolo deve partecipare a qualche istanza di questa connessione e esattamente un oggetto della classe con questo ruolo può partecipare a ciascuna istanza della connessione. Specificare l'intervallo "0..1" indica che non tutti gli oggetti della classe con un determinato ruolo devono partecipare a qualsiasi istanza di questa relazione, ma solo un oggetto può partecipare a ciascuna istanza della relazione. Parliamo della molteplicità in modo più dettagliato. Le cardinalità tipiche e più comuni nei sistemi di progettazione di database sono le seguenti cardinalità: 1) 1 - la molteplicità della connessione alla sua estremità corrispondente è uguale a uno; 2) 0... 1 - questa forma di notazione significa che la molteplicità di una data connessione all'estremità corrispondente non può superare uno; 3) 0... ∞ - questa molteplicità viene semplicemente decifrata come “molti”. È curioso che, di regola, “molto” significhi “niente”; 4) 1... ∞ - questa designazione è stata data alla molteplicità “uno o più”. Diamo un esempio di un semplice diagramma per illustrare il lavoro con diverse molteplicità di collegamenti.
Secondo questo diagramma, si può facilmente capire che ogni biglietteria ha molti biglietti e, a sua volta, ogni biglietto si trova in una (e non più di quella) biglietteria. Consideriamo ora i tipi o nomi di collegamenti più comuni. Elenchiamoli: 1) 1: 1 - questa designazione è stata data alla connessione "uno a uno", cioè, è, per così dire, una corrispondenza biunivoca di due insiemi; 2) 1 : 0... ∞ - questa è una designazione per una connessione come "uno a molti". Per brevità, tale relazione è chiamata "1: M". Nel diagramma considerato in precedenza, come puoi vedere, c'è una relazione con proprio un tale nome; 3) 0... ∞ : 1 - si tratta di un'inversione del collegamento precedente oppure di un collegamento del tipo "molti a uno"; 4) 0... ∞ : 0... ∞ è una designazione per una connessione come "molti a molti", ovvero ci sono molti attributi a ciascuna estremità del collegamento; 5) 0... 1 : 0... 1 - questa è una connessione simile alla connessione di tipo "uno a uno" precedentemente introdotta, a sua volta si chiama "da non più di uno a non più di uno"; 6) 0... 1 : 0... ∞ - questa è una connessione simile a una connessione uno a molti, si chiama “non più di uno a molti”; 7) 0... ∞ : 0... 1 - questa è una connessione, a sua volta, simile a una connessione di tipo molti-a-uno, si chiama "molti a non più di uno". Come puoi vedere, le ultime tre connessioni sono state ottenute dalle connessioni elencate nella nostra lezione sotto i numeri uno, due e tre sostituendo la molteplicità di "uno" con la molteplicità di "non più di uno". 2. Diagrammi. Tipi di grafici E ora procediamo finalmente direttamente alla considerazione dei diagrammi e dei loro tipi. In generale, ci sono tre livelli del modello logico. Questi livelli differiscono nella profondità della rappresentazione delle informazioni sulla struttura dei dati. Questi livelli corrispondono ai seguenti diagrammi: 1) diagramma di presentazione; 2) schema chiave; 3) diagramma completo degli attributi. Analizziamo ciascuno di questi tipi di diagrammi e spieghiamo in dettaglio il significato delle loro differenze nella profondità della presentazione delle informazioni sulla struttura dei dati. 1. Diagramma di presentazione. Tali diagrammi descrivono solo le classi più elementari di entità e le loro relazioni. Le chiavi in tali diagrammi potrebbero non essere affatto descritte e, di conseguenza, le connessioni potrebbero non essere individualizzate in alcun modo. Pertanto, le relazioni molti-a-molti sono accettabili, anche se di solito vengono evitate o, se esistono, perfezionate. Anche gli attributi compositi e multivalore sono perfettamente validi, sebbene abbiamo scritto in precedenza che le relazioni di base con tali attributi non sono ridotte a nessuna forma normale. È interessante notare che dei tre tipi di diagrammi che abbiamo considerato, solo l'ultimo tipo (il diagramma completo degli attributi) presuppone che i dati presentati con esso siano in una forma normale. Mentre il diagramma di presentazione già considerato e il diagramma chiave successivo nella riga non implicano nulla del genere. Tali diagrammi vengono solitamente utilizzati per le presentazioni (da qui il loro nome - presentazionale, ovvero utilizzato per presentazioni, dimostrazioni, dove non sono necessari dettagli eccessivi). A volte durante la progettazione di database, è necessario consultare esperti nell'area tematica in cui questo particolare database tratta le informazioni. Quindi vengono utilizzati anche i diagrammi di presentazione, perché per ottenere le informazioni necessarie da specialisti di una professione lontana dalla programmazione non è affatto richiesto un eccessivo chiarimento di dettagli specifici. 2. Diagramma chiave. A differenza dei diagrammi di presentazione, i diagrammi chiave descrivono necessariamente tutte le classi di entità e le loro relazioni, tuttavia, solo in termini di chiavi primarie. Qui, le relazioni molti-a-molti sono già necessariamente dettagliate (cioè, le relazioni di questo tipo nella loro forma pura semplicemente non possono essere specificate qui). Gli attributi multivalore sono ancora consentiti allo stesso modo di un diagramma di presentazione, ma se sono presenti in un diagramma chiave, vengono solitamente convertiti in classi di entità separate. Ma, curiosamente, gli attributi a valore singolo possono ancora essere rappresentati o descritti in modo incompleto come compositi. Queste "libertà", che sono ancora valide in diagrammi come i diagrammi presentazionali e chiave, non sono consentite nel prossimo tipo di diagramma, perché determinano che la relazione di base non è normalizzata. Pertanto, possiamo concludere che i diagrammi chiave in futuro assumono solo attributi "sospesi" su classi di entità già descritte, ad es. utilizzando un diagramma di presentazione, è sufficiente descrivere le classi di entità più necessarie e quindi, utilizzando un diagramma chiave, aggiungere tutto ad esso gli attributi necessari e specificare tutti i collegamenti più importanti. 3. Diagramma completo degli attributi. I diagrammi completi degli attributi descrivono nel modo più dettagliato tutte le suddette classi di entità, i loro attributi e le relazioni tra queste classi di entità. Di norma, tali grafici rappresentano dati che sono nella terza forma normale, quindi è naturale che nelle relazioni di base descritte da tali grafici non siano consentiti attributi composti o multivalore, così come non esistono molti-a-granulari molte relazioni. Tuttavia, i grafici degli attributi completi presentano ancora uno svantaggio, ovvero non possono essere definiti completamente i grafici più completi in termini di presentazione dei dati. Ad esempio, la particolarità di specifici sistemi di gestione di database quando si utilizzano diagrammi di attributi completi non viene ancora presa in considerazione e, in particolare, il tipo di dati viene specificato solo nella misura necessaria per il livello logico richiesto di modellazione. 3. Associazioni e migrazioni chiave Poco prima abbiamo già parlato di quali sono le relazioni nei database. In particolare, la relazione è stata stabilita durante la dichiarazione delle chiavi esterne della relazione. Ma in questa sezione del nostro corso non parliamo più di relazioni di base, ma di registratori di cassa di entità. In questo senso, il processo di stabilire relazioni è ancora associato alle dichiarazioni di varie chiavi, ma ora stiamo parlando delle chiavi delle classi di entità. Vale a dire, il processo di creazione di relazioni è associato al trasferimento di una chiave primaria semplice o composita di una classe di entità a un'altra classe. Viene anche chiamato il processo di tale trasferimento migrazione chiave. In questo caso, viene chiamata la classe di entità le cui chiavi primarie vengono trasferite classe genitoree viene chiamata la classe di entità in cui vengono migrate le chiavi esterne classe bambino entità. In una classe di entità figlio, gli attributi chiave ricevono lo stato di attributi di chiave esterna e possono o meno partecipare alla formazione della propria chiave primaria. Pertanto, quando una chiave primaria viene migrata da una classe di entità padre a una classe di entità figlio, nella classe figlia viene visualizzata una chiave esterna che fa riferimento alla chiave primaria della classe padre. Per comodità della rappresentazione formulaica della migrazione delle chiavi, introduciamo i seguenti marcatori chiave: 1) PK: è così che indicheremo qualsiasi attributo della chiave primaria (chiave primaria); 2) FK - con questo marcatore indicheremo gli attributi di una chiave esterna (chiave esterna); 3) PFK - con tale marcatore indicheremo un attributo della chiave primaria/esterna, cioè qualsiasi attributo di questo tipo che fa parte dell'unica chiave primaria di una qualche classe di entità e allo stesso tempo fa parte di qualche chiave esterna della stessa classe di entità . Pertanto, gli attributi di una classe di entità con marcatori PK e FK formano la chiave primaria di questa classe. E attributi con marcatori FK e PFK fanno parte di alcune chiavi esterne di questa classe di entità. In generale, le chiavi possono migrare in modi diversi e, in ognuno di questi casi diversi, si verifica un qualche tipo di connessione. Quindi, consideriamo quali tipi di collegamenti esistono a seconda dello schema di migrazione chiave. In totale, ci sono due principali schemi di migrazione. 1. Schema di migrazione ∀PK (PK |→PFK); In questa voce, il simbolo "|→" indica il concetto di "migrazione", ovvero la formula di cui sopra sarà letta come segue: qualsiasi (ciascun) attributo della chiave primaria PK della classe dell'entità madre viene trasferito (migrazione) alla chiave primaria PFK classe di entità figlio, che, ovviamente, è anche una chiave esterna per questa classe. In questo caso, stiamo parlando del fatto che, senza eccezioni, ogni attributo chiave della classe di entità padre deve essere migrato alla classe di entità figlio. Questo tipo di connessione è chiamato identificativo, poiché la chiave della classe dell'entità padre è interamente coinvolta nell'identificazione delle entità figlio. Tra i link di tipo identificativo, a loro volta, vi sono altri due possibili tipi indipendenti di link. Quindi, ci sono due tipi di link identificativi: 1) identificandosi pienamente. Si dice che una relazione di identificazione sia completamente identificativa se e solo se gli attributi della chiave primaria migrante della classe di entità genitore formano completamente la chiave primaria (ed esterna) della classe di entità figlia. A volte viene anche chiamata una relazione completamente identificativa categorico, perché una relazione completamente identificativa identifica le entità figlie in tutte le categorie; 2) non identificarsi completamente. Una relazione identificativa è detta identificativa incompleta se e solo se gli attributi della chiave primaria migrante della classe entità genitore formano solo parzialmente la chiave primaria (e allo stesso tempo esterna) della classe entità figlia. Quindi, oltre alla chiave con il pennarello PFK avrà anche una chiave contrassegnata con PK. In questo caso, la chiave esterna PFK della classe di entità figlia sarà completamente determinata dalla chiave primaria PK della classe di entità genitore, ma semplicemente la chiave primaria PK di questa relazione figlio non sarà determinata dalla chiave primaria PK del genitore classe di entità, sarà da solo. 2. Schema di migrazione ∃PK (PK |→ FK); Tale schema di migrazione dovrebbe essere letto come segue: esistono tali attributi di chiave primaria della classe di entità padre che, durante la migrazione, vengono trasferiti agli attributi non chiave obbligatori della classe di entità figlia. Quindi, in questo caso, stiamo parlando del fatto che alcuni, e non tutti, come nel caso precedente, gli attributi della chiave primaria della classe dell'entità genitore vengono trasferiti alla classe dell'entità figlia. Inoltre, se il precedente schema di migrazione definiva la migrazione alla chiave primaria della relazione figlio, che allo stesso tempo diventava anche una chiave esterna, allora l'ultimo tipo di migrazione determina che gli attributi della chiave primaria della classe dell'entità madre migrano a quelli ordinari , inizialmente attributi non chiave, che successivamente acquisiscono lo stato di chiave esterna. Questo tipo di connessione è chiamato non identificativo, poiché, in effetti, la chiave madre non è interamente coinvolta nella formazione delle entità figlie, semplicemente non le identifica. Tra le relazioni non identificative si distinguono anche due possibili tipi di relazione. Pertanto, le relazioni non identificative sono dei seguenti due tipi: 1) necessariamente non identificativo. Si dice che le relazioni non identificative siano necessariamente non identificative se e solo se i valori Null per tutti gli attributi chiave di migrazione di una classe di entità figlio sono proibiti; 2) opzionalmente non identificativo. Si dice che le relazioni non identificative non siano necessariamente non identificative se e solo se sono consentiti valori nulli per alcuni attributi chiave di migrazione della classe di entità figlia. Riassumiamo tutto quanto sopra nella forma della seguente tabella al fine di facilitare il compito di sistematizzare e comprendere il materiale presentato. Anche in questa tabella includeremo informazioni su quali tipi di relazioni ("non più di uno a uno", "molti a uno", "molti a non più di uno") corrispondono a quali tipi di relazioni (completamente identificativi, non completamente identificativo, necessariamente non identificativo, non necessariamente non identificativo). Quindi, tra le classi di entità padre e figlio, viene stabilito il seguente tipo di relazione, a seconda del tipo di relazione.
Quindi, vediamo che in tutti i casi tranne l'ultimo, il riferimento non è vuoto (non nullo) → 1. Si noti la tendenza che all'estremità padre della connessione in tutti i casi tranne l'ultimo, la molteplicità è impostata su "uno". Questo perché il valore della chiave esterna nei casi di queste relazioni (cioè completamente identificative, non completamente identificanti e necessariamente non identificanti tipi di relazioni) deve necessariamente corrispondere (e per di più unico) valore della chiave primaria di la classe dell'entità madre. E in quest'ultimo caso, a causa del fatto che il valore della chiave esterna può essere uguale al valore Null (l'FK: flag di validità nulla), la molteplicità è impostata su "non più di uno" alla fine del genitore del relazione. Portiamo avanti la nostra analisi. All'estremità figlio della connessione, in tutti i casi, ad eccezione del primo, la molteplicità è impostata su "molti". Questo perché, a causa di identificazione incompleta, come nel secondo caso, (o assenza di tale identificazione, nel secondo e nel terzo caso), il valore della chiave primaria della classe dell'entità capogruppo può comparire ripetutamente tra i valori della chiave esterna della classe figlia. E nel primo caso, la relazione è completamente identificativa, quindi gli attributi della chiave primaria della classe di entità parent possono comparire una sola volta tra gli attributi delle chiavi della classe di entità child. Lezione n. 12. Relazioni tra classi di entità Quindi, tutti i concetti che abbiamo esaminato, vale a dire i diagrammi e i loro tipi, molteplicità e tipi di relazioni, nonché i tipi di migrazione chiave, ci aiuteranno ora a esaminare il materiale sulle stesse relazioni, ma già tra classi specifiche di entità. Tra esse, come vedremo, vi sono anche connessioni di vario genere. 1. Relazione gerarchica ricorsiva Il primo tipo di relazione tra classi di entità, che prenderemo in considerazione, è il cosiddetto relazione gerarchica ricorsiva. Generalmente ricorsione (o legame ricorsivo) è la relazione di una classe di entità con se stessa. A volte, per analogia con le situazioni della vita, tale connessione è anche chiamata "amo da pesca". Relazione gerarchica ricorsiva (o semplicemente ricorsione gerarchica) è qualsiasi relazione ricorsiva del tipo "al massimo uno a molti". La ricorsione gerarchica è più comunemente usata per memorizzare i dati in una struttura ad albero. Quando si specifica una relazione gerarchica ricorsiva, la chiave primaria della classe di entità padre (che in questo caso particolare funge anche da classe di entità figlio) deve essere migrata come chiave esterna agli attributi non chiave obbligatori della stessa classe di entità. Tutto ciò è necessario per mantenere l'integrità logica del concetto stesso di "ricorsione gerarchica". Pertanto, tenendo conto di tutto quanto sopra, possiamo concludere che una relazione ricorsiva gerarchica può essere solo non necessariamente non identificativo e nessun altro, perché se si utilizzasse qualsiasi altro tipo di relazione, i valori Null per la chiave esterna non sarebbero validi e la ricorsione sarebbe infinita. È anche importante ricordare che gli attributi non possono apparire due volte nella stessa classe di entità con lo stesso nome. Pertanto, agli attributi della chiave migrata deve essere assegnato il cosiddetto nome di ruolo. Pertanto, in una relazione gerarchica ricorsiva, gli attributi di un nodo vengono estesi con una chiave esterna che è un riferimento facoltativo alla chiave primaria del nodo che è il suo antenato immediato. Costruiamo una presentazione e diagrammi chiave che implementano la ricorsione gerarchica in un modello di dati relazionale e diamo un esempio di forma tabulare. Creiamo prima un diagramma di presentazione:
Ora costruiamo un diagramma chiave più dettagliato:
Considera un esempio che illustra chiaramente un tale tipo di relazione come una relazione gerarchica ricorsiva. Assumiamo la seguente classe di entità, che, come l'esempio precedente, è costituita dagli attributi "Ancestor Code" e "Node Code". Innanzitutto, mostriamo una rappresentazione tabulare di questa classe di entità:
Ora costruiamo un diagramma che rappresenta questa classe di entità. Per fare ciò selezioniamo dalla tabella tutte le informazioni necessarie per questo: l'antenato del nodo con il codice "uno" non esiste o non è definito, da ciò concludiamo che il nodo "uno" è un vertice. Lo stesso nodo "uno" è l'antenato dei nodi con il codice "due" e "tre". A sua volta, il nodo con codice "due" ha due figli: il nodo con codice "quattro" e il nodo con codice "cinque". E il nodo con il codice "tre" ha un solo figlio: il nodo con il codice "sei". Quindi, tenendo conto di quanto sopra, costruiamo una struttura ad albero che rifletta le informazioni sui dati contenuti nella tabella precedente:
Quindi, abbiamo visto che è davvero conveniente rappresentare le strutture ad albero utilizzando una relazione gerarchica ricorsiva. 2. Comunicazione ricorsiva in rete La connessione ricorsiva in rete delle classi di entità tra di loro è, per così dire, un analogo multidimensionale della connessione ricorsiva gerarchica che abbiamo già attraversato. Solo se la ricorsione gerarchica fosse definita come una relazione ricorsiva "al massimo uno-a-molti", allora ricorsione di rete rappresenta la stessa relazione ricorsiva, solo del tipo "molti-a-molti". A causa del fatto che molte classi di entità partecipano a questa connessione su entrambi i lati, si chiama connessione di rete. Come si può già intuire per analogia con la ricorsione gerarchica, i collegamenti di tipo ricorsione a rete sono progettati per rappresentare strutture dati a grafo (mentre i collegamenti gerarchici sono utilizzati, come ricordiamo, esclusivamente per l'implementazione di strutture ad albero). Ma poiché nella connessione del tipo di ricorsione di rete vengono specificate le connessioni del tipo "molti-a-molti", è impossibile fare a meno dei loro dettagli aggiuntivi. Pertanto, per affinare tutte le relazioni molti-a-molti nello schema, diventa necessario creare una nuova classe di entità indipendente che contenga tutti i riferimenti al genitore o al discendente della relazione Antenato-Discendente. Tale classe è generalmente chiamata classe di entità associativa. Nel nostro caso particolare (nei database da considerare nel nostro corso), l'entità associativa non ha attributi aggiuntivi propri e si chiama chiamando, perché nomina le relazioni Antenato-Discendente facendovi riferimento. Pertanto, la chiave primaria della classe di entità che rappresenta gli host deve essere migrata due volte alle classi di entità associative. In questa classe, le chiavi migrate insieme devono formare una chiave primaria composita. Da quanto sopra, possiamo concludere che stabilire collegamenti quando si utilizza la ricorsione di rete non dovrebbe essere completamente identificativo e nient'altro. Proprio come quando si utilizza una relazione ricorsiva gerarchica, quando si utilizza la ricorsione di rete come relazione, nessun attributo può apparire due volte nella stessa classe di entità con lo stesso nome. Pertanto, come l'ultima volta, è espressamente stabilito che tutti gli attributi della chiave di migrazione debbano ricevere il nome del ruolo. Per illustrare il funzionamento della comunicazione ricorsiva di rete, costruiamo una presentazione e diagrammi chiave che implementano la ricorsione di rete in un modello di dati relazionale. Iniziamo con un diagramma di presentazione:
Ora costruiamo un diagramma chiave più dettagliato:
Cosa vediamo qui? E vediamo che entrambe le connessioni in questo diagramma chiave sono connessioni “molti a uno”. Inoltre, la molteplicità “0... ∞” o la molteplicità “molti” è alla fine della connessione di fronte alla classe di denominazione delle entità. In effetti, ci sono molti collegamenti, ma tutti fanno riferimento ad un codice di nodo, che è la chiave primaria della classe di entità “Nodi”. E, infine, consideriamo un esempio che illustra il funzionamento di un tale tipo di connessione da parte di una classe di entità come ricorsione di rete. Diamo una rappresentazione tabulare di una classe di entità, così come una classe di entità di denominazione contenente informazioni sui collegamenti. Diamo un'occhiata a queste tabelle. Nodi:
Links:
In effetti, la rappresentazione di cui sopra è esaustiva: fornisce tutte le informazioni necessarie per riprodurre facilmente la struttura del grafo qui codificata. Ad esempio, possiamo vedere senza ostacoli che il nodo con il codice "uno" ha tre figli, rispettivamente, con i codici "due", "tre" e "quattro". Vediamo anche che i nodi con i codici "due" e "tre" non hanno affatto discendenti, e un nodo con il codice "quattro" ha (così come il nodo "uno") tre discendenti con i codici "uno", "due" e tre". Disegniamo un grafico dato dalle classi di entità sopra riportate:
Quindi, il grafico che abbiamo appena costruito sono i dati per i quali le classi di entità sono state collegate utilizzando una connessione di tipo ricorsione di rete. 3. Associazione Di tutti i tipi di connessioni incluse nella considerazione del nostro particolare corso di lezioni, solo due sono connessioni ricorsive. Siamo già riusciti a considerarli, si tratta rispettivamente di collegamenti ricorsivi gerarchici e di rete. Tutti gli altri tipi di relazioni che dobbiamo considerare non sono ricorsivi, ma, di regola, rappresentano una relazione di diverse classi di entità genitore e diverse classi di entità figlie. Inoltre, come si può intuire, le classi di entità padre e figlio ora non coincideranno mai (anzi, non si parla più di ricorsione). La connessione, di cui si parlerà in questa sezione della lezione, si chiama associazione e si riferisce appunto al tipo di connessioni non ricorsive. Quindi la connessione ha chiamato associazione, viene implementato come relazione tra più classi di entità padre e una classe di entità figlio. E allo stesso tempo, il che è curioso, questa relazione è descritta da relazioni di vario tipo. Vale anche la pena notare che ci può essere solo una classe di entità padre durante l'associazione, come nella ricorsione di rete, ma anche in una tale situazione, il numero di relazioni provenienti dalla classe di entità figlio deve essere almeno due. È interessante notare che nell'associazione, così come nella ricorsione di rete, esistono tipi speciali di classi di entità. Un esempio di tale classe è una classe di entità figlio. In effetti, nel caso generale, in un'associazione, viene chiamata una classe di entità figlio classe di entità associativa. Nel caso speciale in cui una classe di entità associativa non ha i propri attributi aggiuntivi e contiene solo attributi che migrano insieme alle chiavi primarie dalle classi di entità genitore, tale classe è chiamata classe di entità di denominazione. Come puoi vedere, c'è un'analogia quasi assoluta con il concetto di entità associative e nominative in una connessione ricorsiva di rete. Nella maggior parte dei casi, un'associazione viene utilizzata per perfezionare (risolvere) le relazioni molti-a-molti. Illustriamo questa affermazione. Ad esempio, ci viene fornito il seguente diagramma di presentazione, che descrive lo schema di ricezione di un determinato medico in un determinato ospedale:
Questo diagramma significa letteralmente che ci sono molti medici e molti pazienti in ospedale, e non c'è altra relazione e corrispondenza tra medici e pazienti. Quindi, ovviamente, con un tale database, non sarebbe mai chiaro all'amministrazione ospedaliera come organizzare appuntamenti con medici diversi per pazienti diversi. È chiaro che le relazioni molti-a-molti qui utilizzate hanno semplicemente bisogno di essere dettagliate per concretizzare il rapporto tra i vari medici e pazienti, in altre parole, per organizzare razionalmente il calendario degli appuntamenti di tutti i medici e i loro pazienti in l'ospedale. E ora costruiamo un diagramma chiave più dettagliato, in cui abbiamo già dettagliato tutte le relazioni molti-a-molti esistenti. Per fare questo, introdurremo opportunamente una nuova classe entità, la chiameremo "Receive", che fungerà da classe entità associativa (più avanti vedremo perché questa sarà una classe entità associativa, e non solo una classe di naming entità, di cui abbiamo parlato prima). Quindi il nostro diagramma chiave sarà simile a questo:
Quindi, ora puoi vedere chiaramente perché la nuova classe "Ricezione" non è una classe di entità di denominazione. Dopotutto, questa classe ha il suo attributo aggiuntivo "Data - Ora", quindi, secondo la definizione, la nuova classe "Ricezione" è una classe di entità associative. Questa classe "associa" tra loro le classi di entità "Medici" e "Paziente" per mezzo dell'ora in cui viene eseguito questo o quell'appuntamento, il che rende molto più conveniente lavorare con tale database. Pertanto, introducendo l'attributo "Data - Ora", abbiamo letteralmente organizzato l'orario di lavoro tanto necessario per vari medici. Vediamo anche che la chiave primaria esterna "Doctor's Code" della classe di entità "Reception" si riferisce alla chiave primaria con lo stesso nome della classe di entità "Doctors". Analogamente, la chiave primaria esterna "Codice paziente" della classe di entità "Ricezione" si riferisce alla chiave primaria con lo stesso nome nella classe di entità "Paziente". In questo caso, ovviamente, le classi di entità "Medici" e "Paziente" sono il genitore, e la classe di entità associativa "Accoglienza", a sua volta, è l'unica figlia. Possiamo vedere che la relazione molti-a-molti nel precedente diagramma di presentazione è ora completamente dettagliata. Invece della relazione molti-a-molti che vediamo nel diagramma di presentazione qui sopra, abbiamo due relazioni molti-a-uno. L'estremità figlio della prima relazione ha la molteplicità "molti", che letteralmente significa che la classe di entità "Accoglienza" ha molti medici (tutti in ospedale). E all'estremità genitrice di questa relazione c'è la molteplicità di "uno", cosa significa? Ciò significa che nella classe di entità "Reception", ciascuno dei codici disponibili di ogni particolare medico può ricorrere indefinitamente molte volte. Infatti, nell'orario in ospedale, il codice dello stesso medico ricorre molte volte, in giorni e orari diversi. Ed ecco lo stesso codice, ma già nella classe di entità "Doctors", può verificarsi una sola volta. Infatti, nell'elenco di tutti i medici ospedalieri (e la classe di entità "Medici" non è altro che tale elenco), il codice di ogni particolare medico può essere presente una sola volta. Una cosa simile accade con la relazione tra la classe genitore "Patient" e la classe figlia "Patient". Nell'elenco di tutti i pazienti ospedalieri (nella classe di entità "Pazienti"), il codice di ogni specifico paziente può comparire una sola volta. Ma d'altra parte, nel calendario degli appuntamenti (nella classe di entità "Ricezione"), ogni codice di un determinato paziente può comparire arbitrariamente molte volte. Ecco perché le molteplicità alle estremità del legame sono disposte in questo modo. Come esempio dell'implementazione di un'associazione in un modello di dati relazionale, costruiamo un modello che descrive il calendario degli incontri tra il cliente e l'appaltatore con la partecipazione facoltativa di consulenti. Non ci soffermeremo sul diagramma di presentazione, perché dobbiamo considerare la costruzione dei diagrammi in tutti i dettagli e il diagramma di presentazione non può fornire tale opportunità. Quindi, costruiamo un diagramma chiave che rifletta l'essenza del rapporto tra il cliente, l'appaltatore e il consulente.
Quindi, iniziamo un'analisi dettagliata del diagramma chiave sopra. In primo luogo, la classe "Graph" è una classe di entità associative, ma, come nell'esempio precedente, non è una classe di entità denominate, perché ha un attributo che non migra in essa insieme alle chiavi, ma è il suo proprio attributo. Questo è l'attributo "Data - Ora". In secondo luogo, vediamo che gli attributi della classe di entità figlio "Grafico" "Codice cliente", "Codice esecutore" e "Data - Ora" formano una chiave primaria composita di questa classe di entità. L'attributo "Advisor Code" è semplicemente una chiave esterna della classe di entità "Chart". Si noti che questo attributo ammette valori Null tra i suoi valori, perché in base alla condizione non è necessaria la presenza di un consulente alla riunione. Inoltre, in terzo luogo, notiamo che i primi due collegamenti (dei tre collegamenti disponibili) non sono completamente identificativi. Vale a dire, non completamente identificativo, perché la chiave di migrazione in entrambi i casi (chiavi primarie "Codice cliente" e "Codice esecutore") non forma completamente la chiave primaria della classe di entità "Grafico". Rimane infatti l'attributo "Date - Time", anch'esso parte della chiave primaria composita. Alle estremità di entrambi questi legami non completamente identificativi, sono segnate le molteplicità "uno" e "molti". Questo viene fatto per mostrare (come nell'esempio relativo a medici e pazienti) la differenza tra menzionare il codice del cliente o dell'esecutore in diverse classi di entità. Infatti, nella classe di entità "Graph", qualsiasi codice cliente o appaltatore può ricorrere tutte le volte che lo si desidera. Pertanto, a questo, bambino, termine della connessione c'è una molteplicità di "molti". E nella classe di entità "Clienti" o "Appaltatori", ciascuno dei codici del cliente o dell'appaltatore, rispettivamente, può verificarsi una e una sola volta, poiché queste classi di entità non sono nient'altro che un elenco completo di tutti i clienti e gli esecutori. Pertanto, in questa estremità genitore della connessione, c'è una molteplicità di "uno". E, infine, si noti che la terza relazione, ovvero la relazione della classe di entità "Graph" con la classe di entità "Consultants", non è necessariamente non identificativa. In questo caso, infatti, si tratta del trasferimento dell'attributo chiave "Codice Consulente" della classe entità "Consulenti" all'attributo non chiave dell'omonima classe entità "Grafico", ovvero la chiave primaria di la classe di entità "Consulenti" nella classe di entità "Grafico" non identifica già la chiave primaria di questa classe. Inoltre, come accennato in precedenza, l'attributo "Codice Consulente" consente valori Nulli, quindi qui è proprio la relazione non identificativa che viene utilizzata. Pertanto, l'attributo "Advisor Code" acquisisce lo stato di una chiave esterna e nient'altro. Prestiamo anche attenzione alla molteplicità di collegamenti posti alle estremità genitore e figlio di questo collegamento non completamente non identificativo. La sua estremità genitore ha una molteplicità di "non più di uno". Infatti, se ricordiamo la definizione di relazione non del tutto non identificativa, allora capiremo che l'attributo "Codice consulente" della classe entità "Grafico" non può corrispondere a più di un codice consulente dall'elenco di tutti i consulenti (che è la classe di entità "Consulenti"). E in generale, potrebbe risultare che non corrisponderà ad alcun codice consulente (ricorda la casella di spunta per l'ammissibilità dei valori NullCodice consulente: Null), perché secondo la condizione, la presenza di un consulente presso un l'incontro tra il cliente e l'appaltatore, in generale, non è necessario. 4. Generalizzazioni Un altro tipo di relazione tra classi di entità, che prenderemo in considerazione, è una relazione della forma generalizzazione. È anche un tipo di relazione non ricorsiva. Quindi una relazione come generalizzazione è implementato come una relazione di una classe di entità padre con diverse classi di entità figlio (in contrasto con la precedente relazione di associazione, che si occupava di diverse classi di entità padre e una classe di entità figlio). Quando si formulano regole di rappresentazione dei dati utilizzando la relazione di generalizzazione, va detto subito che questa relazione di una classe di entità padre e diverse classi di entità figlio è descritta identificando completamente le relazioni, cioè le relazioni categoriali. Ricordando la definizione di relazioni di identificazione completa, concludiamo che quando si utilizza la generalizzazione, ogni attributo della chiave primaria della classe dell'entità genitore viene trasferito alla chiave primaria delle classi dell'entità figlio, ovvero gli attributi della chiave primaria di migrazione della classe dell'entità genitore la classe di entità forma completamente le chiavi primarie di tutte le classi di entità figlie, le identificano. È curioso notare che la generalizzazione implementa il cosiddetto gerarchia di categorie o gerarchia ereditaria. In questo caso, la classe dell'entità padre definisce classe di entità generica, caratterizzato da attributi comuni alle entità di tutte le classi figlie o cosiddette entità categoriali cioè, una classe di entità padre è una generalizzazione letterale di tutte le sue classi di entità figlio. Come esempio dell'implementazione della generalizzazione in un modello di dati relazionale, costruiremo il seguente modello. Questo modello sarà basato sul concetto generalizzato di "Studenti" e descriverà i seguenti concetti categoriali (vale a dire, generalizzerà le seguenti classi di entità figlio): "Scolari", "Studenti" e "Studenti post-laurea". Quindi, costruiamo un diagramma chiave che rifletta l'essenza della relazione tra la classe di entità padre e le classi di entità figlio, descritte da una connessione di tipo Generalization.
Quindi cosa vediamo? In primo luogo, ciascuna delle relazioni di base (o da classi di entità, che è la stessa) "Scolari", "Studenti" e "Post-lauream" corrisponde ai propri attributi, come "Classe", "Corso" e "Anno di studio". " . Ciascuno di questi attributi caratterizza i membri della propria classe di entità. Vediamo anche che la chiave primaria della classe di entità padre "Students" migra a ciascuna classe di entità figlio e forma lì la chiave esterna primaria. Con l'aiuto di queste connessioni, possiamo determinare dal codice di qualsiasi studente il suo nome, cognome e patronimico, informazioni sulle quali non troveremo nelle corrispondenti classi di entità figlie stesse. In secondo luogo, poiché stiamo parlando di una relazione pienamente identificativa (o categoriale) delle classi di entità, presteremo attenzione alla molteplicità di relazioni tra la classe di entità genitore e le sue classi figlie. L'estremità padre di ciascuno di questi collegamenti ha una molteplicità di "uno" e ciascuna estremità figlio dei collegamenti ha una molteplicità di "al massimo uno". Se ricordiamo la definizione di una relazione pienamente identificativa delle classi di entità, diventa chiaro che il codice studente realmente univoco, che è la chiave primaria della classe di entità "Studenti", specifica al massimo un attributo con tale codice in ciascuna entità figlia classe "Studente", "Studenti" e Specializzati. Pertanto, tutti i legami hanno proprio tali molteplicità. Scriviamo un frammento degli operatori per la creazione delle relazioni di base "Scolari" e "Studenti" con la definizione di regole per il mantenimento dell'integrità referenziale del tipo a cascata. Quindi abbiamo: Crea tabella Alunni ... chiave primaria (codice studente) chiave esterna (Student ID) riferimenti Studenti (Student ID) sulla cascata di aggiornamento su elimina cascata Crea tabella Studenti ... chiave primaria (codice studente) chiave esterna (Student ID) riferimenti Studenti (Student ID) sulla cascata di aggiornamento su eliminare cascata; Quindi, vediamo che nella classe di entità figlio (o relazione) "Student" viene specificata una chiave esterna primaria che fa riferimento alla classe di entità padre (o relazione) "Students". La regola a cascata per il mantenimento dell'integrità referenziale determina che quando gli attributi della classe di entità padre "Studenti" vengono eliminati o aggiornati, gli attributi corrispondenti della relazione figlio "Studente" verranno automaticamente (a cascata) aggiornati o eliminati. Analogamente, quando gli attributi della classe di entità padre "Students" vengono eliminati o aggiornati, anche gli attributi corrispondenti della relazione figlio "Students" verranno automaticamente aggiornati o eliminati. Va notato che è questa regola di integrità referenziale che viene utilizzata qui, perché in questo contesto (l'elenco degli studenti) non è razionale vietare la cancellazione e l'aggiornamento delle informazioni, e anche assegnare un valore indefinito invece di informazioni reali . Facciamo ora un esempio delle classi di entità descritte nel diagramma precedente, presentato solo in forma tabellare. Quindi, abbiamo le seguenti tabelle di relazione: Alunni - relazione genitore che combina informazioni sugli attributi di tutte le altre relazioni:
studenti - relazione figlio:
studenti - rapporto di secondo figlio:
dottorandi - terzogenito:
Quindi, in effetti, vediamo che le classi figlie di entità non contengono informazioni sul cognome, nome e patronimico degli studenti, ad es. scolari, studenti e laureati. Queste informazioni possono essere ottenute solo tramite riferimenti alla classe dell'entità padre. Vediamo anche che diversi codici studente nella classe di entità "Students" possono corrispondere a diverse classi di entità figlio. Quindi, riguardo allo studente con il codice "1" Nikolai Zabotin, non si sa nulla nella relazione genitoriale, tranne il suo nome, e tutte le altre informazioni (chi è, uno scolaro, uno studente o uno studente laureato) possono essere trovate solo facendo riferimento alla corrispondente classe di entità figlio (determinata dal codice). Allo stesso modo, devi lavorare con il resto degli studenti, i cui codici sono specificati nella classe di entità padre "Studenti". 5. Composizione La relazione di classi entità del tipo composizione, come le due precedenti, non appartiene al tipo di relazione ricorsiva. composizione (o, come talvolta viene chiamato, aggregazione composita) è una relazione di una singola classe di entità padre con più classi di entità figlio, proprio come la relazione discussa in precedenza. Generalizzazione. Ma se la generalizzazione è stata definita come una relazione di classi di entità descritte identificando completamente le relazioni, allora la composizione, a sua volta, è descritta identificando in modo incompleto le relazioni, cioè durante la composizione, ogni attributo della chiave primaria della classe dell'entità genitore migra all'attributo chiave della classe di entità figlio. Allo stesso tempo, gli attributi della chiave di migrazione formano solo parzialmente la chiave primaria della classe di entità figlio. Quindi, con l'aggregazione composita (con composizione), la classe di entità genitore (o unità) è associato a più classi di entità figlio (o componenti). In questo caso, i componenti dell'aggregato (ovvero i componenti della classe di entità parent) fanno riferimento all'aggregato tramite una chiave esterna che fa parte della chiave primaria e, pertanto, non possono esistere al di fuori dell'aggregato. In generale, l'aggregazione composita è una forma avanzata di aggregazione semplice (di cui parleremo poco dopo). Una composizione (o aggregazione composita) è caratterizzata dal fatto che: 1) il riferimento all'assieme è coinvolto nell'identificazione dei componenti; 2) questi componenti non possono esistere al di fuori dell'aggregato. Un'aggregazione (una relazione che considereremo ulteriormente) con relazioni necessariamente non identificative, inoltre, non consente l'esistenza di componenti al di fuori dell'aggregato ed è quindi vicina nel significato all'implementazione dell'aggregazione composita sopra descritta. Costruiamo un diagramma chiave che descriva la relazione tra una classe di entità padre e diverse classi di entità figlio, ovvero descrivendo la relazione delle classi di entità del tipo di aggregazione composita. Lascia che questo sia un diagramma chiave che descriva la composizione degli edifici di un certo campus, inclusi gli edifici, le loro aule e gli ascensori. Quindi questo diagramma sarà simile a questo:
Quindi diamo un'occhiata al diagramma che abbiamo appena creato. Cosa ci vediamo? In primo luogo, vediamo che la relazione utilizzata in questa aggregazione composita è effettivamente identificativa e in effetti non completamente identificativa. Dopotutto, la chiave primaria della classe di entità padre "Edifici" è coinvolta nella formazione della chiave primaria delle classi di entità figlio "Pubblico" e "Ascensori", ma non la definisce completamente. La chiave primaria "Case No" della classe di entità padre viene migrata alle chiavi primarie esterne "Case No" di entrambe le classi figlio, ma, oltre a questa chiave migrata, entrambe le classi di entità figlio hanno anche la propria chiave primaria, rispettivamente "Audience No" e "Elevator No. ", ovvero le chiavi primarie composite delle classi di entità figlie sono attributi solo parzialmente formati della chiave primaria della classe di entità genitore. Ora diamo un'occhiata alla molteplicità dei collegamenti che collegano la classe genitore ed entrambe le classi figlie. Poiché si tratta di collegamenti non completamente identificativi, sono presenti le molteplicità: "uno" e "molti". La molteplicità "uno" è presente all'estremità genitore di entrambe le relazioni e simboleggia che nell'elenco di tutti i corpora disponibili (e la classe di entità "Corpus" è proprio un elenco di questo tipo), ogni numero può verificarsi solo una volta (e non più di quello) volte. E, a sua volta, tra gli attributi delle classi "Pubblico" e "Ascensori", ogni numero di edificio può comparire più volte, poiché ci sono più spettatori (o ascensori) che edifici, e in ogni edificio ci sono diversi auditorium e ascensori. Pertanto, elencando tutte le aule e gli ascensori, ripeteremo inevitabilmente i numeri degli edifici. E, infine, come nel caso del precedente tipo di connessione, annotiamo i frammenti degli operatori per la creazione di relazioni di base (o, che è la stessa cosa, classi di entità) "Audiences" e "Ascensori", e lo faremo farlo con la definizione di regole per mantenere l'integrità referenziale del tipo a cascata. Quindi questa affermazione sarebbe simile a questa: Crea segmenti di pubblico della tabella ... chiave primaria (numero del corpus, numero del pubblico) chiave esterna (numero caso) riferimenti Pattern (numero caso) sulla cascata di aggiornamento su elimina cascata Crea ascensori da tavolo ... chiave primaria (numero del caso, numero dell'ascensore) chiave esterna (numero caso) riferimenti Pattern (numero caso) sulla cascata di aggiornamento su eliminare cascata; Pertanto, abbiamo impostato tutte le chiavi primarie ed esterne necessarie delle classi di entità figlio. Abbiamo nuovamente preso la regola del mantenimento dell'integrità referenziale come cascata, poiché l'abbiamo già descritta come la più razionale. Daremo ora un esempio in forma tabellare di tutte le classi di entità che abbiamo appena considerato. Descriviamo quelle relazioni di base che abbiamo riflesso con l'aiuto di un diagramma sotto forma di tabelle e, per chiarezza, introdurremo lì una certa quantità di dati indicativi. alloggiamento La relazione padre è simile a questa:
Pubblico - classe di entità figlio:
Ascensori - la seconda classe di entità figlio della classe genitore "Enclosures":
Quindi, possiamo vedere come sono organizzate le informazioni per tutti gli edifici, le loro aule e gli ascensori in questo database, che può essere utilizzato da qualsiasi istituzione educativa nella vita reale. 6. Aggregazione L'aggregazione è l'ultimo tipo di relazione tra classi di entità che verrà considerato come parte del nostro corso. Inoltre non è ricorsivo e uno dei suoi due tipi ha un significato abbastanza vicino all'aggregazione composita considerata in precedenza. Così, aggregazione è la relazione di una classe di entità padre con più classi di entità figlio. In questo caso, la relazione può essere descritta da due tipi di relazioni: 1) link necessariamente non identificativi; 2) link facoltativi non identificativi. Ricordiamo che con relazioni necessariamente non identificative, alcuni attributi della chiave primaria della classe dell'entità genitore vengono trasferiti a un attributo non chiave della classe figlia e i valori Null per tutti gli attributi della chiave di migrazione sono proibiti. E con relazioni non necessariamente non identificative, la migrazione delle chiavi primarie avviene esattamente secondo lo stesso principio, ma sono consentiti valori Null per alcuni attributi della chiave migrante. Durante l'aggregazione, la classe di entità padre (o unità) è associato a più classi di entità figlio (o componenti). I componenti dell'aggregato (ovvero la classe dell'entità madre) fanno riferimento all'aggregato tramite una chiave esterna che non fa parte della chiave primaria, e quindi, nel caso relazioni non necessariamente non identificative, i componenti aggregati possono esistere al di fuori dell'aggregato. Nel caso di aggregazione con relazioni necessariamente non identificative, le componenti dell'aggregato non possono esistere al di fuori dell'aggregato e, in questo senso, l'aggregazione con relazioni necessariamente non identificative è prossima all'aggregazione composita. Ora che è diventato chiaro cos'è una relazione di tipo aggregato, costruiamo un diagramma chiave che descrive il funzionamento di questa relazione. Lascia che il nostro diagramma futuro descriva i componenti contrassegnati delle auto (vale a dire il motore e il telaio). Allo stesso tempo, assumeremo che la disattivazione dell'auto implichi la disattivazione del telaio insieme ad essa, ma non implichi la disattivazione simultanea del motore. Quindi il nostro diagramma chiave è simile a questo:
Quindi cosa vediamo in questo diagramma chiave? Innanzitutto, la relazione della classe di entità padre "Cars" con la classe di entità figlio "Engines" non è necessariamente non identificativa, perché l'attributo "car #" ammette valori nulli tra i suoi valori. A sua volta, questo attributo consente valori Null in quanto la disattivazione del motore, per condizione, non dipende dalla disattivazione dell'intero veicolo e, pertanto, non si verifica necessariamente durante la disattivazione di un'auto. Vediamo anche che la chiave primaria "Engine #" della classe di entità "Cars" migra nell'attributo non chiave "Engine #" della classe di entità "Engines". E allo stesso tempo, questo attributo acquisisce lo stato di una chiave esterna. E la chiave primaria in questa classe di entità Engines è l'attributo Engine Marker, che non fa riferimento ad alcun attributo della relazione padre. In secondo luogo, la relazione tra la classe di entità parent "Motors" e la classe di entità child "Chassis" è necessariamente una relazione non identificativa, perché l'attributo di chiave esterna "Car #" non ammette valori Null tra i suoi valori. Ciò, a sua volta, si verifica perché è noto dalla condizione che la disattivazione dell'auto implica la disattivazione simultanea obbligatoria del telaio. Qui, proprio come nel caso della relazione precedente, la chiave primaria della classe di entità parent "Motors" viene migrata all'attributo non chiave "Numero auto" della classe di entità child "Chassis". Allo stesso tempo, la chiave primaria di questa classe di entità è l'attributo "Chassis Marker", che non fa riferimento ad alcun attributo della relazione genitore "Motori". Vai avanti. Per una migliore assimilazione dell'argomento, riscriviamo i frammenti degli operatori per la creazione delle relazioni di base "Motori" e "Chassis" con la definizione di regole per il mantenimento dell'integrità referenziale. Crea tabella Motori ... chiave primaria (marcatore del motore) chiave esterna (n. veicolo) riferimenti Auto (n. veicolo) sulla cascata di aggiornamento su delete set Null Crea tavolo Chassis ... chiave primaria (marcatore telaio) chiave esterna (n. veicolo) riferimenti Auto (n. veicolo) sulla cascata di aggiornamento su eliminare cascata; Vediamo che abbiamo usato la stessa regola per mantenere l'integrità referenziale ovunque: cascata, poiché anche prima l'abbiamo riconosciuta come la più razionale di tutte. Tuttavia, questa volta abbiamo utilizzato (oltre alla regola a cascata) la regola di integrità referenziale set Null. Inoltre, l'abbiamo utilizzato nella seguente condizione: se viene eliminato un valore della chiave primaria "Numero auto" dalla classe dell'entità genitore "Automobili", allora il valore della chiave esterna "Numero auto" della relazione figlio "Motori" facendo riferimento ad esso verrà assegnato un valore Null . 7. Unificazione degli attributi Se, durante la migrazione delle chiavi primarie di una determinata classe di entità genitore, attributi di diverse classi genitore che coincidono nel significato entrano nella stessa classe figlia, allora questi attributi devono essere "uniti", cioè è necessario eseguire il così -chiamato unificazione degli attributi. Ad esempio, nel caso in cui un dipendente possa lavorare in un'organizzazione, essendo elencato in non più di un dipartimento, dopo aver unificato l'attributo "Codice organizzazione", otteniamo il seguente diagramma chiave:
Durante la migrazione della chiave primaria dalle classi di entità padre "Organizzazione" e "Dipartimenti" alla classe figlia "Dipendenti", l'attributo "ID organizzazione" entra nella classe di entità "Dipendenti". E due volte: 1) prima volta con pennarello PFK dalla classe di entità "Organizzazione" quando si stabilisce una relazione di identificazione incompleta; 2) e la seconda volta, con il marcatore FK con la condizione di accettare valori Null dalla classe di entità “Dipartimenti” quando si stabilisce una relazione non necessariamente non identificativa. Quando unificato, l'attributo "Organization ID" assume lo stato di un attributo di chiave primaria/esterna, assorbendo lo stato dell'attributo di chiave esterna. Costruiamo un nuovo diagramma chiave che dimostri il processo di unificazione stesso:
Pertanto, ha avuto luogo l'unificazione degli attributi. Lezione n. 13. Sistemi esperti e modello di produzione della conoscenza 1. Nomina dei sistemi esperti Per conoscere un concetto così nuovo per noi come sistemi esperti noi, per cominciare, ripercorreremo la storia della creazione e dello sviluppo della direzione dei "sistemi esperti", quindi definiremo il concetto stesso di sistemi esperti. All'inizio degli anni '80. XNUMX ° secolo nella ricerca sulla creazione dell'intelligenza artificiale si è formata una nuova direzione indipendente, chiamata sistemi esperti. Lo scopo di questa nuova ricerca sui sistemi esperti è quello di sviluppare programmi speciali progettati per risolvere specifici tipi di problemi. Qual è questo tipo speciale di problema che ha richiesto la creazione di un'intera nuova ingegneria della conoscenza? Questo tipo speciale di attività può includere attività di qualsiasi area tematica. La cosa principale che li distingue dai problemi ordinari è che sembra essere un compito molto difficile per un esperto umano risolverli. Quindi il primo cosiddetto sistema esperto (dove il ruolo di un esperto non era più una persona, ma una macchina), e il sistema esperto riceve risultati che non sono inferiori in qualità ed efficienza alle soluzioni ottenute da una persona comune - un esperto. I risultati del lavoro dei sistemi esperti possono essere spiegati all'utente ad un livello molto alto. Questa qualità dei sistemi esperti è assicurata dalla loro capacità di ragionare sulle proprie conoscenze e conclusioni. I sistemi esperti possono reintegrare le proprie conoscenze nel processo di interazione con un esperto. Pertanto, possono essere messi con piena fiducia alla pari con un'intelligenza artificiale completamente formata. I ricercatori nel campo dei sistemi esperti per il nome della loro disciplina usano spesso anche il termine precedentemente citato "ingegneria della conoscenza", introdotto dallo scienziato tedesco E. Feigenbaum come "portare i principi e gli strumenti della ricerca dal campo dell'intelligenza artificiale nella risoluzione difficili problemi applicati che richiedono conoscenze specialistiche." Tuttavia, il successo commerciale delle società di sviluppo non è arrivato immediatamente. Per un quarto di secolo dal 1960 al 1985. I successi dell'intelligenza artificiale sono stati principalmente legati agli sviluppi della ricerca. Tuttavia, a partire dal 1985 circa e su vasta scala dal 1987 al 1990. sistemi esperti sono stati utilizzati attivamente in applicazioni commerciali. I meriti dei sistemi esperti sono piuttosto ampi e sono i seguenti: 1) la tecnologia dei sistemi esperti amplia notevolmente la gamma di compiti praticamente significativi risolti su personal computer, la cui soluzione apporta notevoli vantaggi economici e semplifica notevolmente tutti i processi correlati; 2) la tecnologia dei sistemi esperti è uno degli strumenti più importanti per risolvere i problemi globali della programmazione tradizionale, come la durata, la qualità e, di conseguenza, l'elevato costo di sviluppo di applicazioni complesse, per cui l'effetto economico è stato notevolmente ridotto ; 3) vi è un elevato costo di funzionamento e manutenzione di sistemi complessi, che spesso supera di parecchie volte il costo dello sviluppo stesso, nonché un basso livello di riutilizzabilità dei programmi, ecc.; 4) la combinazione della tecnologia dei sistemi esperti con la tecnologia di programmazione tradizionale aggiunge nuove qualità ai prodotti software fornendo, in primo luogo, la modifica dinamica delle applicazioni da parte di un utente ordinario e non da parte di un programmatore; in secondo luogo, maggiore "trasparenza" dell'applicazione, migliore grafica, interfaccia e interazione dei sistemi esperti. Secondo gli utenti ordinari e i maggiori esperti, nel prossimo futuro, i sistemi esperti troveranno le seguenti applicazioni: 1) i sistemi esperti svolgeranno un ruolo di primo piano in tutte le fasi di progettazione, sviluppo, produzione, distribuzione, debugging, controllo ed erogazione dei servizi; 2) la tecnologia dei sistemi esperti, che ha ricevuto un'ampia distribuzione commerciale, fornirà una svolta rivoluzionaria nell'integrazione di applicazioni da moduli interagenti intelligenti già pronti. In generale, i sistemi esperti sono progettati per i cosiddetti compiti informali, vale a dire, i sistemi esperti non rifiutano e non sostituiscono l'approccio tradizionale allo sviluppo del programma incentrato sulla risoluzione di problemi formalizzati, ma li completano, ampliando così notevolmente le possibilità. Questo è esattamente ciò che un semplice esperto umano non può fare. Tali compiti complessi non formalizzati sono caratterizzati da: 1) errore, inesattezza, ambiguità, nonché incompletezza e incoerenza dei dati di origine; 2) errore, ambiguità, imprecisione, incompletezza e incoerenza della conoscenza dell'area problematica e del problema da risolvere; 3) grande dimensione dello spazio delle soluzioni di un problema specifico; 4) variabilità dinamica dei dati e delle conoscenze direttamente nel processo di risoluzione di un problema così informale. I sistemi esperti si basano principalmente sulla ricerca euristica di una soluzione, e non sull'esecuzione di un algoritmo noto. Questo è uno dei principali vantaggi della tecnologia dei sistemi esperti rispetto all'approccio tradizionale allo sviluppo del software. Questo è ciò che consente loro di far fronte così bene ai compiti loro assegnati. La tecnologia dei sistemi esperti viene utilizzata per risolvere una varietà di problemi. Elenchiamo il principale di questi compiti. 1. Interpretazione. I sistemi esperti che eseguono l'interpretazione utilizzano molto spesso le letture di vari strumenti per descrivere lo stato delle cose. I sistemi interpretativi esperti sono in grado di elaborare una varietà di tipi di informazioni. Un esempio è l'uso dei dati dell'analisi spettrale e dei cambiamenti nelle caratteristiche delle sostanze per determinarne la composizione e le proprietà. Un altro esempio è l'interpretazione delle letture degli strumenti di misura nel locale caldaia per descrivere lo stato delle caldaie e dell'acqua in esse contenuta. I sistemi interpretativi molto spesso trattano direttamente le indicazioni. A questo proposito, sorgono difficoltà che altri tipi di sistemi non hanno. Quali sono queste difficoltà? Queste difficoltà sorgono a causa del fatto che i sistemi esperti devono interpretare informazioni intasate, superflue, incomplete, inaffidabili o errate. Pertanto, gli errori o un aumento significativo dell'elaborazione dei dati sono inevitabili. 2. Predizione. I sistemi esperti che effettuano una previsione di qualcosa determinano le condizioni probabilistiche di determinate situazioni. Ne sono un esempio la previsione dei danni causati al raccolto del grano da condizioni meteorologiche avverse, la valutazione della domanda di gas nel mercato mondiale, le previsioni meteorologiche secondo le stazioni meteorologiche. I sistemi di previsione a volte utilizzano la modellazione, ovvero programmi che visualizzano alcune relazioni nel mondo reale per ricrearle in un ambiente di programmazione e quindi progettare situazioni che possono sorgere con determinati dati iniziali. 3. Diagnostica di vari dispositivi. I sistemi esperti eseguono tale diagnostica utilizzando le descrizioni di qualsiasi situazione, comportamento o dati sulla struttura dei vari componenti al fine di determinare le possibili cause di un malfunzionamento del sistema diagnosticabile. Esempi sono l'istituzione delle circostanze della malattia dai sintomi che si osservano nei pazienti (in medicina); identificazione di guasti nei circuiti elettronici e identificazione di componenti difettosi nei meccanismi di vari dispositivi. I sistemi diagnostici sono molto spesso assistenti che non solo effettuano una diagnosi, ma aiutano anche nella risoluzione dei problemi. In tali casi, questi sistemi possono interagire con l'utente per assistere nella risoluzione dei problemi e quindi fornire un elenco di azioni necessarie per risolverli. Attualmente, molti sistemi diagnostici vengono sviluppati come applicazioni per l'ingegneria e i sistemi informatici. 4. Pianificazione di vari eventi. Sistemi esperti progettati per la pianificazione progettano varie operazioni. I sistemi predeterminano una sequenza quasi completa di azioni prima che inizi la loro implementazione. Esempi di tale pianificazione degli eventi sono la creazione di piani per operazioni militari, sia difensive che offensive, predeterminate per un certo periodo al fine di ottenere un vantaggio sulle forze nemiche. 5. disegno. I sistemi esperti che eseguono la progettazione sviluppano varie forme di oggetti, tenendo conto delle circostanze prevalenti e di tutti i fattori correlati. Un esempio è l'ingegneria genetica. 6. Controllo. I sistemi esperti che esercitano il controllo confrontano il comportamento attuale del sistema con il suo comportamento previsto. L'osservazione di sistemi esperti rileva un comportamento controllato che conferma le loro aspettative rispetto al comportamento normale o la loro assunzione di potenziali deviazioni. I sistemi esperti di controllo, per loro stessa natura, devono lavorare in tempo reale e implementare un'interpretazione dipendente dal tempo e dal contesto del comportamento dell'oggetto controllato. Gli esempi includono il monitoraggio delle letture degli strumenti di misura nei reattori nucleari al fine di rilevare le emergenze o valutare i dati diagnostici dei pazienti nell'unità di terapia intensiva. 7. Управление. Dopotutto, è risaputo che i sistemi esperti che esercitano il controllo gestiscono in modo molto efficace il comportamento del sistema nel suo insieme. Un esempio è la gestione di vari settori, nonché la distribuzione di sistemi informatici. I sistemi esperti di controllo devono includere componenti di osservazione per controllare il comportamento di un oggetto per un lungo periodo di tempo, ma possono anche aver bisogno di altri componenti dai tipi di compiti già analizzati. I sistemi esperti sono utilizzati in vari campi: transazioni finanziarie, industria petrolifera e del gas. La tecnologia dei sistemi esperti può essere applicata anche nell'energia, nei trasporti, nell'industria farmaceutica, nello sviluppo spaziale, nelle industrie metallurgiche e minerarie, nella chimica e in molti altri settori. 2. Struttura dei sistemi esperti Lo sviluppo di sistemi esperti presenta una serie di differenze significative rispetto allo sviluppo di un prodotto software convenzionale. L'esperienza nella creazione di sistemi esperti ha dimostrato che l'uso della metodologia adottata nella programmazione tradizionale nel loro sviluppo aumenta notevolmente la quantità di tempo speso per la creazione di sistemi esperti o addirittura porta a un risultato negativo. I sistemi esperti sono generalmente suddivisi in statico и dinamico. Innanzitutto, considera un sistema esperto statico. standard sistema esperto statico è costituito dai seguenti componenti principali: 1) memoria di lavoro, detta anche database; 2) basi di conoscenza; 3) un risolutore, detto anche interprete; 4) componenti dell'acquisizione della conoscenza; 5) componente esplicativa; 6) componente di dialogo. Consideriamo ora ogni componente in modo più dettagliato. memoria di lavoro (per assoluta analogia con il lavoro, cioè la RAM del computer) è progettato per ricevere e memorizzare i dati iniziali e intermedi dell'attività da risolvere al momento attuale. База знаний è progettato per memorizzare dati a lungo termine che descrivono un'area tematica specifica e regole che descrivono la trasformazione razionale dei dati in quest'area del problema da risolvere. Risolutorechiamato anche interprete, funziona come segue: utilizzando i dati iniziali della memoria di lavoro e i dati a lungo termine della base di conoscenza, forma le regole, la cui applicazione ai dati iniziali porta alla soluzione del problema. In una parola, "risolve" davvero il problema che gli si poneva; Componente di acquisizione della conoscenza automatizza il processo di riempimento del sistema esperto con conoscenze specialistiche, ad es. è questo componente che fornisce alla base di conoscenza tutte le informazioni necessarie da questa particolare area tematica. Spiega il componente spiega come il sistema ha ottenuto una soluzione a questo problema, o perché non ha ricevuto questa soluzione, e quale conoscenza ha utilizzato per farlo. In altre parole, il componente di spiegazione genera un rapporto sullo stato di avanzamento. Questo componente è molto importante nell'intero sistema esperto, poiché facilita notevolmente il test del sistema da parte di un esperto, inoltre aumenta la fiducia dell'utente nel risultato ottenuto e, quindi, accelera il processo di sviluppo. Componente di dialogo serve a fornire un'interfaccia utente amichevole sia nel corso della risoluzione di un problema che nel processo di acquisizione delle conoscenze e dichiarazione dei risultati del lavoro. Ora che sappiamo di quali componenti è generalmente composto un sistema esperto statistico, costruiamo un diagramma che rispecchi la struttura di tale sistema esperto. Sembra così:
I sistemi esperti statici sono spesso utilizzati in applicazioni tecniche in cui è possibile non tenere conto dei cambiamenti nell'ambiente che si verificano durante la soluzione di un problema. È curioso sapere che i primi sistemi esperti che hanno ricevuto applicazione pratica erano proprio statici. Quindi, su questo termineremo per ora la considerazione del sistema esperto statistico, passiamo all'analisi del sistema esperto dinamico. Sfortunatamente, il programma del nostro corso non include una considerazione dettagliata di questo sistema esperto, quindi ci limiteremo ad analizzare solo le differenze più elementari tra un sistema esperto dinamico e uno statico. A differenza di un sistema esperto statico, la struttura sistema esperto dinamico Inoltre, vengono introdotti i seguenti due componenti: 1) un sottosistema per modellare il mondo esterno; 2) un sottosistema di relazioni con l'ambiente esterno. Sottosistema di relazioni con l'ambiente esterno Crea solo connessioni con il mondo esterno. Lo fa attraverso un sistema di sensori e controller speciali. Inoltre, alcuni componenti tradizionali di un sistema esperto statico subiscono modifiche significative al fine di riflettere la logica temporale degli eventi che si verificano attualmente nell'ambiente. Questa è la principale differenza tra sistemi esperti statici e dinamici. Un esempio di sistema esperto dinamico è la gestione della produzione di vari farmaci nell'industria farmaceutica. 3. Partecipanti allo sviluppo di sistemi esperti Rappresentanti di varie specialità sono coinvolti nello sviluppo di sistemi esperti. Molto spesso, un sistema esperto specifico viene sviluppato da tre specialisti. Questo di solito è: 1) esperto; 2) ingegnere della conoscenza; 3) un programmatore per lo sviluppo di strumenti. Cerchiamo di spiegare le responsabilità di ciascuno degli specialisti qui elencati. Esperto è uno specialista nell'area tematica, i cui compiti saranno risolti con l'aiuto di questo particolare sistema esperto in fase di sviluppo. Ingegnere della conoscenza è uno specialista nello sviluppo di un sistema esperto direttamente. Le tecnologie e i metodi da lui utilizzati sono chiamati tecnologie e metodi di ingegneria della conoscenza. Un ingegnere della conoscenza aiuta un esperto a identificare da tutte le informazioni nell'area tematica le informazioni necessarie per lavorare con un particolare sistema esperto in fase di sviluppo e quindi a strutturarlo. È curioso che l'assenza di ingegneri della conoscenza tra i partecipanti allo sviluppo, ovvero la loro sostituzione con programmatori, porti al fallimento dell'intero progetto di creazione di uno specifico sistema esperto, oppure aumenti notevolmente i tempi per il suo sviluppo. E, infine, programmatore sviluppa strumenti (se gli strumenti sono di nuova concezione) progettati per accelerare lo sviluppo di sistemi esperti. Questi strumenti contengono, al limite, tutti i principali componenti di un sistema esperto; il programmatore inoltre interfaccia i suoi strumenti con l'ambiente in cui verrà utilizzato. 4. Modalità di funzionamento dei sistemi esperti Il sistema esperto opera in due modalità principali: 1) nella modalità di acquisizione della conoscenza; 2) nella modalità di risoluzione del problema (detta anche modalità delle consultazioni, o modalità di utilizzo del sistema esperto). Questo è logico e comprensibile, perché prima è necessario, per così dire, caricare il sistema esperto con informazioni dall'area tematica in cui deve lavorare, questa è la modalità di "addestramento" del sistema esperto, la modalità in cui riceve conoscenza. E dopo aver caricato tutte le informazioni necessarie per il lavoro, segue il lavoro stesso. Il sistema esperto diventa pronto per il funzionamento e può essere utilizzato per consulenze o per risolvere eventuali problemi. Consideriamo più in dettaglio modalità di acquisizione della conoscenza. Nella modalità di acquisizione della conoscenza, il lavoro con il sistema esperto viene svolto da un esperto tramite un ingegnere della conoscenza. In questa modalità, l'esperto, utilizzando la componente di acquisizione della conoscenza, riempie il sistema di conoscenza (dati), che, a sua volta, consente al sistema di risolvere i problemi di quest'area tematica nella modalità di soluzione senza la partecipazione di un esperto. Va notato che la modalità di acquisizione della conoscenza nell'approccio tradizionale allo sviluppo del programma corrisponde alle fasi di algoritmizzazione, programmazione e debug eseguite direttamente dal programmatore. Ne consegue che, contrariamente all'approccio tradizionale, nel caso dei sistemi esperti, lo sviluppo dei programmi non viene effettuato da un programmatore, ma da un esperto, ovviamente, con l'ausilio di sistemi esperti, ovvero, in generale , una persona che non conosce la programmazione. E ora consideriamo la seconda modalità di funzionamento del sistema esperto, ovvero modalità di risoluzione dei problemi. Nella modalità di problem solving (o cosiddetta modalità di consultazione), la comunicazione con i sistemi esperti è effettuata direttamente dall'utente finale, che è interessato al risultato finale del lavoro e talvolta al metodo per ottenerlo. Va notato che, a seconda dello scopo del sistema esperto, l'utente non deve essere un esperto in questa area problematica. In questo caso si rivolge a sistemi esperti per il risultato, non avendo conoscenze sufficienti per ottenere risultati. Oppure, l'utente può ancora avere un livello di conoscenza sufficiente per raggiungere da solo il risultato desiderato. In questo caso, l'utente può ottenere il risultato da solo, ma si rivolge a sistemi esperti per accelerare il processo di ottenimento del risultato o per assegnare un lavoro monotono ai sistemi esperti. In modalità di consultazione, i dati relativi al compito dell'utente, dopo essere stati elaborati dal componente di dialogo, entrano nella memoria di lavoro. Il risolutore, sulla base dei dati di input dalla memoria di lavoro, dei dati generali sull'area del problema e delle regole del database, genera una soluzione al problema. Quando risolvono un problema, i sistemi esperti non solo eseguono la sequenza prescritta di un'operazione specifica, ma la formano anche preliminarmente. Questo viene fatto nel caso in cui la reazione del sistema non sia del tutto chiara per l'utente. In questa situazione, l'utente può richiedere una spiegazione del motivo per cui questo sistema esperto pone una particolare domanda o perché questo sistema esperto non può eseguire questa operazione, come si ottiene questo o quel risultato fornito da questo sistema esperto. 5. Modello di produzione della conoscenza Al suo interno, modelli di produzione della conoscenza vicino ai modelli logici, che consente di organizzare procedure molto efficaci per l'inferenza logica dei dati. Questo è da un lato. Tuttavia, d'altra parte, se consideriamo i modelli di produzione della conoscenza rispetto ai modelli logici, i primi mostrano più chiaramente la conoscenza, il che è un vantaggio indiscutibile. Pertanto, indubbiamente, il modello di produzione della conoscenza è uno dei principali mezzi di rappresentazione della conoscenza nei sistemi di intelligenza artificiale. Quindi, iniziamo una considerazione dettagliata del concetto di un modello di produzione della conoscenza. Il modello tradizionale di produzione della conoscenza include le seguenti componenti di base: 1) un insieme di regole (o produzioni) che rappresentano la base conoscitiva del sistema produttivo; 2) memoria di lavoro, che memorizza i fatti originali, nonché i fatti derivati dai fatti originali utilizzando il meccanismo di inferenza; 3) lo stesso meccanismo di inferenza logica, che consente, dai fatti disponibili, secondo le regole di inferenza esistenti, di derivare nuovi fatti. E, curiosamente, il numero di tali operazioni può essere infinito. Ogni regola che rappresenta la base conoscitiva del sistema produttivo contiene una parte condizionale e una finale. La parte condizionale della regola contiene un singolo fatto o più fatti collegati da una congiunzione. La parte finale della regola contiene fatti che devono essere reintegrati con la memoria di lavoro se la parte condizionale della regola è vera. Se proviamo a rappresentare schematicamente il modello di produzione della conoscenza, allora la produzione è intesa come espressione della seguente forma: (i) Q; P; LA→B; N; Qui io è il nome del modello di produzione della conoscenza o il suo numero di serie, con l'aiuto del quale questa produzione si distingue dall'intero insieme di modelli di produzione, ricevendo una sorta di identificazione. Alcune unità lessicali che riflettono l'essenza di questo prodotto possono fungere da nome. Nominiamo infatti i prodotti per una migliore percezione da parte della coscienza, al fine di semplificare la ricerca del prodotto desiderato dall'elenco. Facciamo un semplice esempio: comprare un taccuino" o "un set di matite colorate. Ovviamente ogni prodotto viene solitamente indicato con parole adatte al momento. In altre parole, chiama il pane al pane. Vai avanti. L'elemento Q caratterizza l'ambito di questo particolare modello di produzione della conoscenza. Tali sfere sono facilmente distinguibili nella mente umana, quindi, di regola, non ci sono difficoltà con la definizione di questo elemento. Facciamo un esempio. Consideriamo la seguente situazione: diciamo che in un'area della nostra coscienza è immagazzinata la conoscenza di come cucinare il cibo, in un'altra come mettersi al lavoro, nella terza come far funzionare correttamente la lavatrice. Una simile divisione è presente anche nella memoria del modello di produzione della conoscenza. Questa divisione della conoscenza in aree separate può far risparmiare in modo significativo il tempo speso per la ricerca di alcuni specifici modelli di produzione della conoscenza che sono necessari al momento, semplificando così notevolmente il processo di lavoro con essi. Naturalmente, l'elemento principale della produzione è il suo cosiddetto nucleo, che nella nostra formula precedente era indicato come A → B. Questa formula può essere interpretata come "se la condizione A è soddisfatta, allora l'azione B dovrebbe essere eseguita". Se abbiamo a che fare con costrutti del kernel più complessi, sul lato destro è consentita la seguente scelta alternativa: "se la condizione A è soddisfatta, allora l'azione B dovrebbe essere eseguita1, altrimenti dovresti eseguire l'azione B2". Tuttavia, l'interpretazione del nucleo del modello di produzione della conoscenza può essere diversa e dipendere da ciò che sarà a sinistra ea destra del segno successivo "→". Con una delle interpretazioni del nucleo del modello di produzione della conoscenza, il sequente può essere interpretato nel senso logico usuale, cioè come un segno della conseguenza logica dell'azione B dalla vera condizione A. Tuttavia, sono possibili anche altre interpretazioni del nucleo del modello di produzione della conoscenza. Quindi, ad esempio, A può descrivere una condizione, il cui adempimento è necessario affinché un'azione B venga eseguita. Successivamente, consideriamo un elemento del modello di produzione della conoscenza R. elemento Р è definita come condizione per l'applicabilità del core di prodotto. Se la condizione P è vera, viene attivato il core di produzione. Diversamente, se la condizione P non è soddisfatta, cioè è falsa, il nucleo non può essere attivato. Come esempio illustrativo, si consideri il seguente modello di produzione della conoscenza: "Disponibilità di denaro"; "Se vuoi comprare la cosa A, allora dovresti pagarne il costo al cassiere e presentare l'assegno al venditore." Guardiamo, se la condizione P è vera, cioè l'acquisto è pagato e l'assegno è presentato, allora il nucleo è attivato. Acquisto completato. Se in questo modello di produzione della conoscenza la condizione di applicabilità del nucleo è falsa, cioè se non ci sono soldi, allora è impossibile applicare il nucleo del modello di produzione della conoscenza, ed esso non si attiva. E infine vai all'elemento N. L'elemento N è chiamato la postcondizione del modello di dati di produzione. La postcondizione definisce le azioni e le procedure che devono essere eseguite dopo l'implementazione del nucleo di produzione. Per una migliore percezione, facciamo un semplice esempio: dopo aver acquistato una cosa in un negozio, è necessario ridurre di uno il numero di cose di questo tipo nell'inventario delle merci di questo negozio, ad es. , il nucleo viene venduto), quindi il negozio ha un'unità di questo particolare prodotto in meno. Da qui la postcondizione "Cancellare l'unità dell'articolo acquistato". Riassumendo, possiamo affermare che la rappresentazione della conoscenza come un insieme di regole, cioè attraverso l'utilizzo di un modello di produzione della conoscenza, presenta i seguenti vantaggi: 1) è la facilità di creare e comprendere singole regole; 2) è la semplicità del meccanismo di scelta logica. Tuttavia, nella rappresentazione della conoscenza sotto forma di un insieme di regole, ci sono anche degli svantaggi che ancora limitano l'ambito e la frequenza di applicazione dei modelli di conoscenza della produzione. Il principale di tali svantaggi è l'ambiguità delle relazioni reciproche tra le regole che costituiscono uno specifico modello di produzione della conoscenza, nonché le regole di scelta logica. Note 1. Il carattere sottolineato nell'edizione stampata del libro corrisponde a Italico grassetto in questa versione (elettronica) del libro. (Circa. e. ed.)
▪ Psicologia del lavoro. Note di lettura ▪ Storia della cultura. Note di lettura
Pelle artificiale per l'emulazione del tocco
15.04.2024 Lettiera per gatti Petgugu Global
15.04.2024 L'attrattiva degli uomini premurosi
14.04.2024
▪ Scoperto un nuovo modo per conservare le vitamine negli alimenti ▪ Treno elettrico con una velocità di 369 km/h
▪ sezione del sito Esperimenti di Fisica. Selezione di articoli ▪ articolo Arrampicati sulla furia. Espressione popolare ▪ articolo Insufficienza respiratoria nei bambini. Groppa. Assistenza sanitaria
Homepage | Biblioteca | Articoli | Mappa del sito | Recensioni del sito
www.diagram.com.ua |



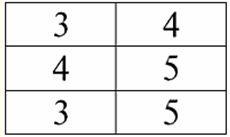
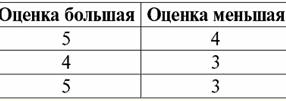

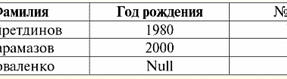

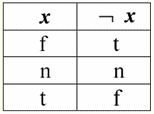

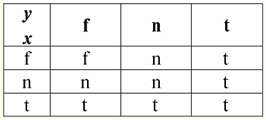
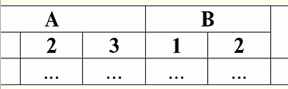


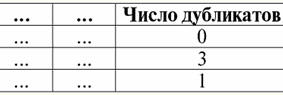
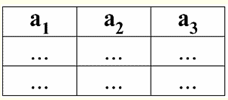






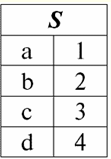
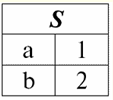


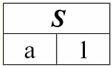
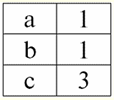

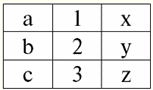









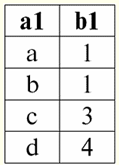






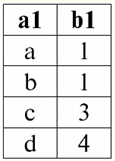



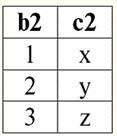

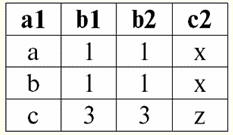




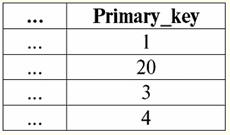

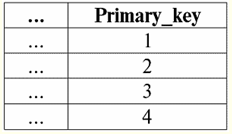

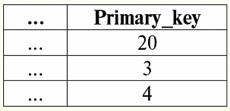
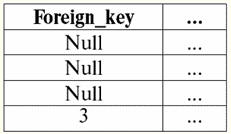

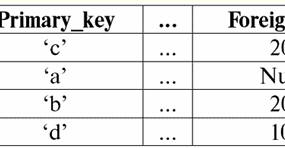








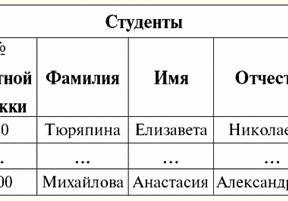
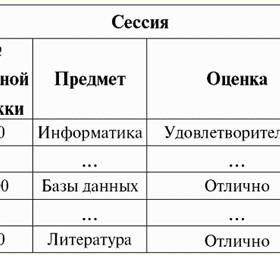



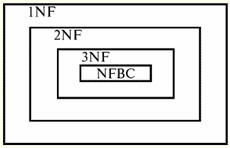

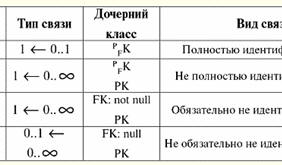









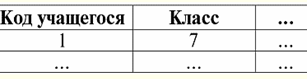
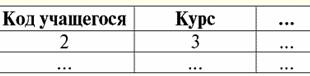

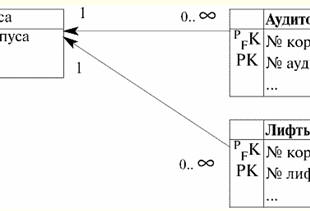




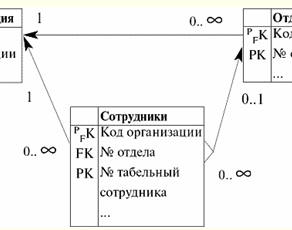
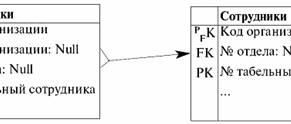
 Vedi altri articoli sezione
Vedi altri articoli sezione 